- 1【MySQL】GROUP BY分组子句与联合查询基本操作_mysql group by 子查询全部信息
- 22024年前端最全前端大屏适配几种方案_前端大屏适配方案,2024年最新Web前端高级面试framework
- 3AI绘画ComfyUI工作流安装教程,新手入门安装部署教程_comfyui 安装
- 4常见8种数据结构
- 5Visual Studio 安装教程 超级详细 (亲测有效)_visual studio安装教程
- 6小乌龟删除本地或远程分支_小乌龟怎么批量删除分支
- 7全栈性能测试_全栈测试
- 8自动化测试selenium
- 9使用PyTorch和Flower 进行联邦学习_cifar数据集联邦学习
- 10Java 链表 (LinkedList)(详细)_linkedlist的类型
GenerationMixin类
赞
踩
1. GenerationMixin 类
这个类的源码中给了这么一个博客链接: https://huggingface.co/blog/how-to-generate 。对生成的理解大有帮助。我总结一下这个博客的内容如下:
- 自回归的假设是:整条句子的概率其实就是条件概率的乘积
- 生成的句子的长度其实是动态决定的。
- 文中列出了几种解码策略:
Greedy SearchBeam SearchTop-K samplingtop-p sampling
在贪心策略和束搜索中,会导致一个重复生成的问题。也就是下面这样:
Output:
I enjoy walking with my cute dog, but I’m not sure if I’ll ever be able to walk with my dog. I’m not sure if I’ll ever be able to walk with my dog.
I’m not sure if I’ll…
解决这个重复生成的问题,就是采用n-grams 的策略。就是让生成的文本中,限制ngrams 重复出现的次数。
beam search 不适合开放域生成。这个文章讲的也是比较浅显,但是易懂~

今天在用Bart做生成的时候,发现model.generate() 方法,发现原来是PreTrainedModel 这个基类继承了GenerationMixin,而这个类则是用于生成方法的基类。下面看看源码的执行步骤:
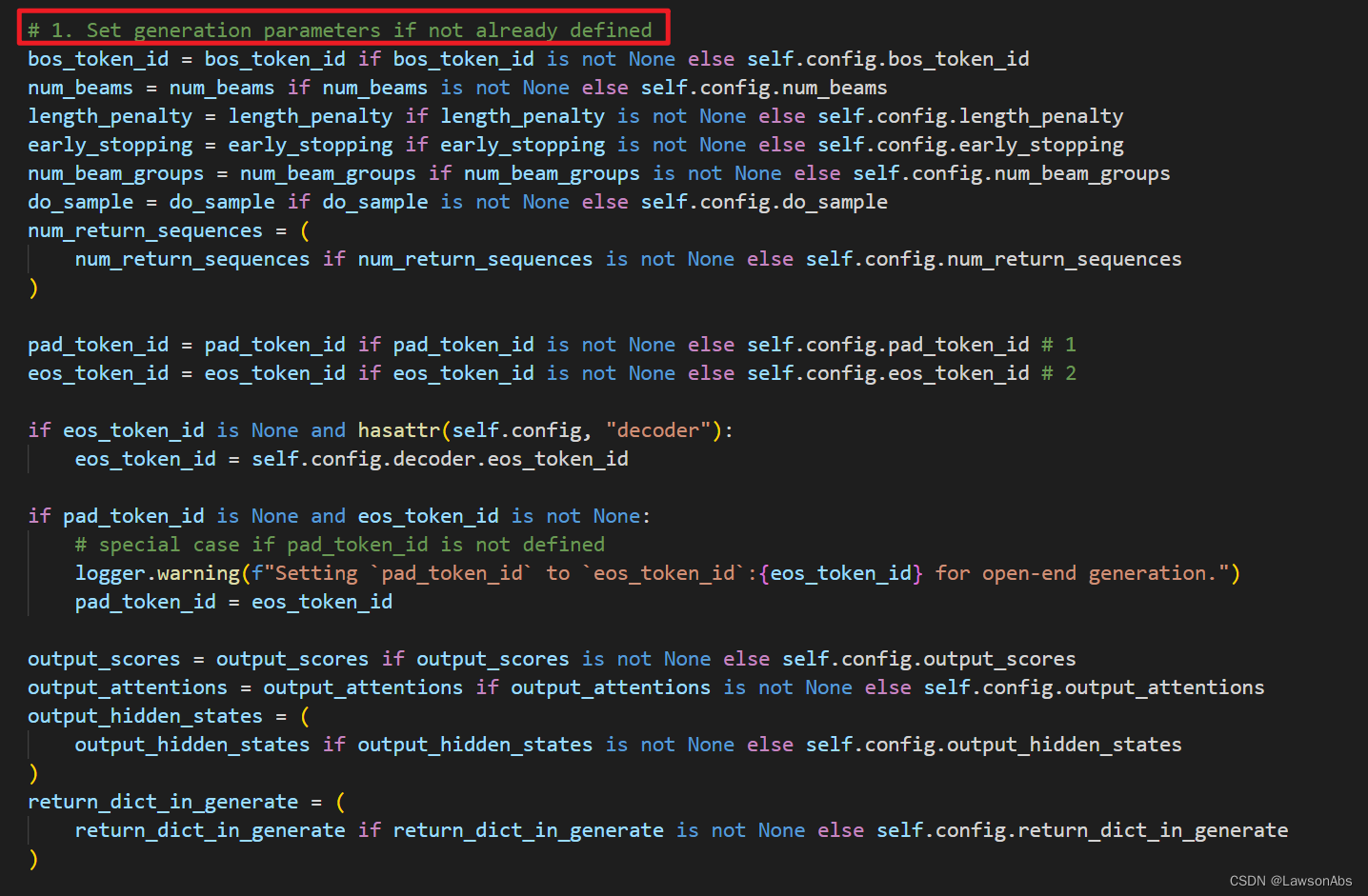

其中这里的 inputs 就是平常我们tokenizer之后的 input_ids,其shape大小是 [bsz,hidden_dim]。bos_token_id = 0
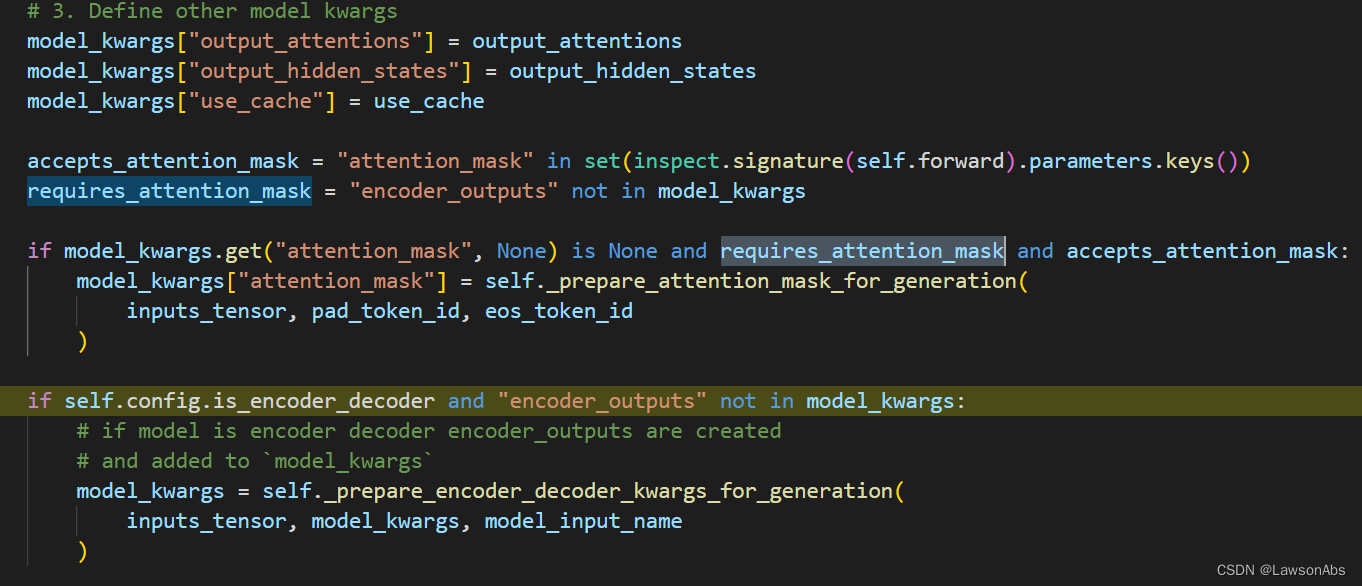
看一下 attention_mask 的属性
