
- 1堆排序时间复杂度_排序算法(五)--堆排序
- 22023最新广西大学计算机电子信息考研复试之计算机网络和软件工程 828数据结构与程序设计上岸冲刺复试宝典(复试版/复试资料)_广西大学828历年真题
- 3史上最全Redis面试题(2024最新版),2024年最新靠着这份900多页的PDF面试整理_运维 redis面试
- 4快速访问github_快速访问github官网
- 5大数据分析常用工具有哪些?_大数据工具
- 6团队协作:如何利用 Gitee 实现多人合作项目的版本控制_gitee多人协作开发
- 7从论文到PPT,一键生成!从此报告不用愁!
- 8MAC实用贴 -- Mac OS安装软件时提示 “安装”已损坏,打不开 你应该推出磁盘映像的解决方法_“install”已损坏,无法打开。 您应该推出磁盘映像。
- 9开坑,深入理解jvm虚拟机系列_tlab和threadlocal区别
- 10【深度学习目标检测】十八、基于深度学习的人脸检测系统-含GUI和源码(python,yolov8)_运用yolov8训练人脸表情识别
大数据概论 (理论基础)_大数据理论基础
赞
踩
1 数据科学的学科地位
从学科定位看,数据科学处于数学与统计知识、黑客精神与技能和领域实务知识三大领域的重叠之处。
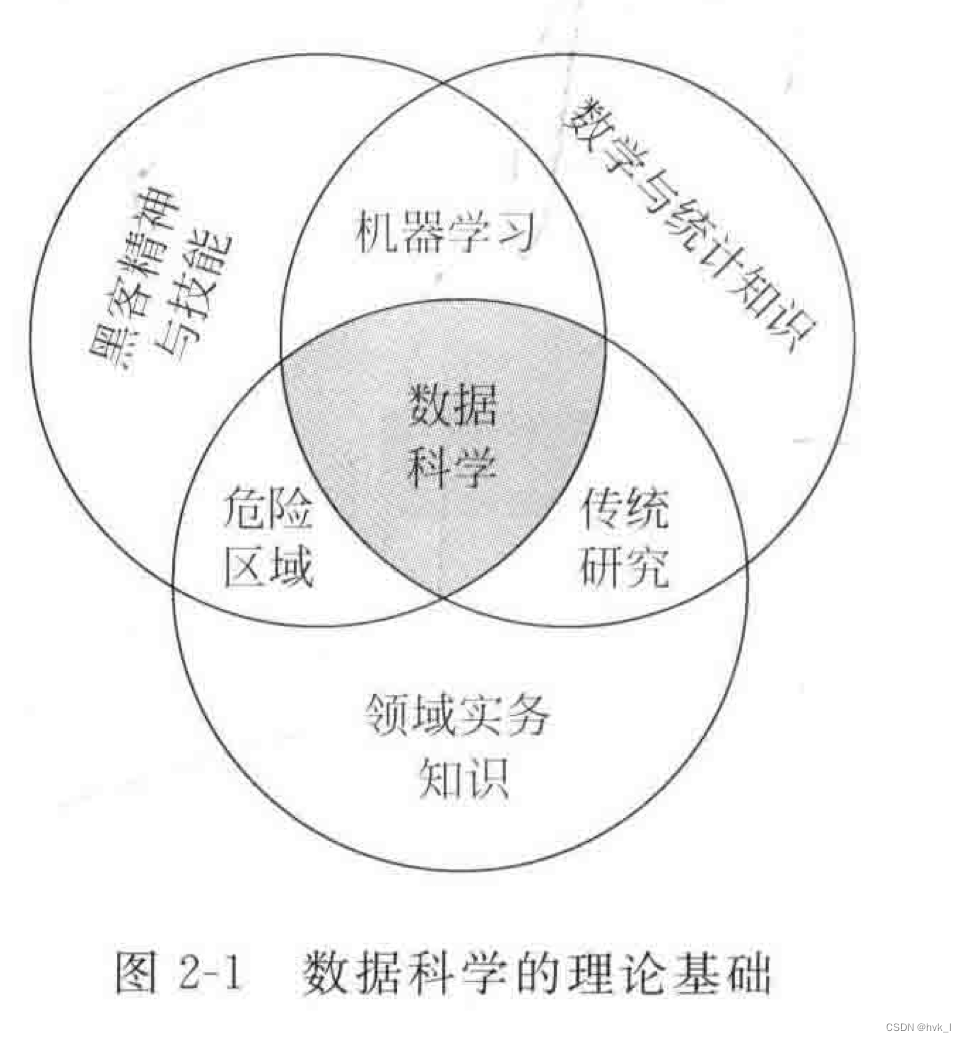
(1)“数学与统计知识”是数据科学的主要理论基础之一。
(2)“黑客精神与技能”是数据科学家的主要精神追求和技能要求一一大胆创新、喜欢挑战、追求完美和不断改进。
(3)“领域实务知识”是对数据科学家的特殊要求一一不仅需要掌握数学与统计知识以及具备黑客精神与技能,而且还需要精通某一个特定领域的实务知识与经验。
数据科学并不是以一个特定理论 (如统计学、机器学习和数据可视化) 为基础发展起来的,而是包括数学与统计学、计算机科学与技术、数据工程与知识工程、特定学科领域的理论在内的多个理论相互融合后形成的新兴学科。
2 统计学
2.1 统计学与数据科学
统计学是数据科学的主要理论基础之一。
2.2 数据科学中常用的统计学知识
1.从行为目的与思维方式看,统计方法可以分为两大类:描述统计和推断统计。
