
- 1护理管理学选择题汇总(人卫第三版)_多选题】职业规划设计的原则有哪些( )(2.0)a清晰一致原则b适应性原则c激励性
- 2【前端】JavaScript入门及实战6-10
- 3基于机器学习的糖尿病风险预警分析系统的设计与实现
- 4Laravel Blade:简洁高效的模板引擎
- 5论文翻译:通过云计算对联网多智能体系统进行预测控制
- 6Vue + ElementUI 手撸后台管理网站基本框架(二)权限控制_elementui流程图
- 7前端开发three.js入门超详细学习,一起来学习3D吧
- 8Mysql 8.0.36-0ubuntu0.22.04.1 关闭SSL_mysql8.0查看是否启用ssl
- 9【异步爬虫:利用异步协程抓取一部电影】
- 10我的秋招复盘——回顾2022秋招经历_非科班面试中科创达不准备怎么办
计算机毕业设计:基于python招聘数据分析可视化系统+预测算法+爬虫+Flask框架_基于python的2023年招聘数据可视化分析的毕业论文的中期检查报告
赞
踩
1、项目介绍
本论文旨在通过使用Python的requests库爬取拉勾网的招聘数据,并对数据进行清洗和持久化保存,以研究市场上招聘信息的趋势和分布情况。使用Flask框架作为后端技术,将数据库中的数据呈现给前端展示,借助基于前端框架Layui的应用,并结合图表展示工具ECharts,将数据以饼图、条形图等形式进行可视化展示。主要展示了招聘信息的数量分布、薪资分布情况以及关键词的分布情况。