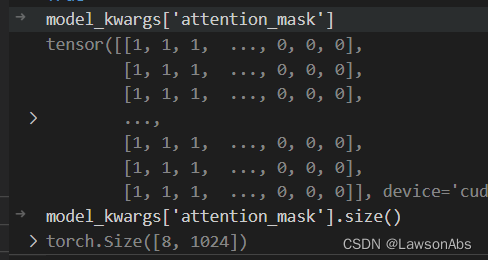
这个 attention_mask 是给encoder使用的。上面这个流程会判断:如果模型是encoder_decoder 架构,那么就要事先把encoder的结果算出来。也就是如下这行代码:
if self.config.is_encoder_decoder and "encoder_outputs" not in model_kwargs:
#if model is encoder decoder encoder_outputs are created
# and added to `model_kwargs`
model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(
inputs_tensor, model_kwargs, model_input_name
)
- 1
- 2
- 3
- 4
- 5
- 6
其中的这个 _prepare_encoder_decoder_kwargs_for_generation()函数如下:
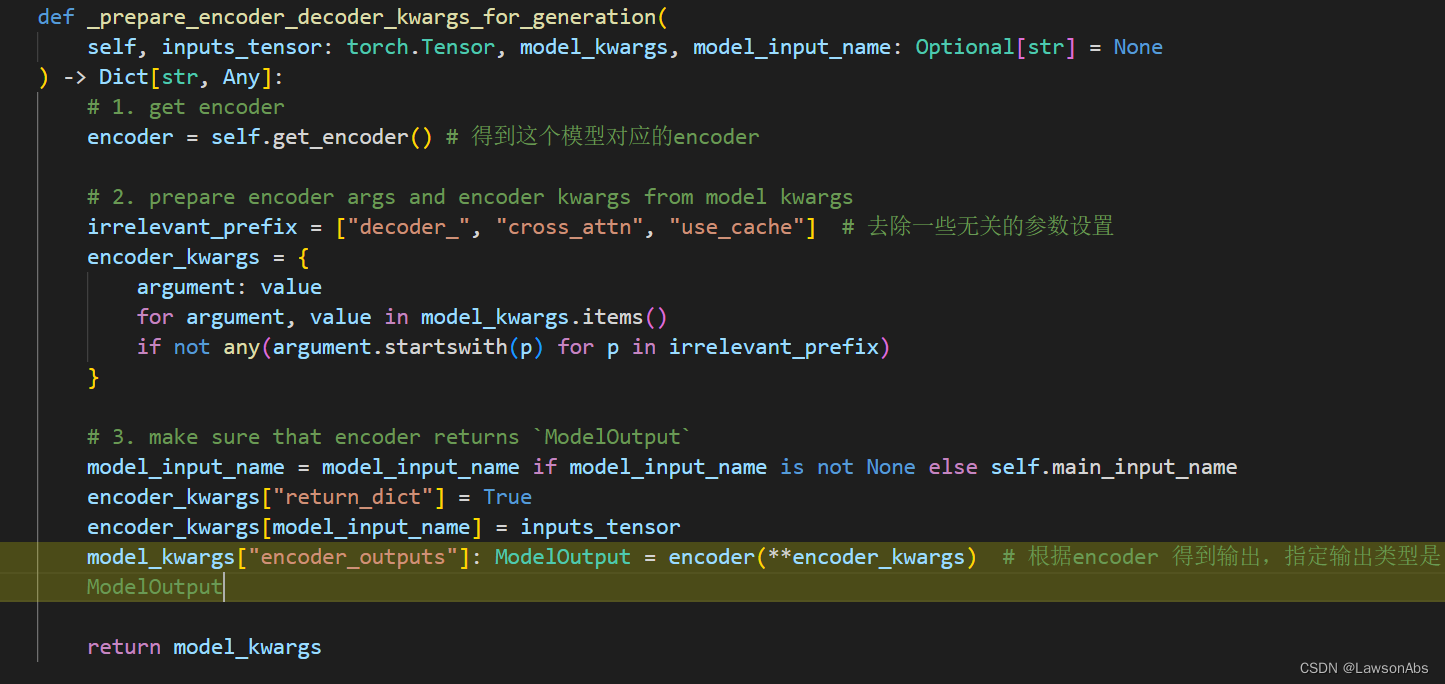
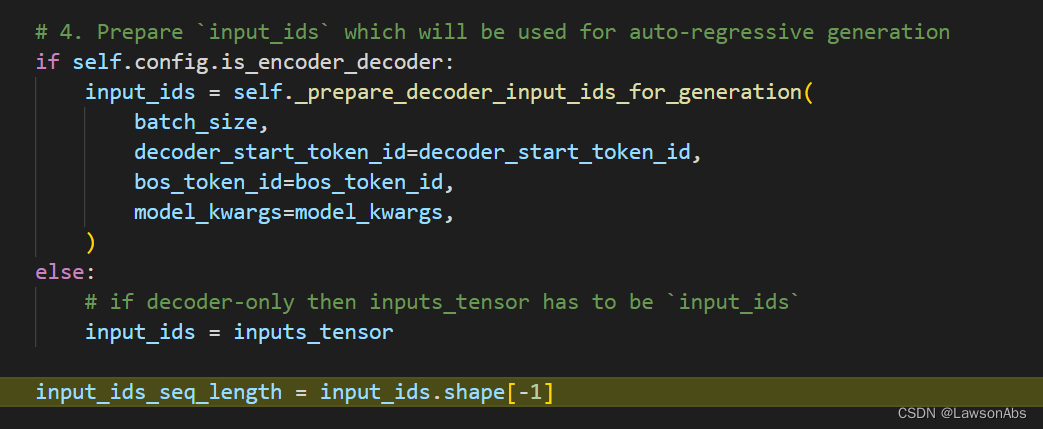