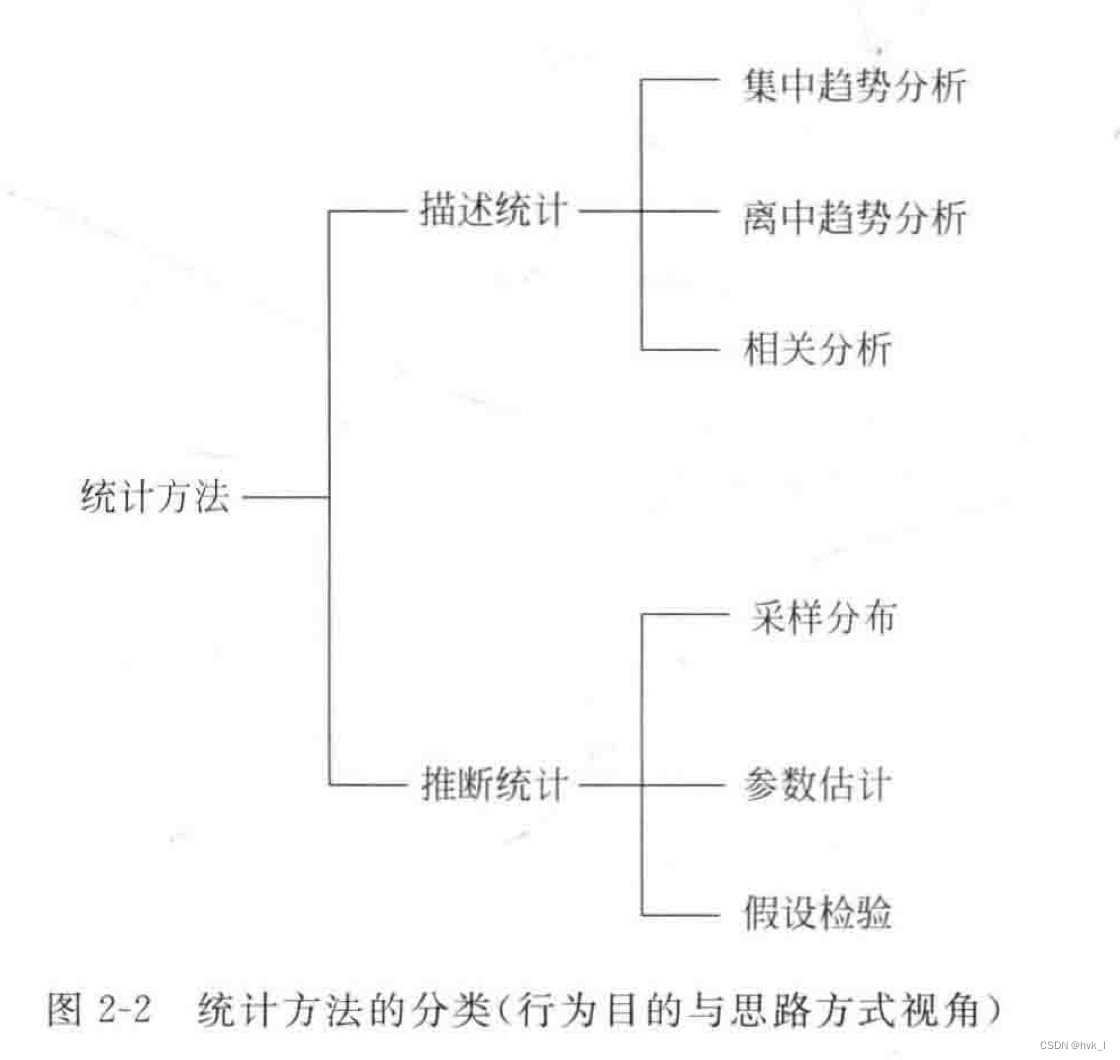
(1)描述统计
采用图表或数学方法描述数据的统计特征, 如分布状态、数值特征等。
- 集中趋势分析:数值平均数、位置平均数
- 离中趋势分析:极差、分位差、平均差、方差、标准差、离散系数
- 相关分析:正相关、负相关、线性相关、线性无关等
(2)推断统计
常用的推断方法有:参数估计和假设检验。
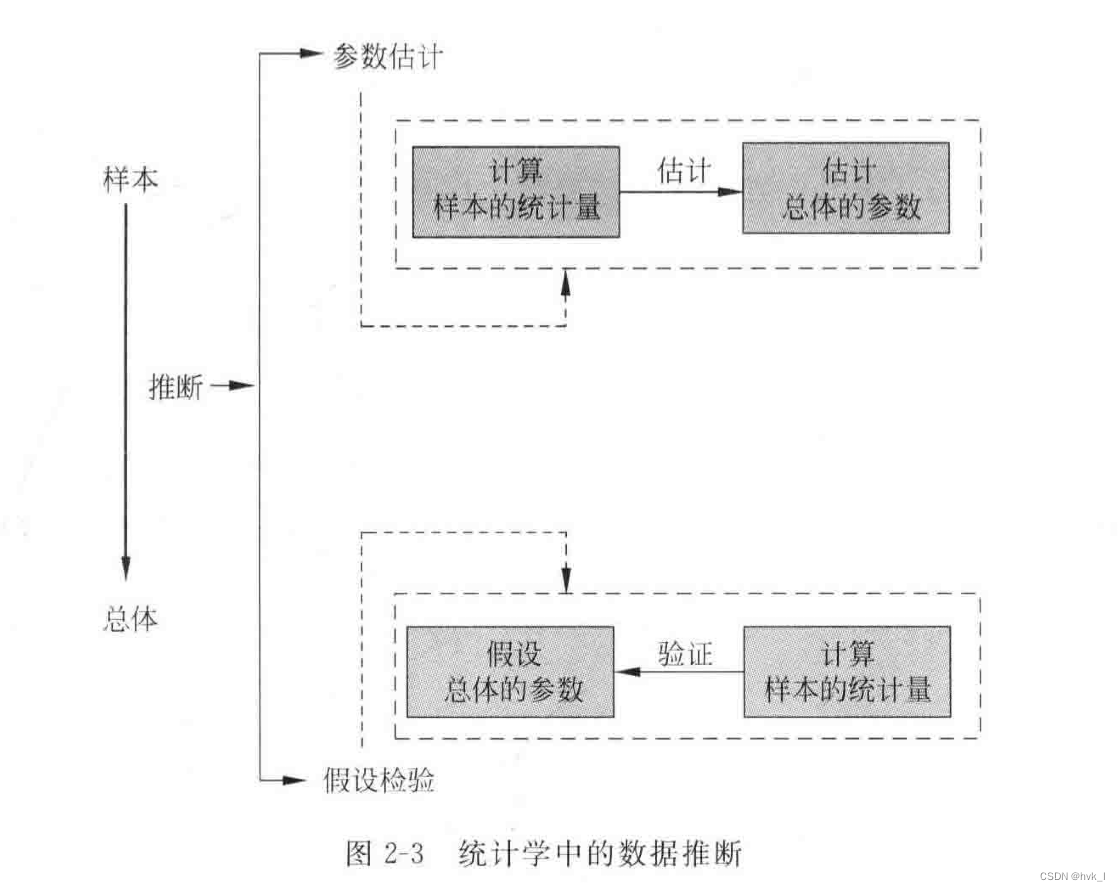
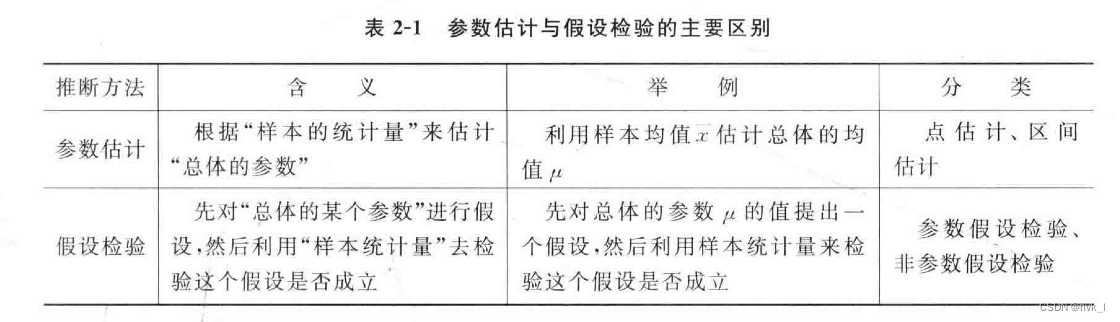
2.方法论角度
从方法论角度看,基于统计的数据分析方法又可分为:基本分析法和元分析法。
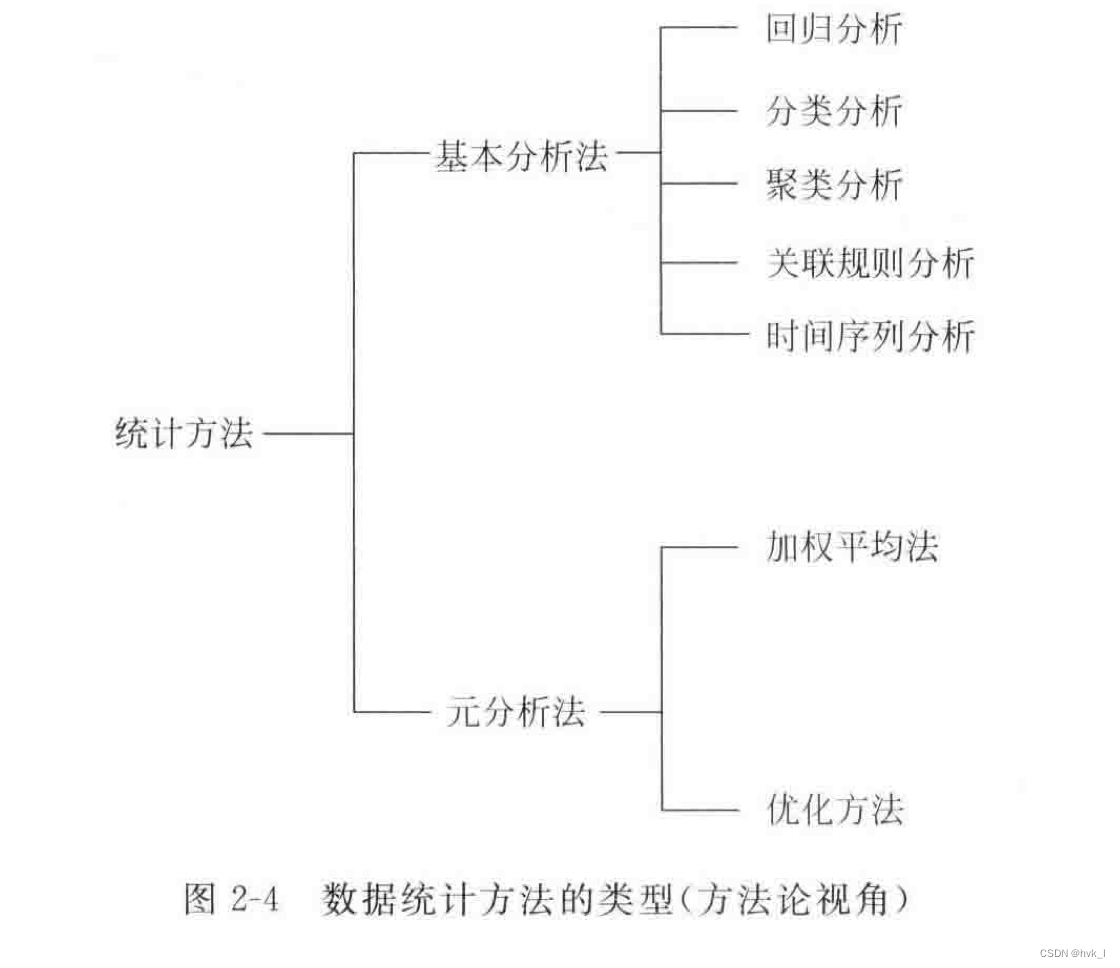
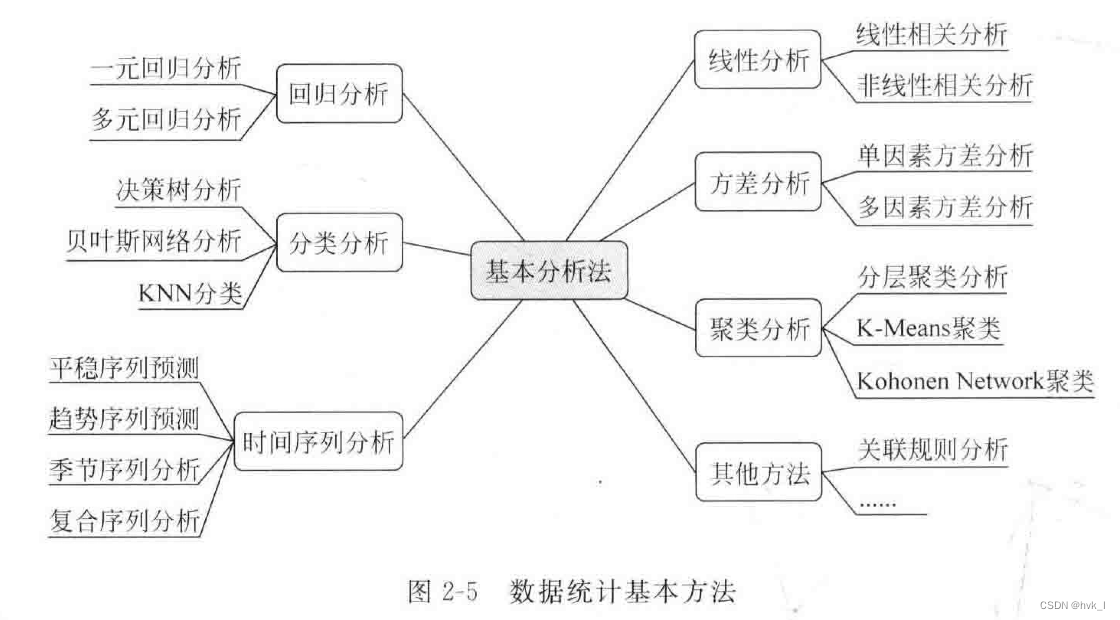
(1)基本分析法
- 用于对“低层数据(零次或一次数据)”进行统计分析的基本统计分析方法。
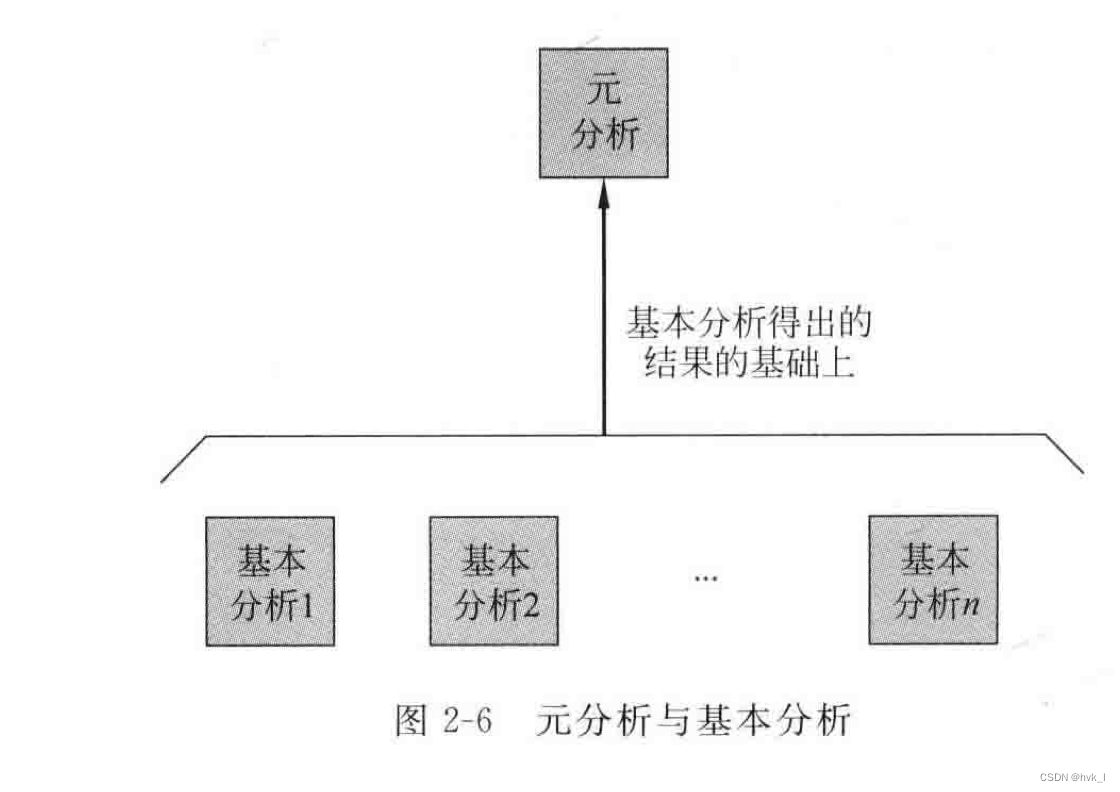