通过数据分析和可视化展示,得出如下结论:不同城市和行业的招聘信息数量和薪资水平有明显差异,而不同的招聘职位则有不同的职能和技能要求。因此,这些数据和分析结果对于个人求职者和企业招聘者提供了有益的参考。
关键词:requests; Flask框架;ECharts;Mysql;Layui
2、项目界面
(1)招聘企业分析
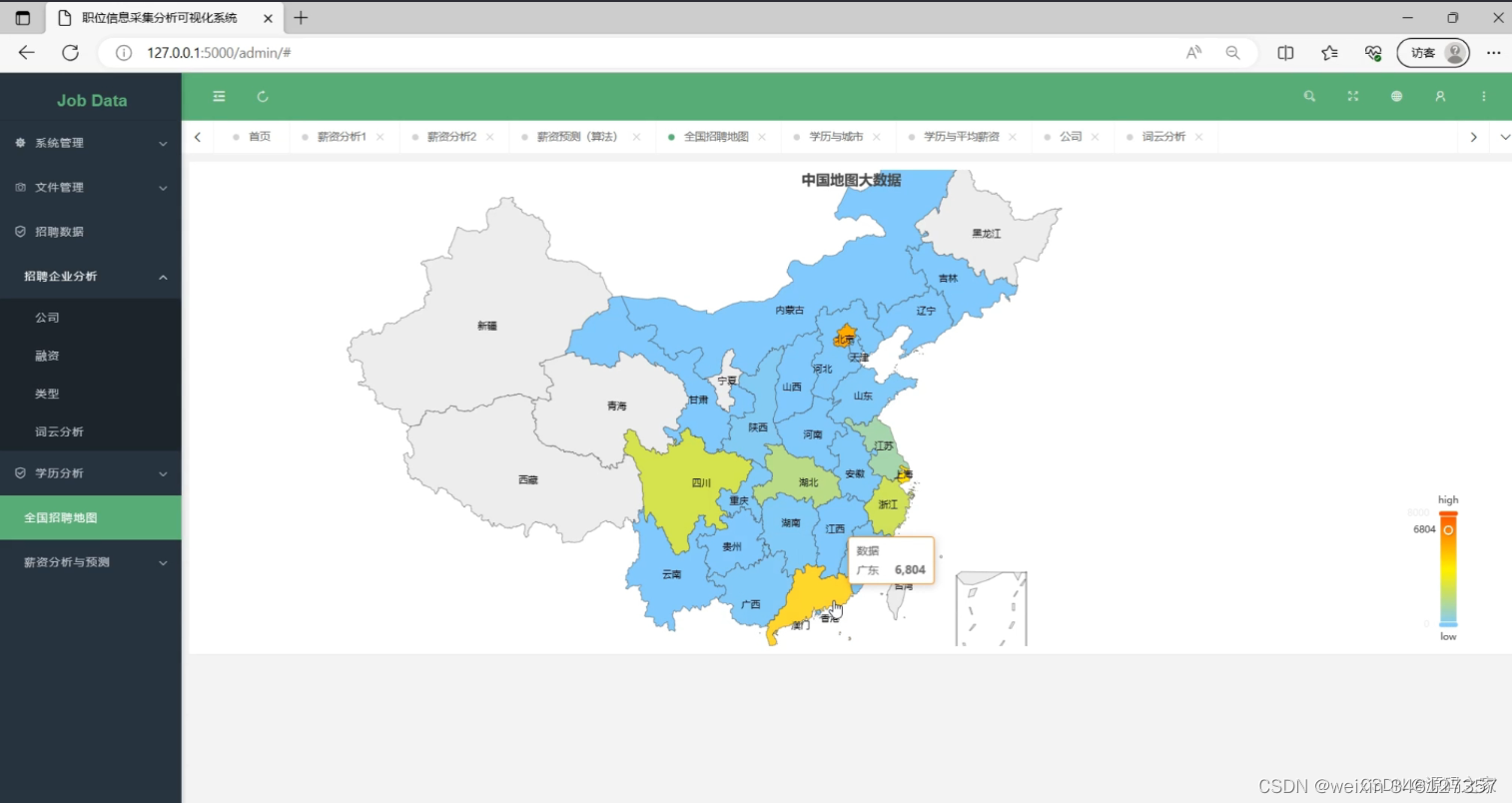
(2)全国招聘地图
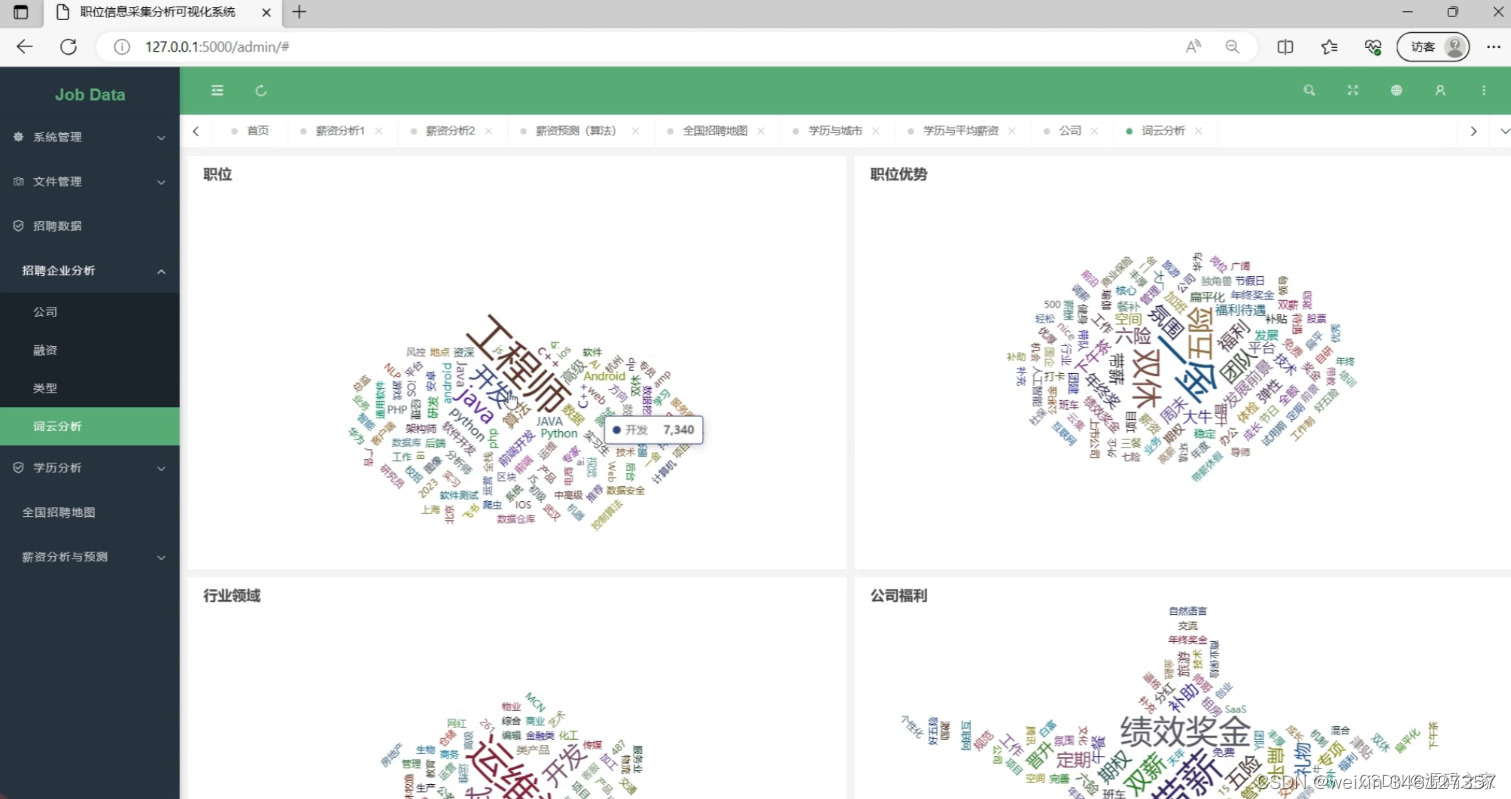
(3)岗位分析词云图
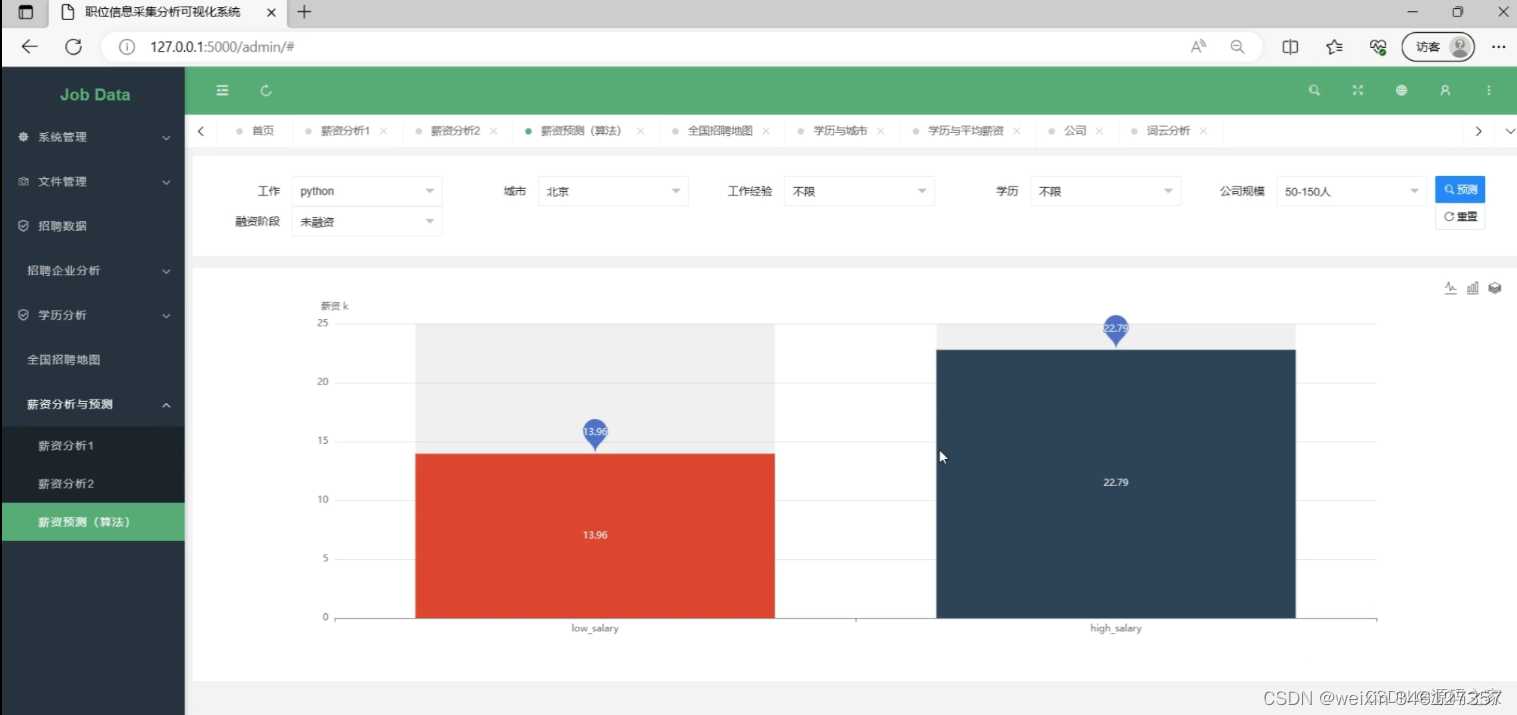
(4)薪资预测模块
(5)招聘企业分析----融资情况
(6)招聘企业分析----类型