将encoder的结果写到 model_kwargs 中。下面就紧接着准备 decoder_input_ids ,这是给生成做的。主要是调用 _prepare_decoder_input_ids_for_generation()这个函数
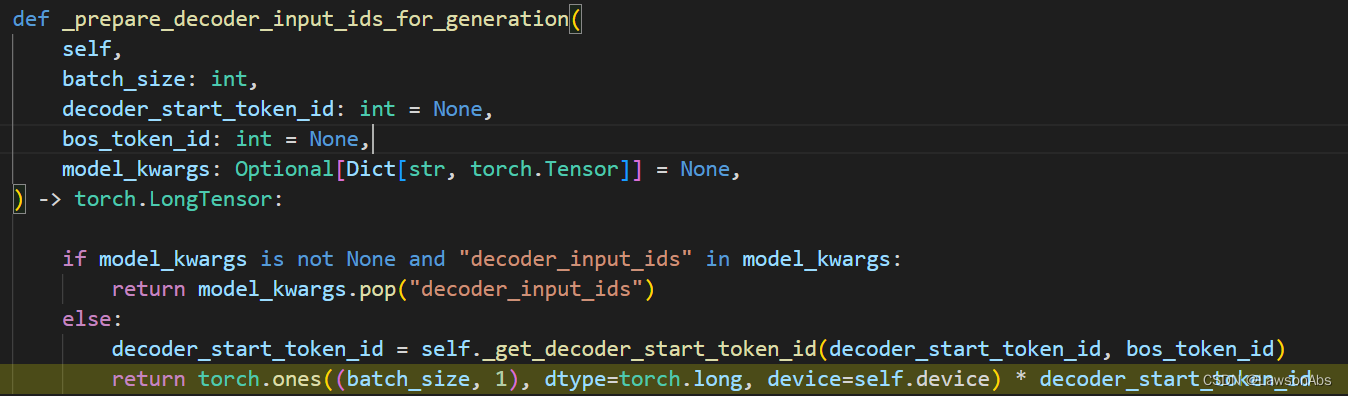
看下这个具体的函数逻辑:
- 如果decdoer_input_ids 在模型中,那么就直接返回这个decoder_input_ids,
- 否则创建一个shape 为
(batch_size,1)的 tensor,其中的值为1*decoder_start_token_id
计算完这个之后,就可以得到 input_ids_seq_length,也就是输入到decoder的decoder_input_ids的第二个维度的值。在这里就是1。
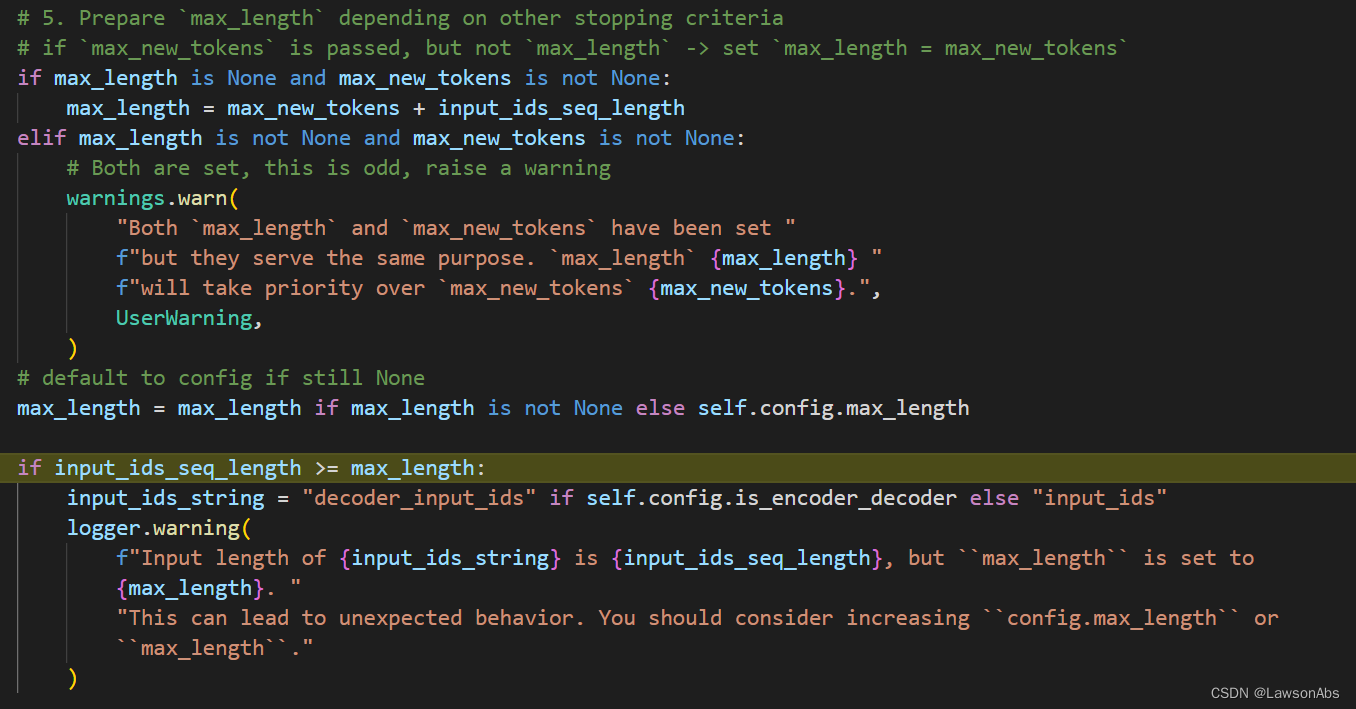
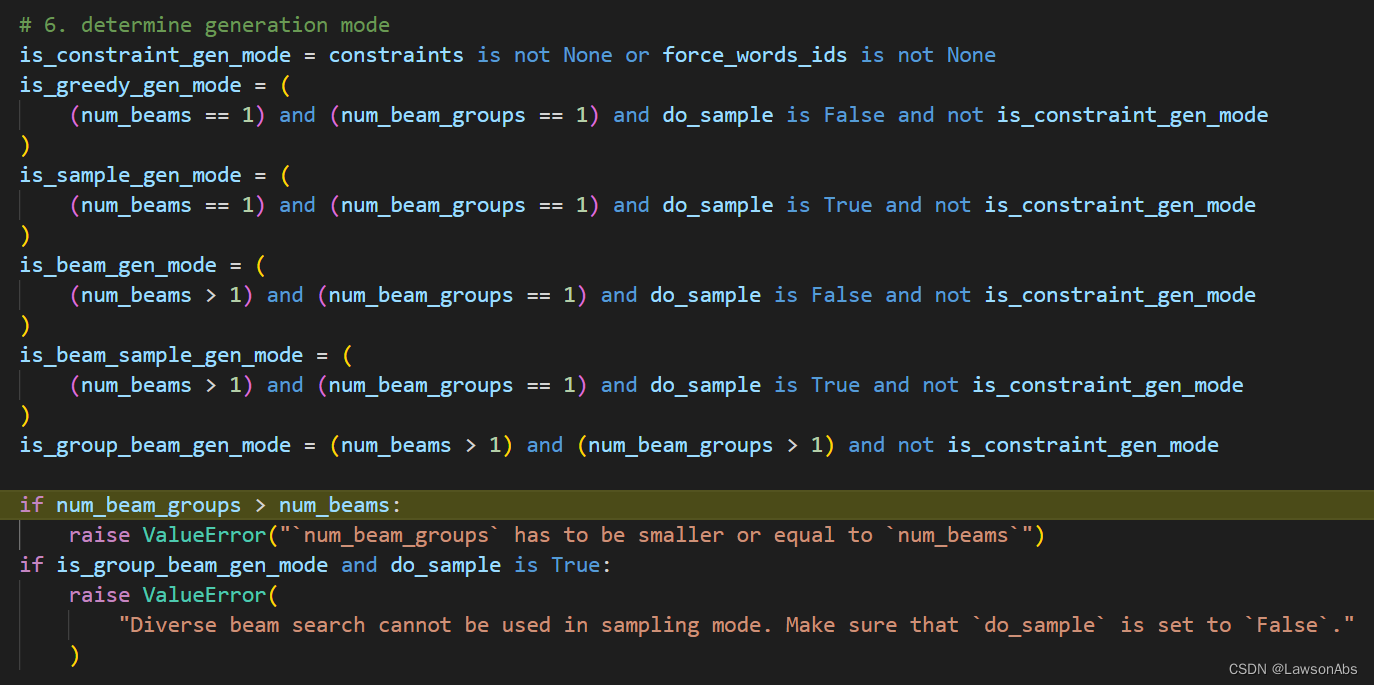
调整完生成的文档的长度之后,需要再判断目前用什么模式生成文本。
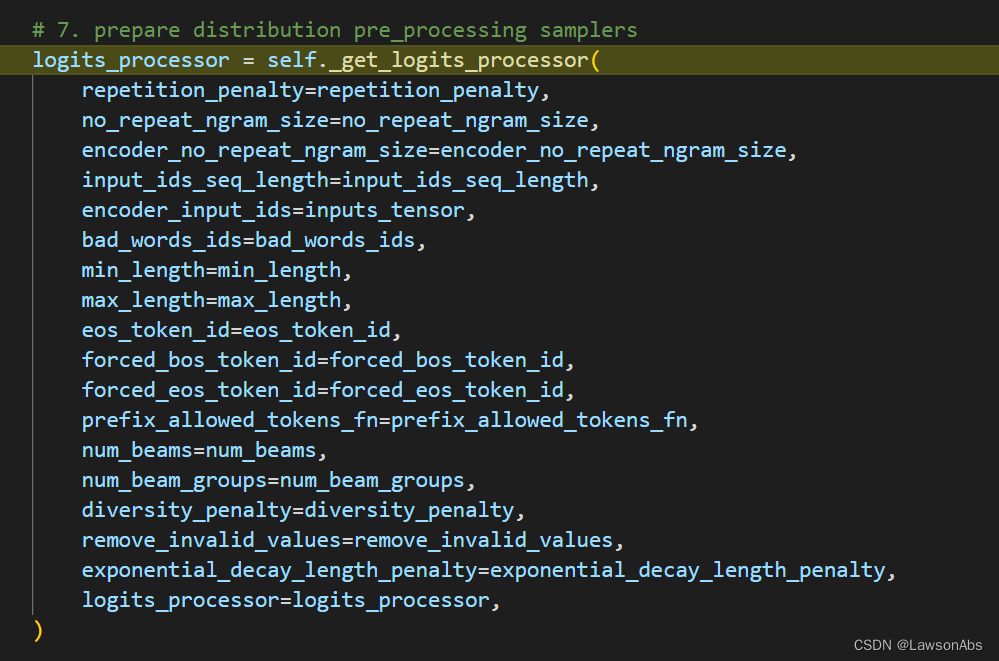
接着,定义一个logits的处理器,用于在计算得到logits之后,再做一些修改。
然后定义一个生成结束的条件

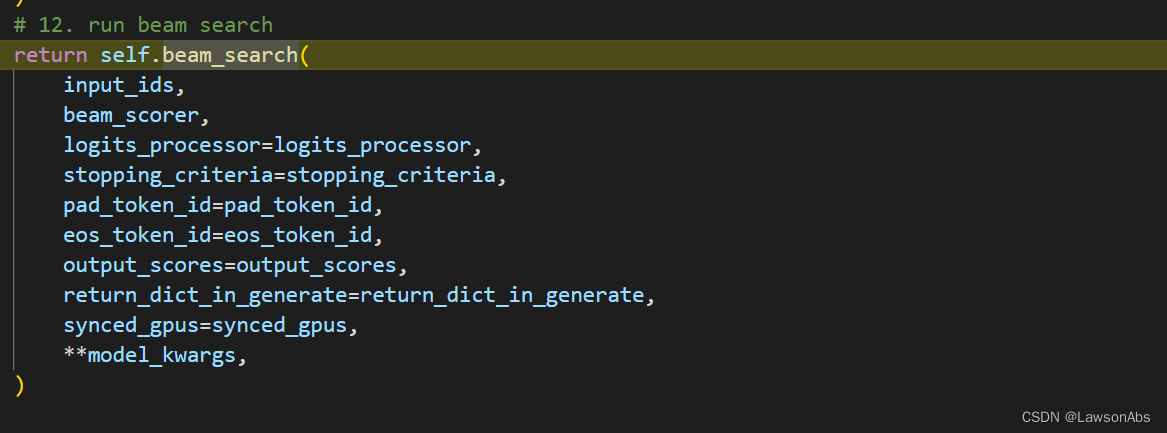
最后就进入到生成的核心模块了,因为我这里选用的是beam search 作为最后的生成方法。