(2)元分析法
- 用于对“高层数据(二次或三次数据)”,尤其是对基本分析法得出的结果进行进一步分析的方法。
常用的元分析法:加权平均法和优化方法:
3.统计学在数据科学中的应用案例一一谷歌流感趋势分析
GFT出现预测不准确性的主要原因:
- 大数据浮夸( Big DataHubris):在没有拥有真正的“大数据”或没有掌握“大数据管理与分析能力”的情况下,人们对“大数据”寄予盲期望的现象。
- 算法动态性( Algorithm Dynamics)和用户使用行为习惯的进化
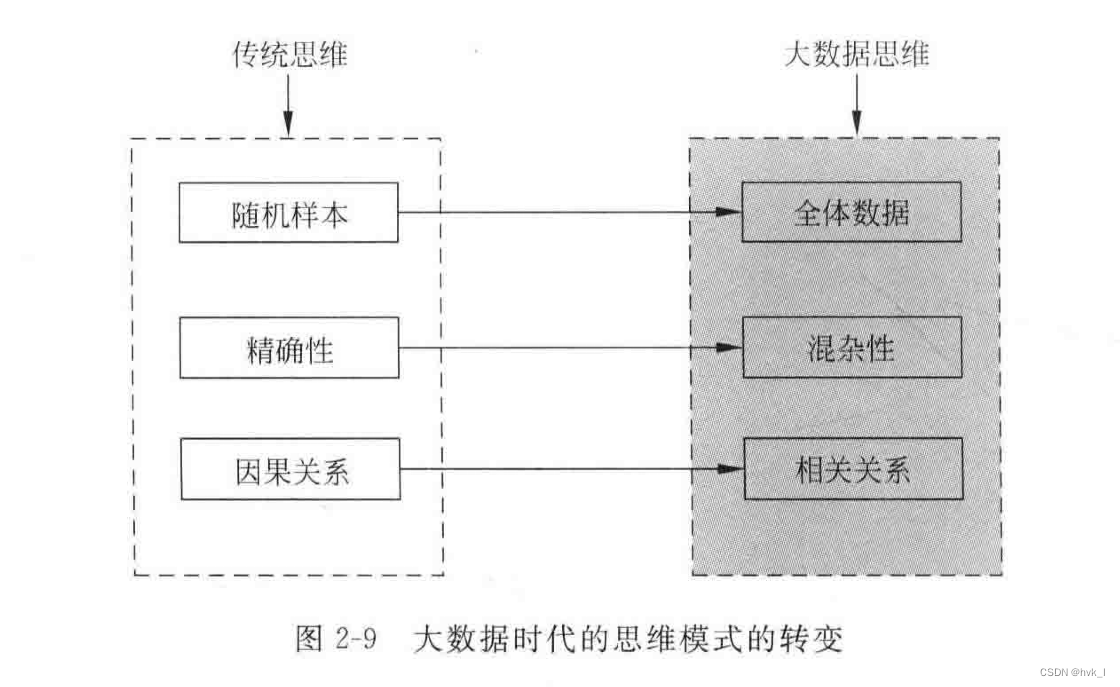
4.数据科学视角下的统计学
- 不是随机样本,而是全体数据
- 不是精确性,而是混杂性。
- 不是因果关系,而是相关关系
3 机器学习
3.1 机器学习与数据科学
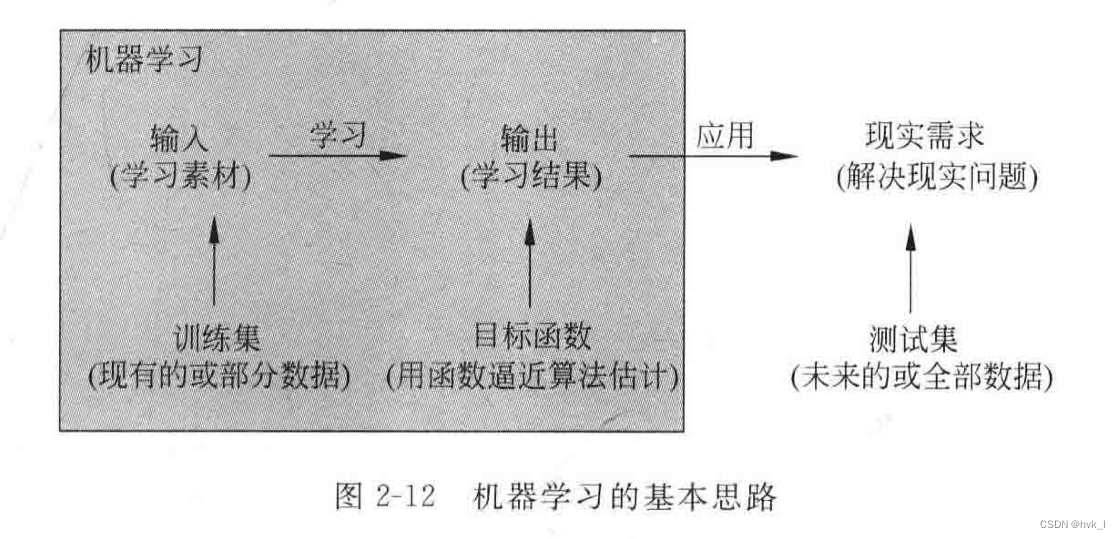
3.1.1 机器学习基本思路
以现有的部分数据(称为训练集)为学习素材(输入),通过特定的学习方法(机器学习算法),让机器学习到(输出)能够处理更多或未来数据的新能力(称为目标函数)
