
热门标签
热门文章
- 1Python tkinter+pymysql 学生管理系统_python tkthine+mysql 学生管理系统
- 2Windows电脑快速搭建FTP服务教程_windows搭建ftp
- 3Python中进程和线程到底有什么区别?_python线程和进程的关系和区别_python中线程进程的区别
- 4毕业设计:python共享单车数据分析系统 可视化 Flask框架 骑行数据分析 (源码)✅_自行车骑行记录记录数据源代码
- 5【Flink】Flink常量UDF-TableFunction优化_flink udf函数优化
- 6保姆级教程!奶奶都能学会的Mac本地部署Stable Diffusion教程_stable diffusion mac电脑配置
- 7配置uniapp调试环境_uniapp 如何设置测试环境
- 8HDFS HA、YARN HA、Zookeeper、HBase HA、Mysql、Hive、Sqool、Flume-ng、storm、kafka、redis、mongodb、spark安装
- 9汉化版PSAI全面测评,探索国产AI绘画软件的创新力量_startai 好用吗
- 10Web框架开发-Django-模板继承和静态文件配置_djongo web 模板
当前位置: article > 正文
用 LLaMA-Factory 在魔搭微调千问_llama-factory 微调千问
作者:空白诗007 | 2024-07-07 08:22:55
赞
踩
llama-factory 微调千问
今天在魔搭上把千问调优跑通了,训练模型现在在 Mac 还不支持,需要用 N 卡才可以,只能弄个N 卡的机器,或者买个云服务器。魔搭可以用几十个小时,但是不太稳定,有的时候会自动停止。
注册账号
直接手机号注册就可以.
找到对应模型
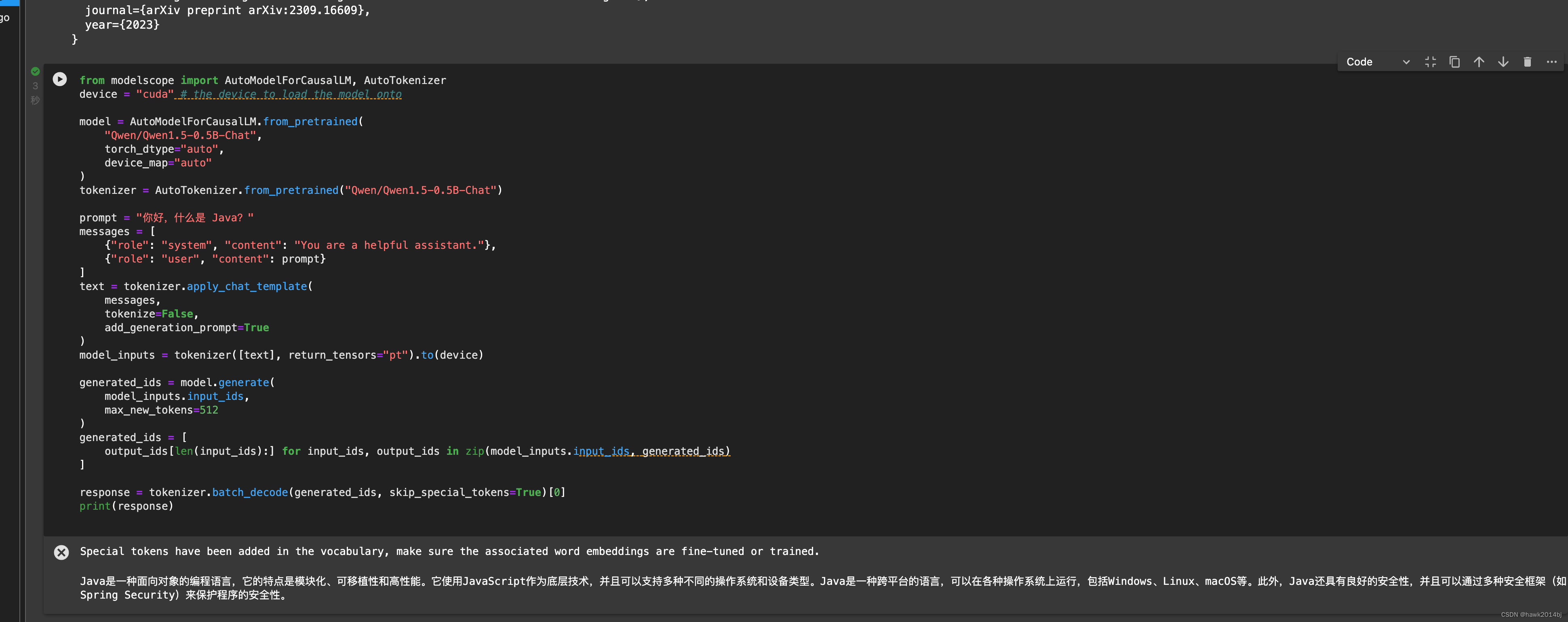
这步可能不需要,随便一个模型,只要启动了 GPU 环境就可以,如果手里有代码,直接启动环境即可。进入模型说明页,通常会有一个测试代码把代码放到 notebook 直接运行接就可以看到结果。我用了Qwen一个最小的模型 0.5B,代码和运行结果如下:
from modelscope import AutoModelForCausalLM, AutoTokenizer device = "cuda" # the device to load the model onto model = AutoModelForCausalLM.from_pretrained( "Qwen/Qwen1.5-0.5B-Chat", torch_dtype="auto", device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-0.5B-Chat") prompt = "你好,什么是 Java?" messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt").to(device) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=512 ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print(response)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
调优
调优模型需要几步,首先,需要准备数据,我这里就是测试一下,所以就直接用了 LLama Factory 的例子。然后,配置命令行参数进行模型训练。
- 安装LLaMA Factory, 通过 notebook 打开安装
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt
pip install modelscope -U
- 1
- 2
- 3
- 4
- 运行训练命令