== 那么这里面的 BeamSearchScorer 是干嘛的?==

上面这个 _expand_inputs_for_generation()我也不是很清楚原因。
但造成的结果是 input_ids 和 model_kwargs 中的attention_mask, encoder_outputs 都从之前的[bsz,…] 变成了 [bsz*num_beams,…] 维度。最后就是执行 beam_search 的过程了。
进入到beam_search之后,主要的是下面这个while循环
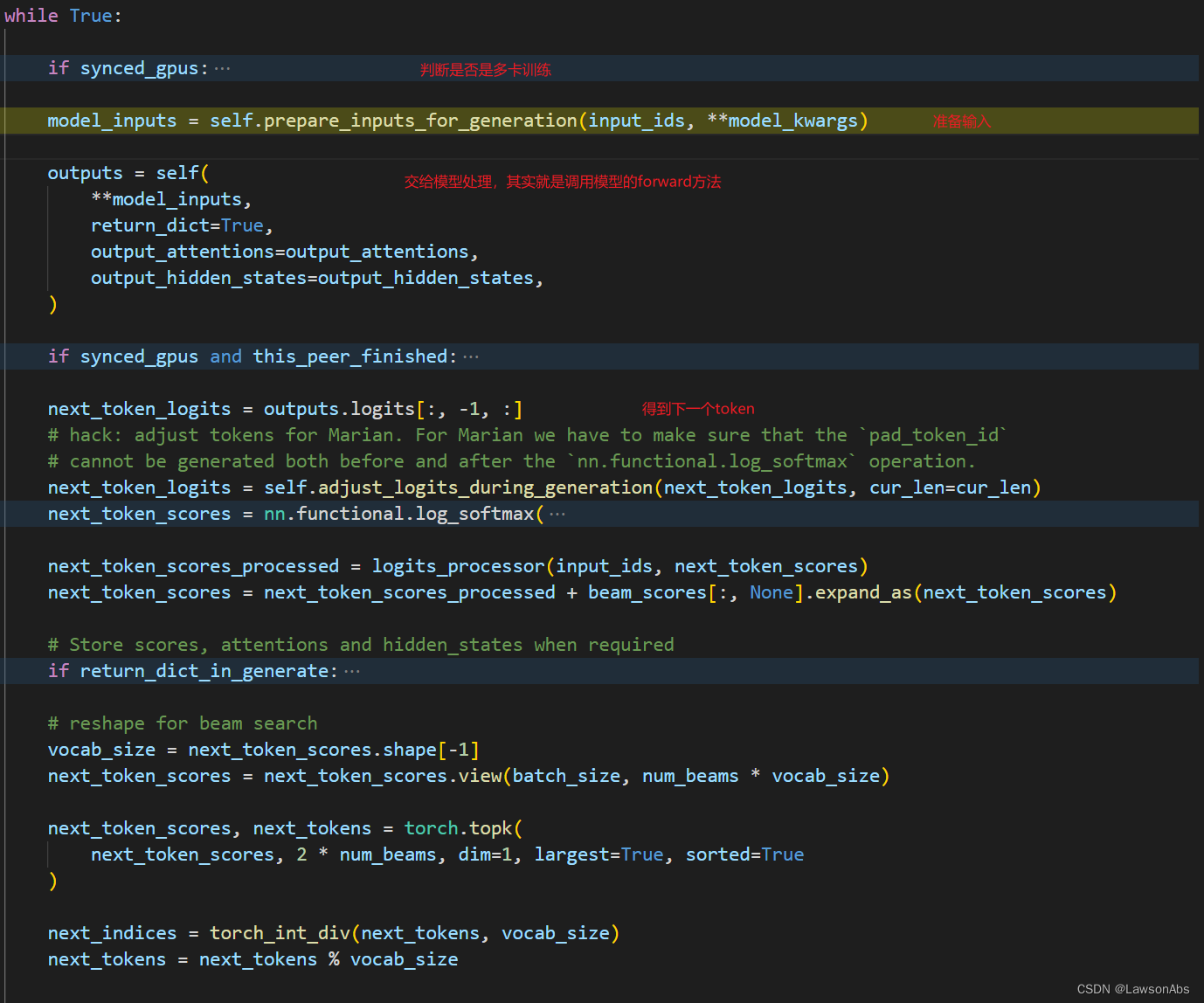

outputs.logits.size (bsznum_beams,1,|V|) => (bsznum_beam,|V|)
然后对生成的结果做一个 softmax 操作:

得到得到了softmax之后的分数还不算完,还需要是用 LogitProcessor 进行处理。

上面这行代码会对应执行下面几个类的处理:
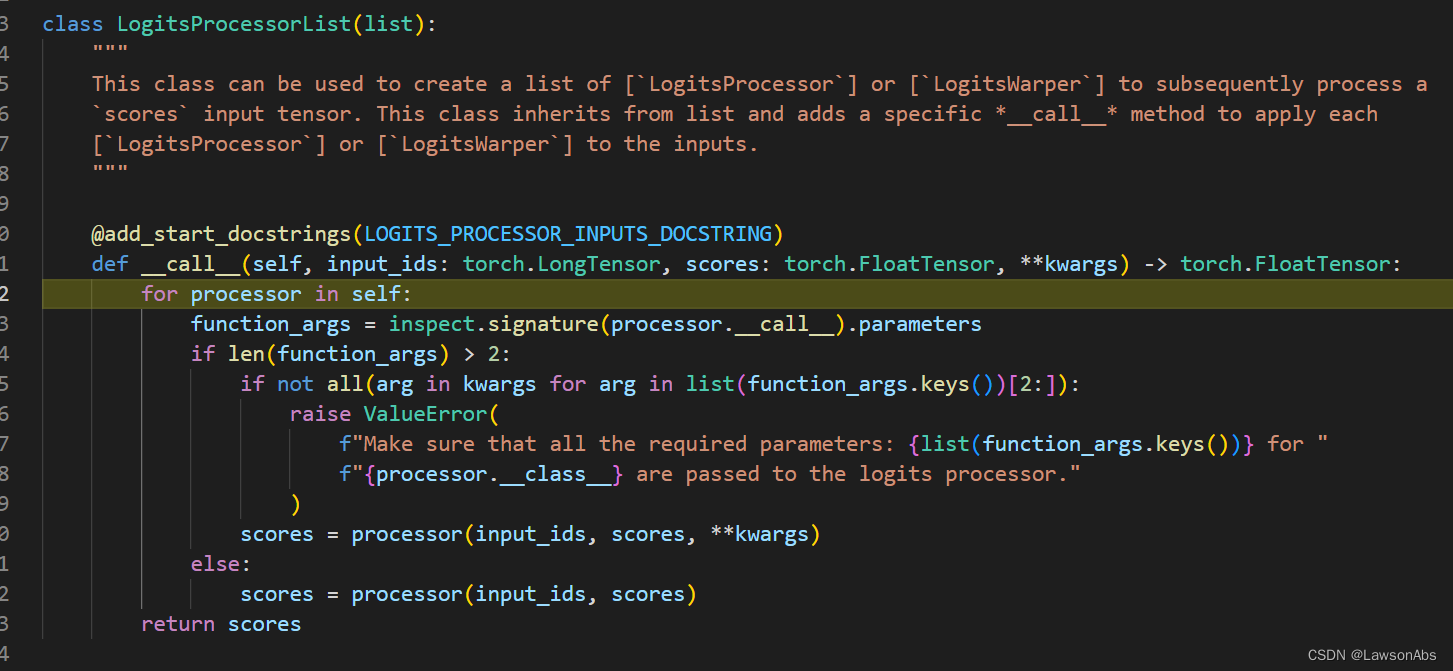
紧接着调用下面这个 LogitsProcessor:
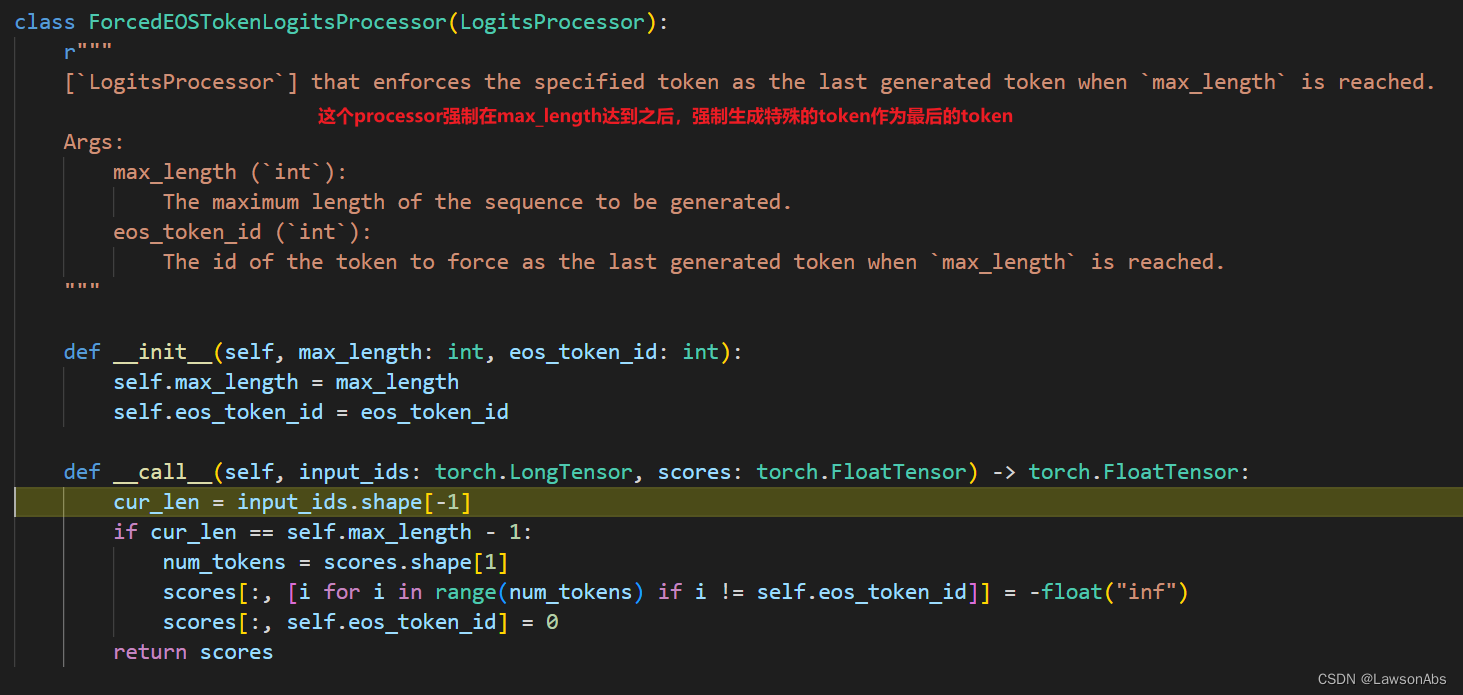

在对scores处理之后,需要加上beam_score?这又是为啥?