语法定义:
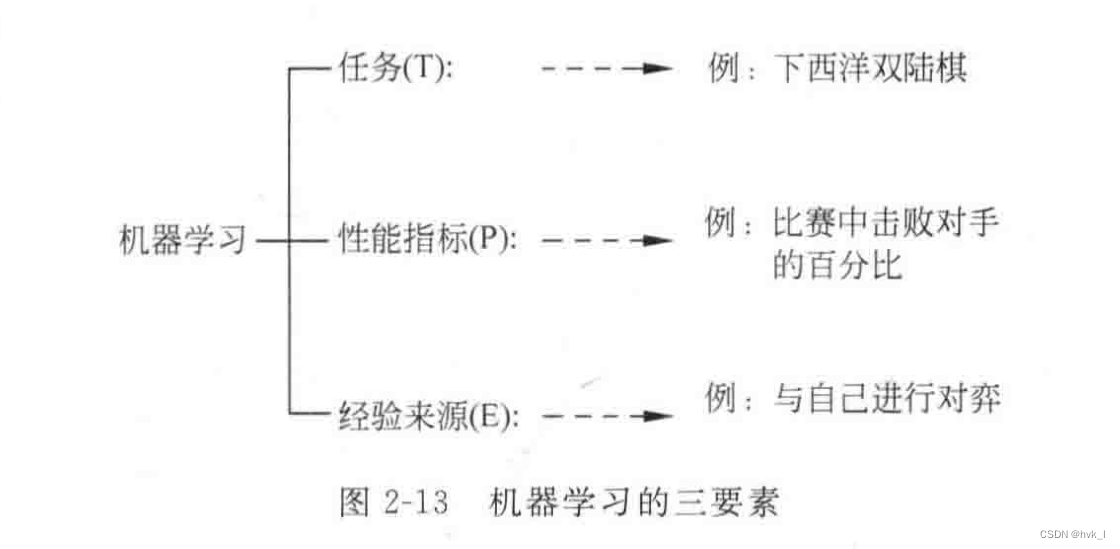
如果一个计算机系统在完成某一类任务T的性能P能够随着经验E而改进,则称该系统在从经验E中学习, 并将此系统称为一个学习系统。
关键组成要素:
相关学科:

3.1.2 数据科学中常用的机器学习知识
常用的机器类型:
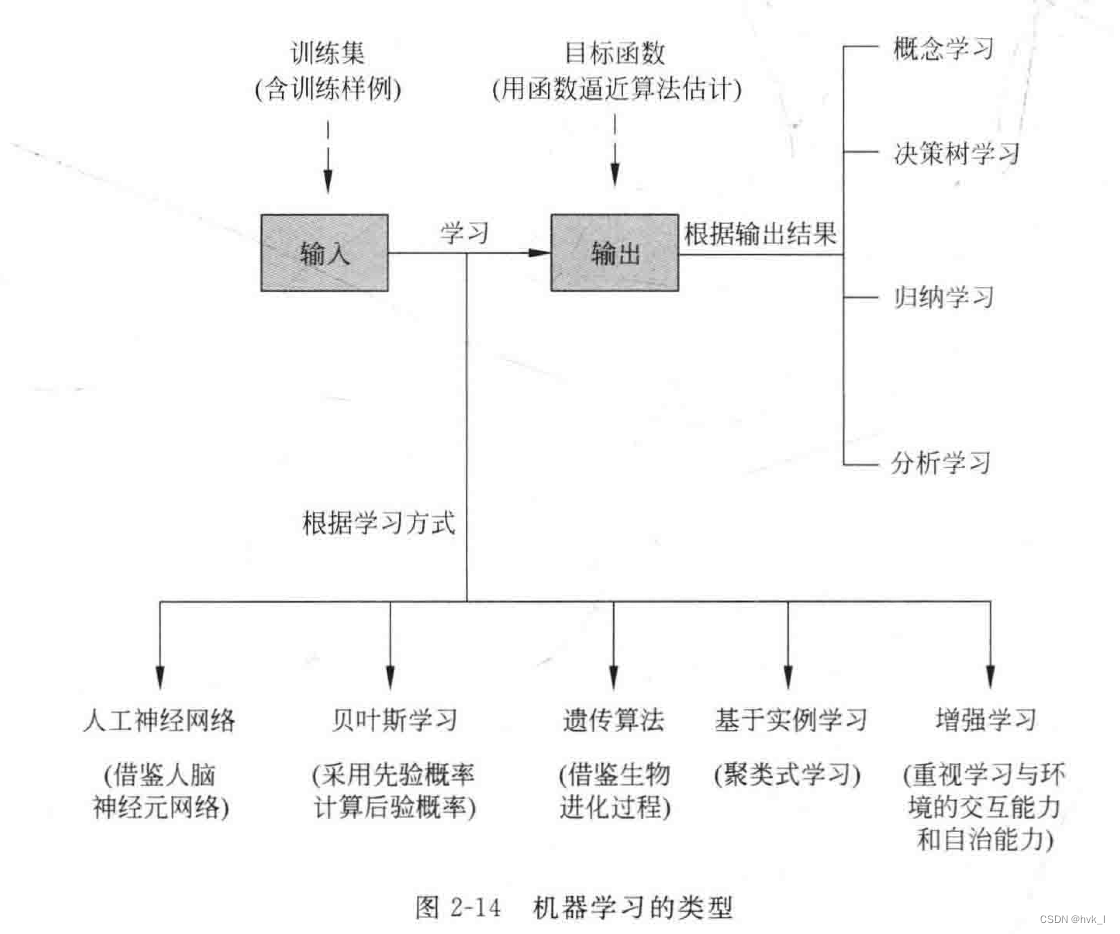
3.1.2.1 基于实例学习
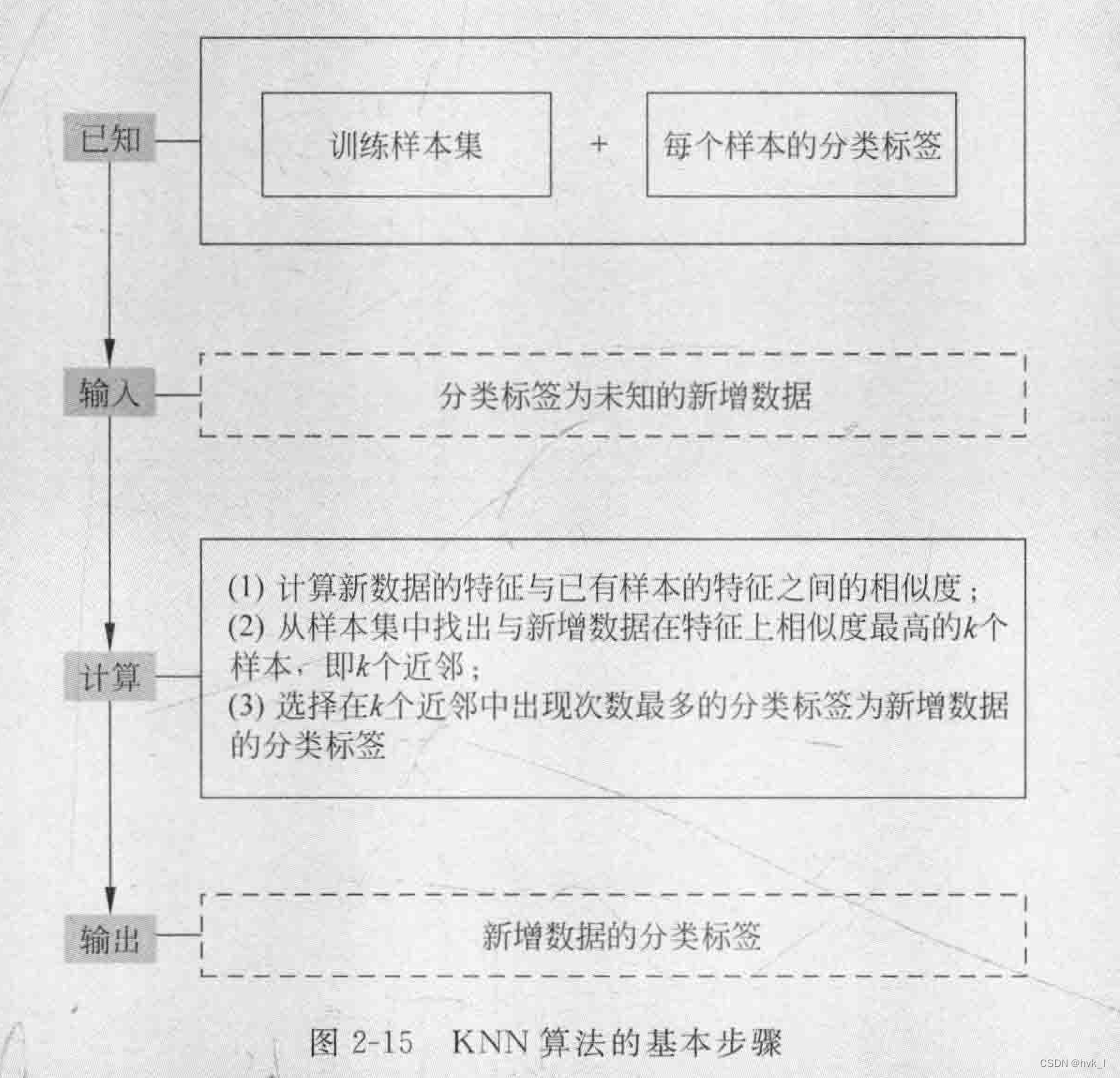
基本思路:事先将训练样本存储下来,然后每当遇到一个新增査询实例时,学习系统分析此新增实例与以前存储的实例之间的关系, 并据此把一个目标函数值赋给新增实例
常用方法:
- K近邻方法、局部加权回归法、基于案例的推理
- KNN(K- Nearest Neighbor,K近部)算法
3.1.2.2 概念学习
本质:从有关某个布尔函数的输入输出训练样本中推算出该布尔函数。
“在已知的样本集合以及每个样本是否属于某一概念的标注的前提下,推断出该概念的一般定义”的问题。