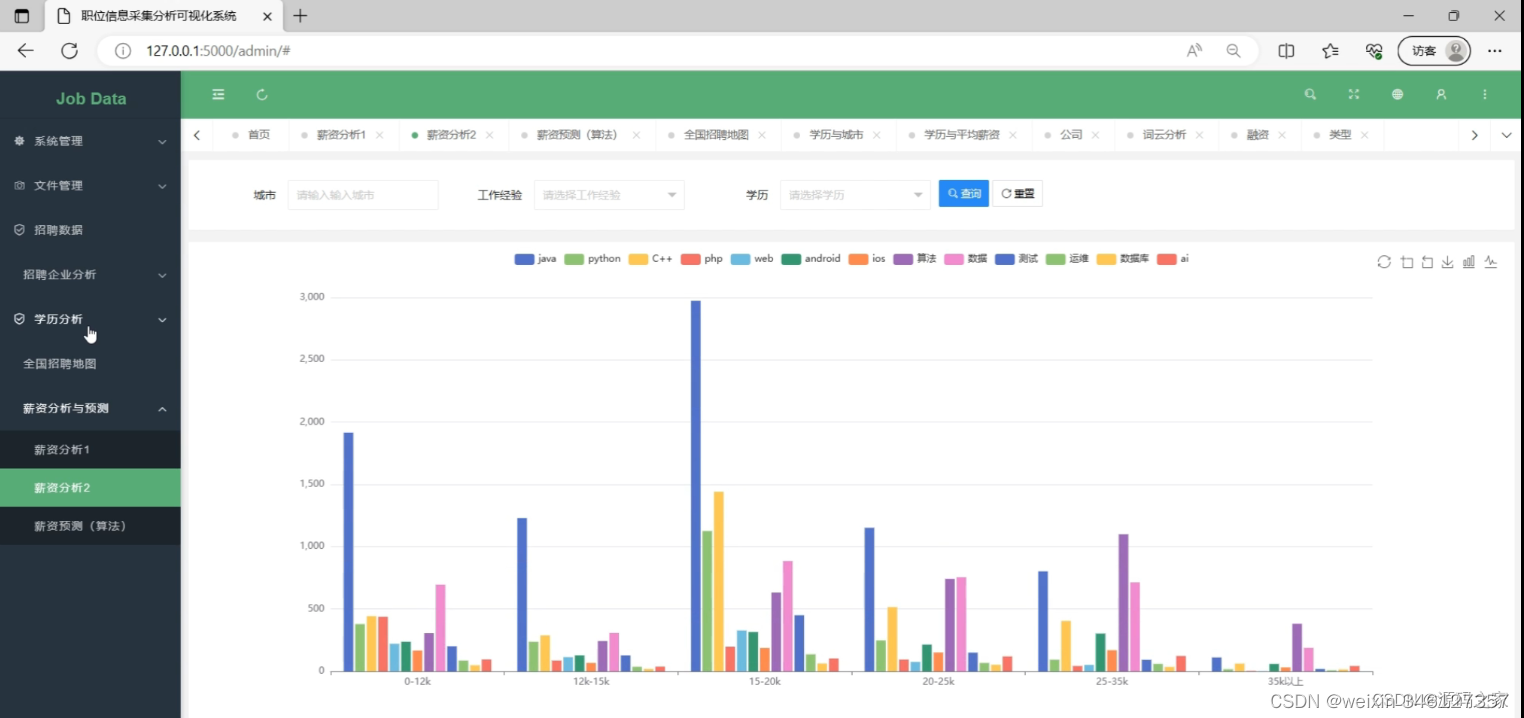
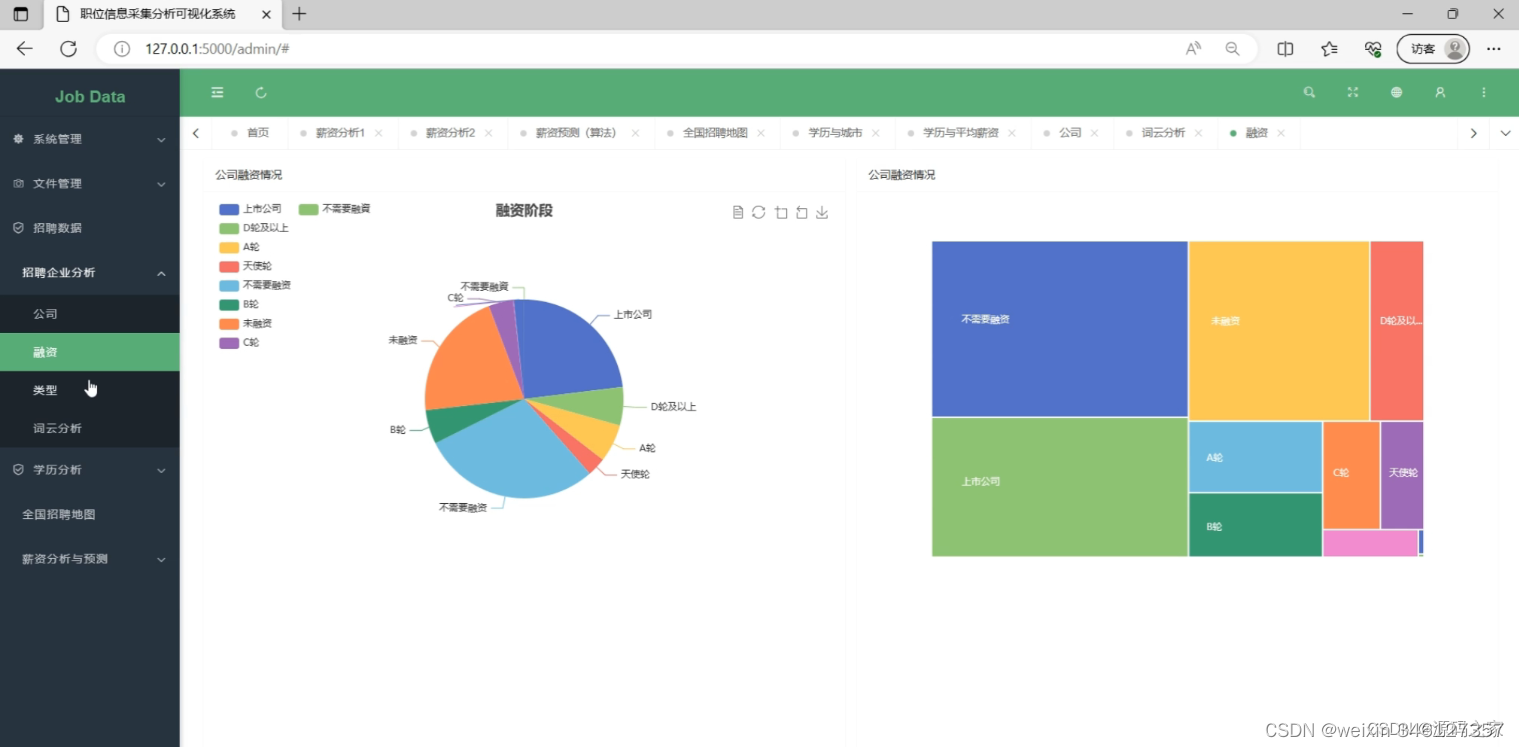
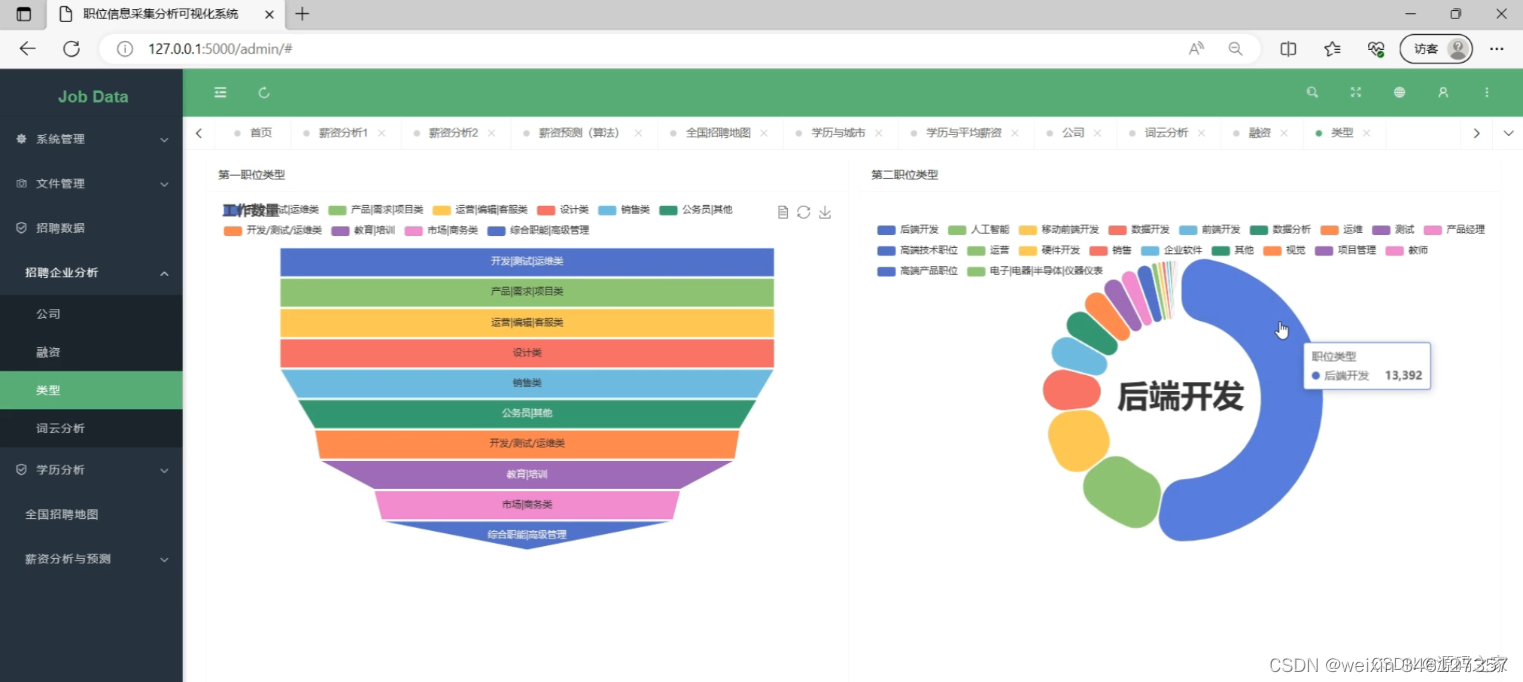
(7)薪资分析
(8)数据采集
3、项目说明
(1)系统功能设计
本系统是使用python进行创作,基于Flask框架实现Web功能,使用MySQL存储系统信息,结合ECharts进行数据可视化分析[11],数据获取通过requests对拉勾网进行爬取,获取的数据进行清洗处理后存储到MySQL数据库中,大致实现数据的爬取,系统管理和数据的可视化等模块[12],系统功能模块如图4-1系统功能模块。
(2)薪资预测模块
可以通过选择职位学历城市工作经验,使用随机森林预测薪资。核心代码如下:
提取特征和标签
X = df[['education', 'city', 'work_year', 'com_size', 'finance_stage']]
y = df[['low_salary', 'high_salary']]
#训练随机森林模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X, y)
#预测薪资范围
new_data = pd.DataFrame({'education': [1], 'city': [1], 'work_year': [1], 'com_size': [1], 'finance_stage': [1]})
prediction = model.predict(new_data)
print(prediction)
1
2
3
4
5
6
7
8
9
10
11
12
特征数据包括"education"、“city”、“work_year”、"com_size"和"finance_stage"这些列,标签数据包括"low_salary"和"high_salary"这两列。
然后,代码使用RandomForestRegressor类初始化一个随机森林回归模型,并通过调用fit方法对模型进行训练,将特征和标签数据作为参数传入。
接下来,代码创建了一个新的DataFrame对象new_data,其中包含了一个示例的特征数据。然后,通过调用训练好的模型的predict方法,对新的特征数据进行薪资范围的预测。