beam_scores[:,None] 便从 bsz * num_beam 变成了 [bsz*num_beams,1],

这里的topk操作结合了下面这几个参数:
- largest表示的是是否返回最大值,如果为false,就代表返回最小值
- 2*num_beams 代表的就是k的值
得到的next_token_scores 就是一个 维度大小为[bsz,2*num_beams] 的一个值。(为啥是 2*num_beams 不清楚)。

torch_int_div 是一个整除的方法,可能不同的torch版本,实现的方法有些不同,所以这里搞成了 torch_int_div 的方式来实现。【但是不清楚为啥要得到 next_indices】
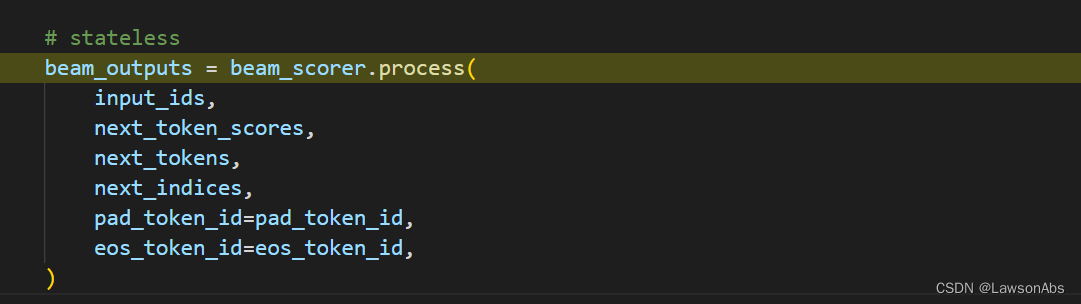
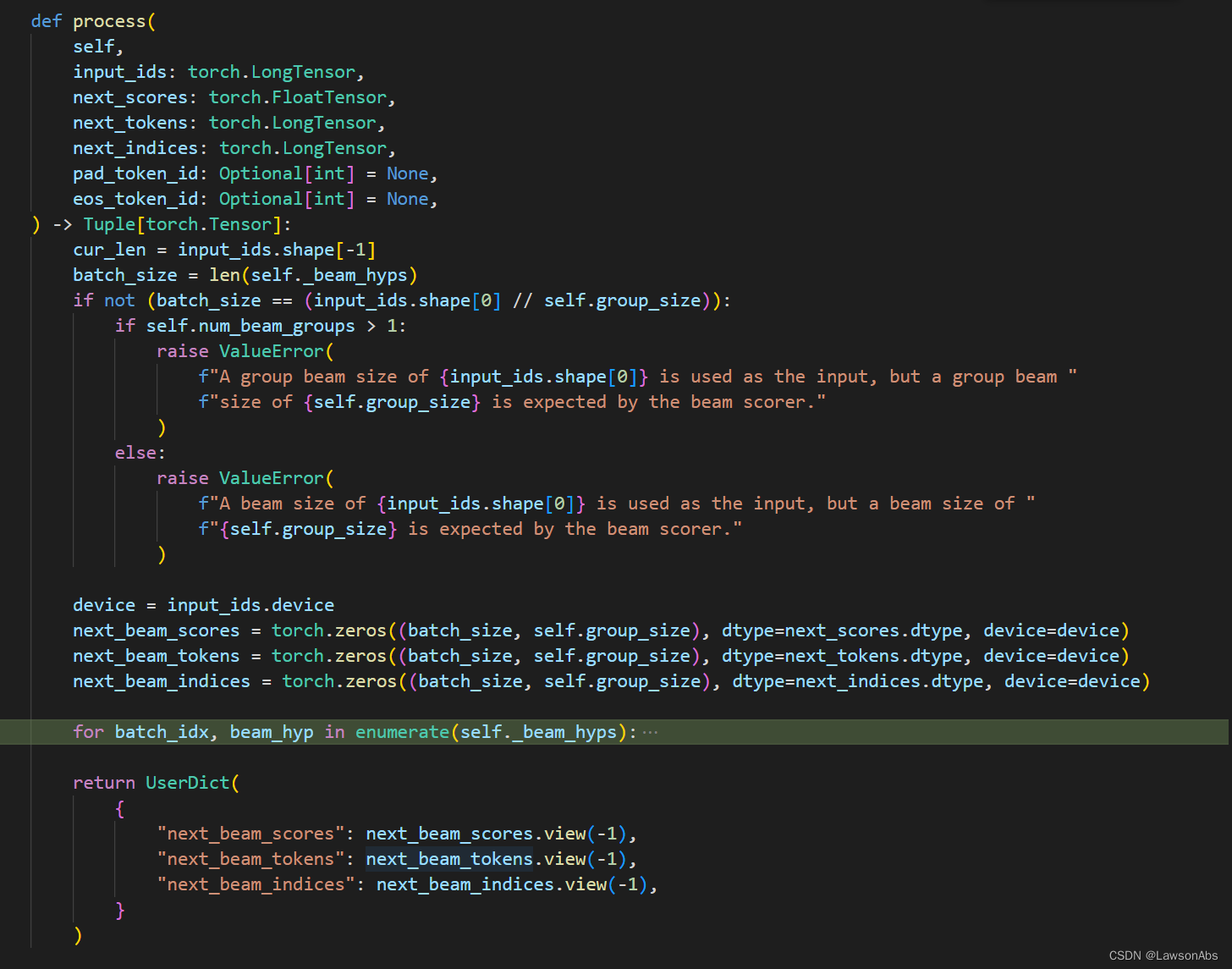
这个process方法就会调用 BeamSearchScorer 类的 process 方法。