具体方法:Find-s 算法、侯选消除算法等
3.1.2.3 决策树学习
本质:是一种逼近离散值目标函数的过程。
- 根节点:代表分类的开始。
- 叶节点:代表一个实例的结。
- 中间节点:代表相应实例的某一个属性、
- 节点之间的边:代表某一个属性的属性值。
- 从根节点到叶节点的每条路径:代表一个具体的实例,同一个路径上的所有属性之间是“逻辑与”关系。
核心算法:ID3算法
3.1.2.4 人工神经网络学习
人工神经元
- 实现人工神经元的方法
- 感知器( Perceptron)、线性单元( Linear Unit)和 Sigmoid单元( Sigmoid Unit)等。
- 根据连接方式不同,通常把人工神经网络分为
- 无反馈的前向神经网络
- 相互连接型网络(反馈网络)
深度学习的关键在于计算观测数据的分层特征及其表示,其中高层特征或因子由底层得到。深度学习可以进一步分为:
• 无监督和生成式学习深度网络:深度置信网络( Deep Belief Network,DBN)、受限玻尔兹曼机( Restricted Boltzmann Machine,RBM)以及和积网络(Sum Product Network,SPN)等。
• 监督学习深度网络:卷积神经网络( Convolutional Neural Network,CN)、层级时间记忆模型( Hierarchical Temporal Memory,HTM)等。
• 混合深度网络:生成式DBN预训练CN,即 deep-cnn
3.1.2.5 贝叶斯学习
贝叶斯概率引入先验知识和逻辑推理来处理不确定命题。
朴素贝叶斯分类器( Naive Bayes Classifier)
- 一个简单的假定基础:在给定“目标值”时,“属性值”之间互为“条件独立”。
3.1.2.6 遗传算法
主要研究的问题:
从候选假设空间中搜索出最佳假设:“最佳假设”指“适应度( Fitness)”指标为最优的假设。
- 实现方式:共同结构
- 遗传算法的总体
- 三个基本算子
- 选择、交又和突变
3.1.2.7 分析学习
特点:使用先验知识来分析或解释每个训练样本,以推理出样本的哪些特征与目标函数相关或不相关。