–model_name_or_path 模型名称要写对
–dataset 训练数据集名称要写对,这个名称是在/data/dataset_info.json进行配置,直接搜索 example 就可以看到
训练很快,因为训练数据就两条,就是测试一下。
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \ --stage sft \ --do_train \ --model_name_or_path Qwen/Qwen1.5-0.5B-Chat \ --dataset example \ --template qwen \ --finetuning_type lora \ --lora_target q_proj,v_proj \ --output_dir output\ --overwrite_cache \ --overwrite_output_dir true \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 32 \ --lr_scheduler_type cosine \ --logging_steps 10 \ --save_steps 1000 \ --learning_rate 5e-5 \ --num_train_epochs 3.0 \ --plot_loss \ --fp16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 合并训练好的模型
–export_dir Qwen1.5-0.5B-Chat_fine 导出的位置要写对
CUDA_VISIBLE_DEVICES=0 python src/export_model.py \
--model_name_or_path Qwen/Qwen1.5-0.5B-Chat\
--adapter_name_or_path output \
--template qwen \
--finetuning_type lora \
--export_dir Qwen1.5-0.5B-Chat_fine \
--export_size 2 \
--export_legacy_format False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 运行模型
模型位置要写对,否则会报错。
from modelscope import AutoModelForCausalLM, AutoTokenizer device = "cuda" # the device to load the model onto model = AutoModelForCausalLM.from_pretrained( "/mnt/workspace/LLaMA-Factory/Qwen1.5-0.5B-Chat_fine", torch_dtype="auto", device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/LLaMA-Factory/Qwen1.5-0.5B-Chat_fine") prompt = "你好,纽约天怎么样?" messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt").to(device) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=512 ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
现在各种开源框架很多,训练起来不复杂,但是如果想训练一个可用的生产模型,还是要花一些时间的,可以比较一下训练前和训练后,模型对纽约天气的回答,大概率出现幻觉。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/空白诗007/article/detail/795164
推荐阅读
相关标签