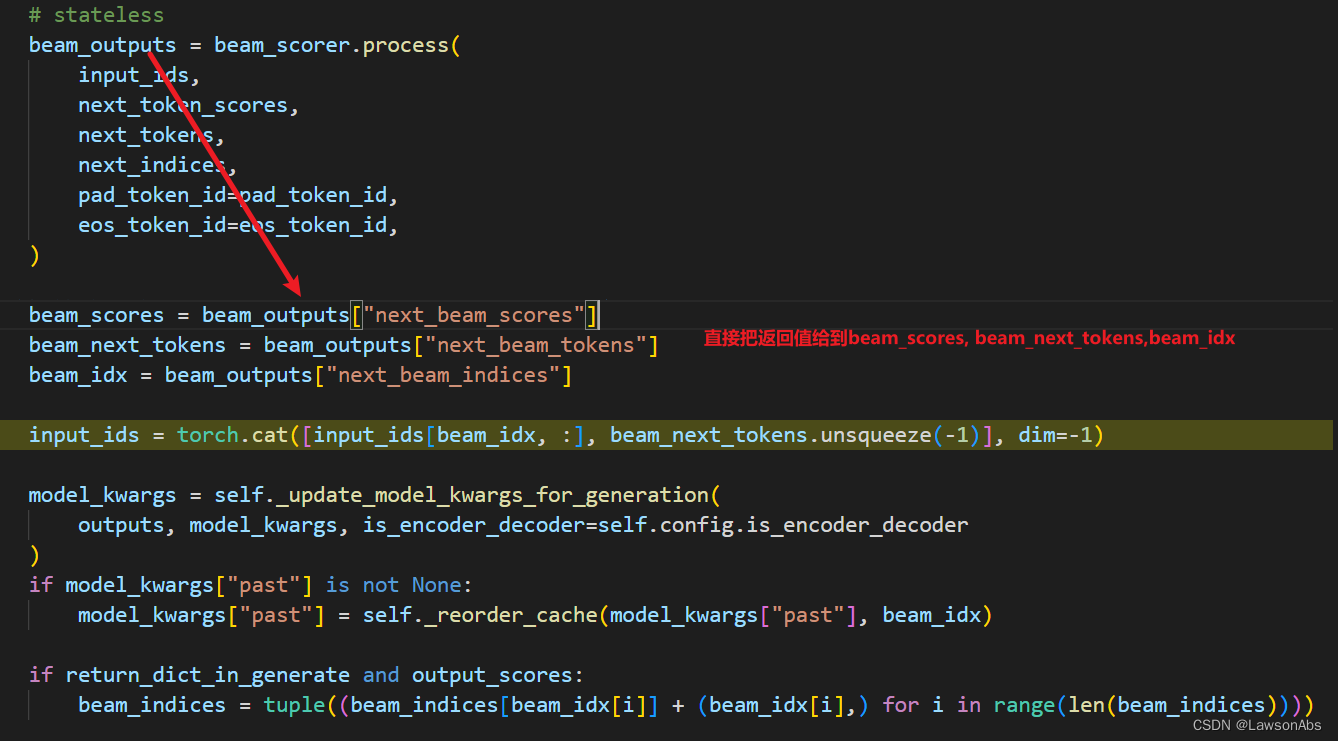


下面看看这个 prepare_inputs_for_generation
讲一下 cache 生成的细节,涉及到的代码主要是在 BartDecoder的forward方法中,主要由下面这几行构成
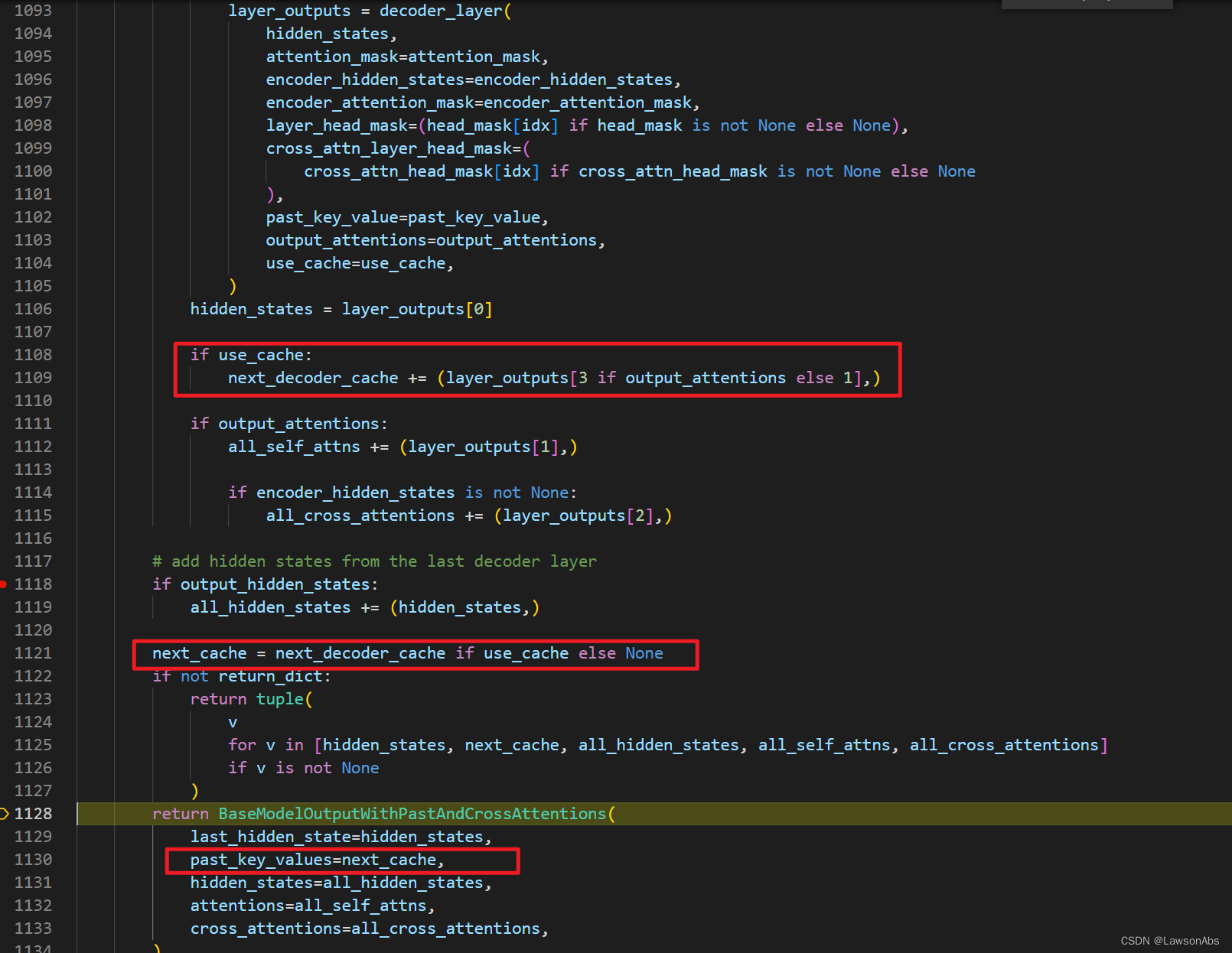
decoder_layer() 方法中的 hidden_states 就是decoder_input_ids 映射得到的embedding。
再进入到 BartDecoderLayer 的forward方法,可以看到其实past_key_value 包括了两个部分的key_value,分别是self attention 和 cross_attention 中的。
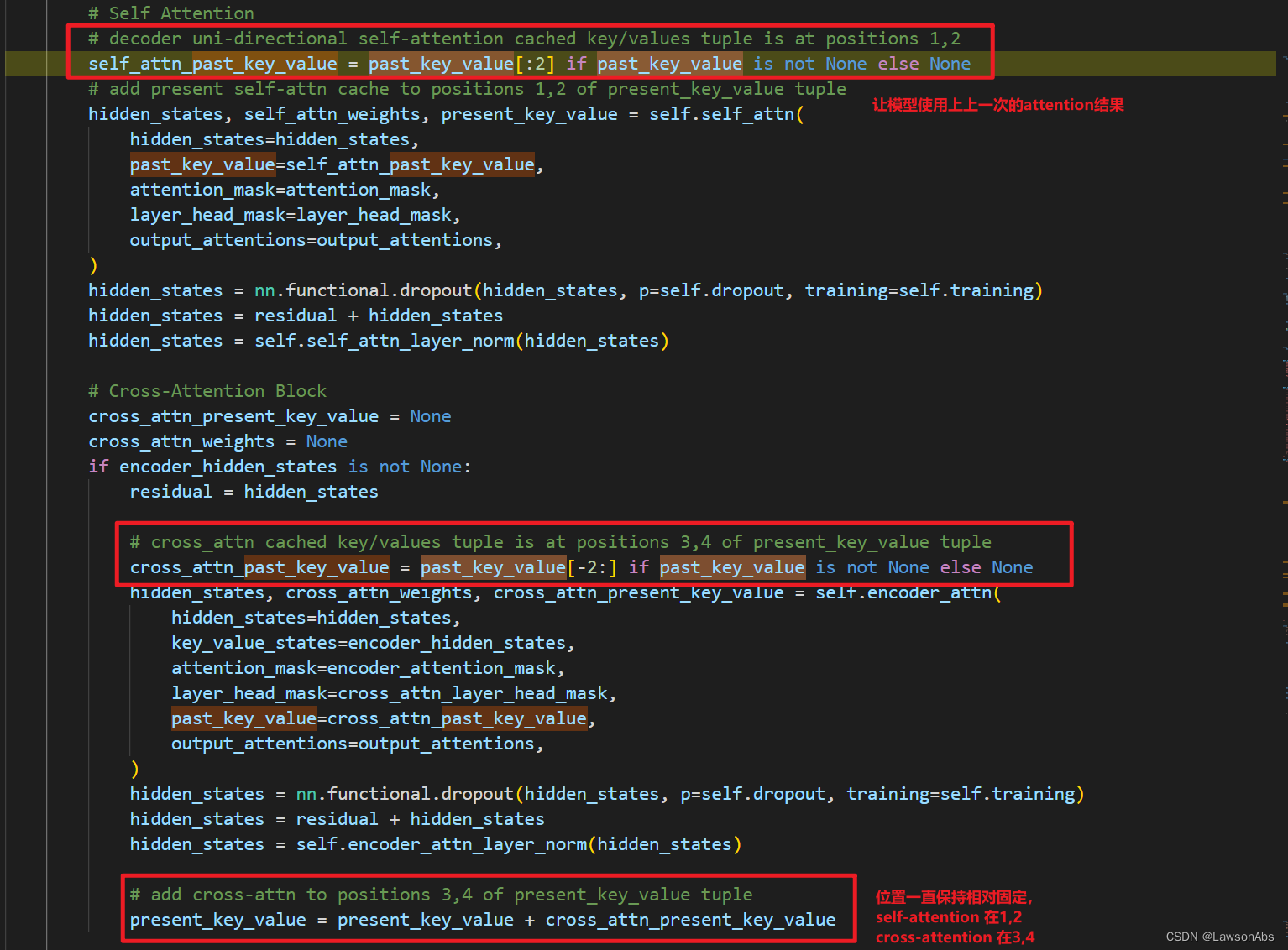
