
热门标签
热门文章
- 1ZBarSDK支持armv7s
- 2JSON Undefined 问题
- 3OFD文档标准 1. 文档结构、命名空间和数据类型_signedvalue.dat
- 4DC-9靶机渗透测试_dc9靶机渗透测试
- 5Nuxt3踩坑日记 - window.__NUXT___nuxt3 windows
- 6ECS训练营 Day2 搭建Docker环境
- 7当前低代码和数据大模型逐渐盛行,前端还有前景嘛?_大模型时代低代码过时了吗
- 8Servlet学习02_jakarta.servlet
- 9InnoDB MVCC何时创建read view
- 10Springboot 基于netty-socketio 实现简单的在线聊天_socketio 实现 在线聊天功能
当前位置: article > 正文
用PyTorch从零开始编写DeepSeek-V2
作者:空白诗007 | 2024-07-31 22:18:42
赞
踩
用PyTorch从零开始编写DeepSeek-V2
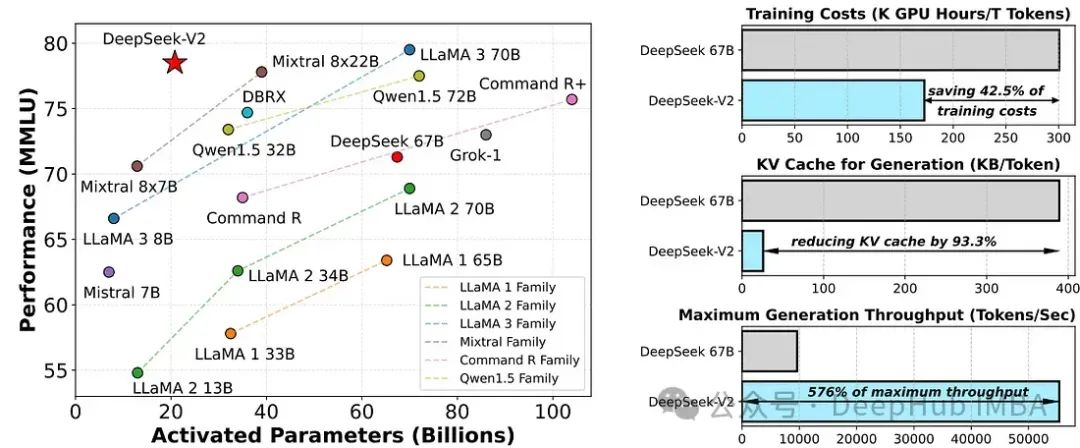
DeepSeek-V2是一个强大的开源混合专家(MoE)语言模型,通过创新的Transformer架构实现了经济高效的训练和推理。该模型总共拥有2360亿参数,其中每个令牌激活21亿参数,支持最大128K令牌的上下文长度。
在开源模型中,DeepSeek-V2实现了顶级性能,成为最强大的开源MoE语言模型。在MMLU(多模态机器学习)上,DeepSeek-V2以较少的激活参数实现了顶尖的性能。与DeepSeek 67B相比,DeepSeek-V2显著提升了性能,降低了42.5%的训练成本,减少了93.3%的KV缓存,并将最大生成吞吐量提高了5.76倍。
我们这里主要实现DeepSeek的主要改进:多头隐性注意力、细粒度专家分割和共享的专家隔离
架构细节
DeepSeek-V2整合了两种创新架构,我们将详细讨论:
- 用于前馈网络(FFNs)的DeepSeekMoE架构。
- 用于注意力机制的多头隐性注意力(MLA)。
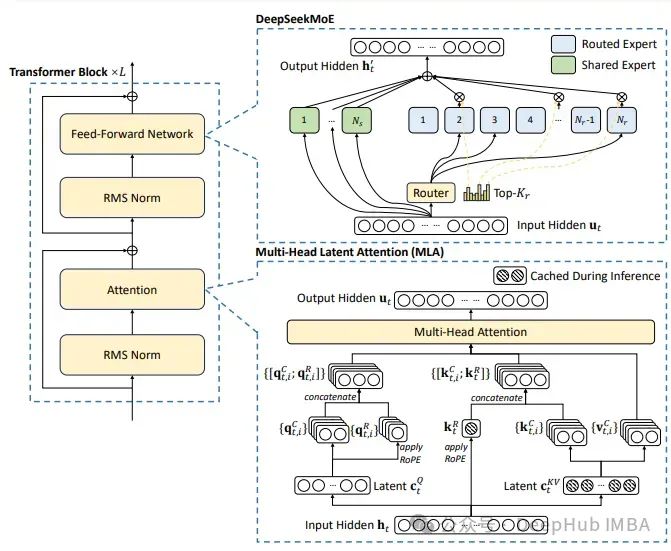
DeepSeekMoE
在标准的MoE架构中,每个令牌被分配给一个(或两个)专家,每个MoE层都有多个在结构上与标准前馈网络(FFN)相同的专家。这种设置带来了两个问题:指定给令牌的专家将试图在其参数中聚集不同类型的知识,但这些知识很难同时利用;其次,被分配给不同专家的令牌可能需要共同的知识,导致多个专家在各自的参数中趋向于收敛,获取共享知识。
为了应对这两个问题,DeepSeekMoE引入了两种策略来增强专家的专业化:
- 细粒度专家分割:为了在每个专家中更有针对性地获取知识,通过切分FFN中的中间隐藏维度,将所有专家分割成更细的粒度。
- 共享专家隔离:隔离某些专家作为始终被激活的共享专家,旨在捕获不同上下文中的共同知识,并通过将共同知识压缩到这些共享专家中,减少其他路由专家之间的冗余。
让我们来定义DeepSeekMoE中第t个令牌的专家分配。如果u_t是该令牌的FFN输入,其输出h`_t将会是:
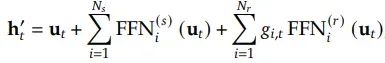
其中声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