这存的是K 和 V的值,K和V的值是通过hidden_states 经过一个线性矩阵映射过来的。
为什么要有这个cache?
什么时候用?
怎么用的?
再看下面这张图:
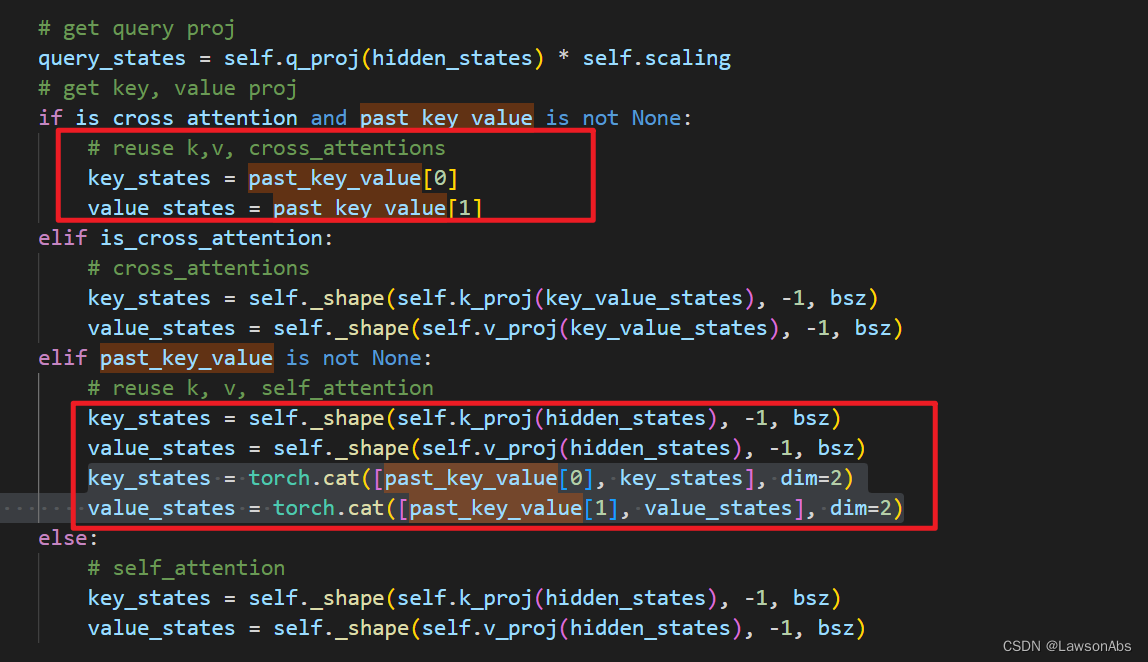
这里cross_attention 的key_states, value_states 其实始终如一。这个很好理解,因为 cross_attention 对于每层decoder都是同一个K,V。但是对于不同层的decoder的 self-attention 的 key,value 都是不同的。所以这里都是先计算一下当前的这个 key_states 和 value_states,然后再拼接回去。这也就说明,在decoder的self-attention中,每次的hidden_states 都是一个单词的hidden states?
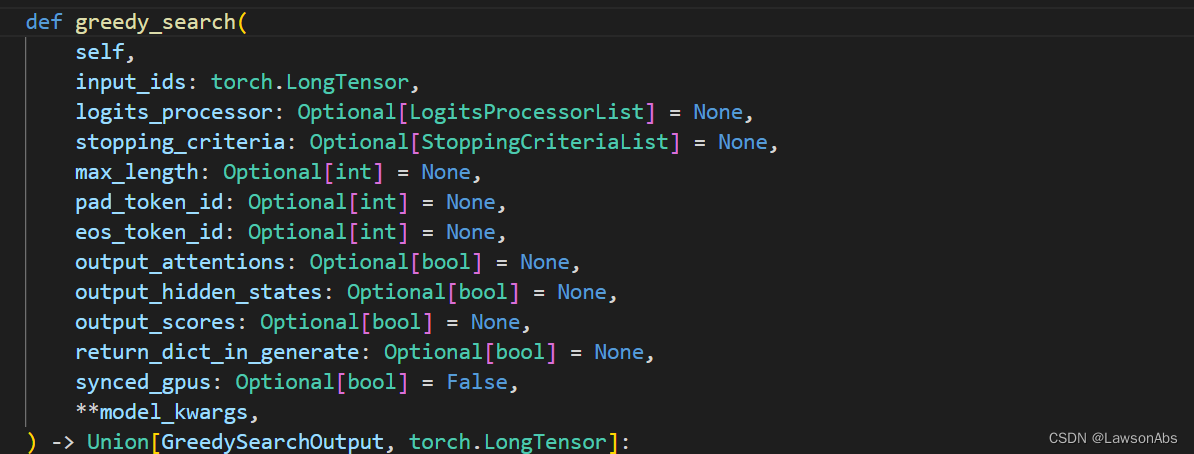
再看下:greedy_search() 这个函数