3.1.2.8 增强学习
(1)主要研究:
- 如何协助自治 Agent的学习活动,进而达到选择最优动作的目的。
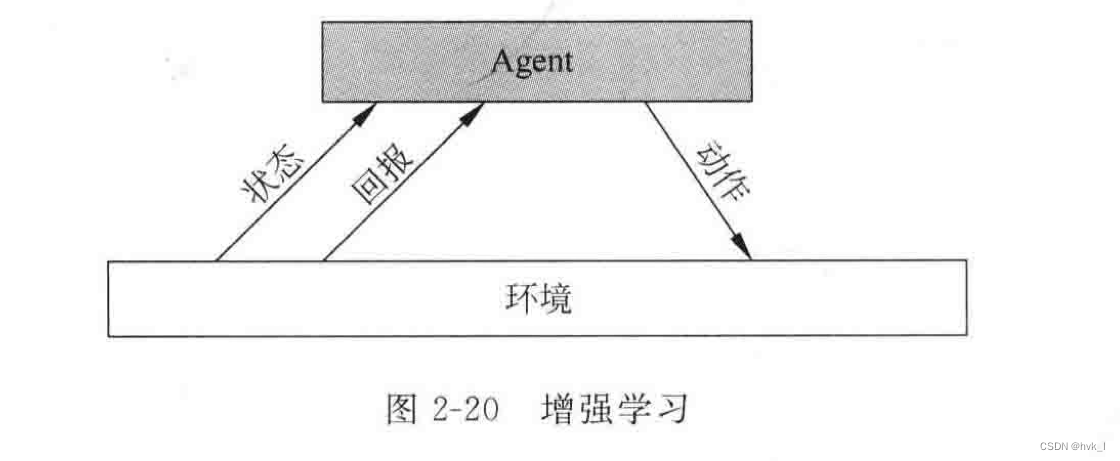
(2)基本思路
- 当 Agent在其环境中做出每个动作时,施教者会提供奖赏或惩罚信息,以表示结果状态的正确与否。
- Agent的任务从这些有延迟的回报中学习“控制策略”,以便后续的动作产生最大的累积回报。
控制策略的学习问题形式化表示方法: 基于马尔可夫决策过程定义方法
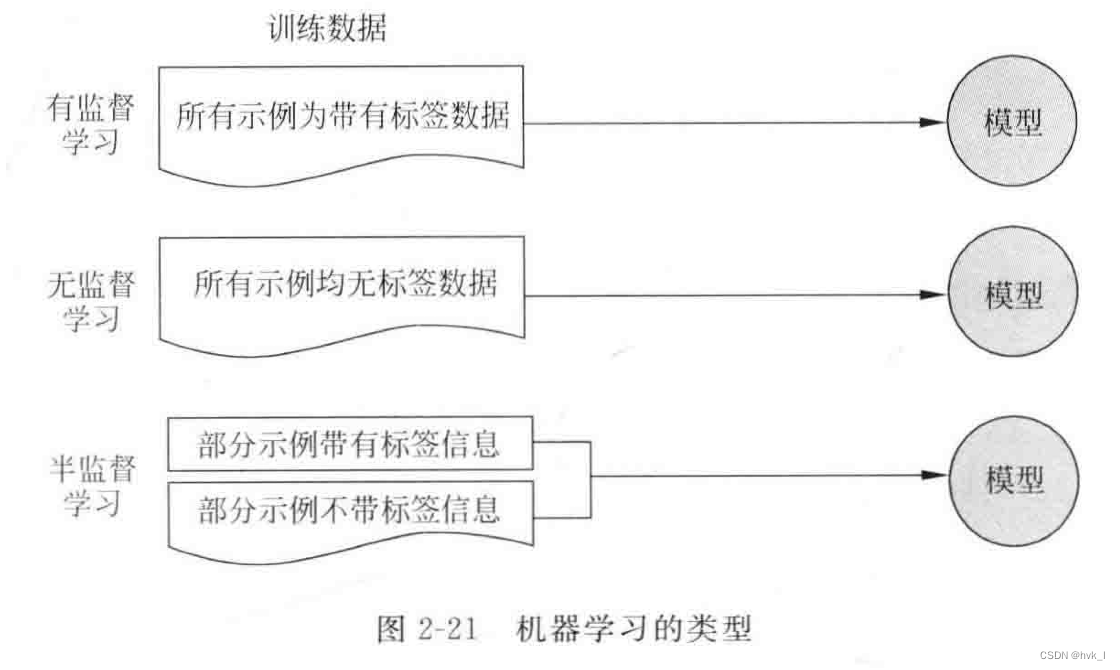
根据学习任务的不同,机器学习算法分为:
- 监督学习( Supervised Learning):最近邻( Nearest Neighbor)、朴素贝叶斯、决策树、随机森林、线性回归、支持向量机和神经网络分析等算法
- 无监督学习(Unsupervised Learning):K- Means聚类、主成分分析、关联规则分析等
- 半监督学习
3.2 机器学习在数据科学中的应用
3.3 数据科学视角下的机器学习
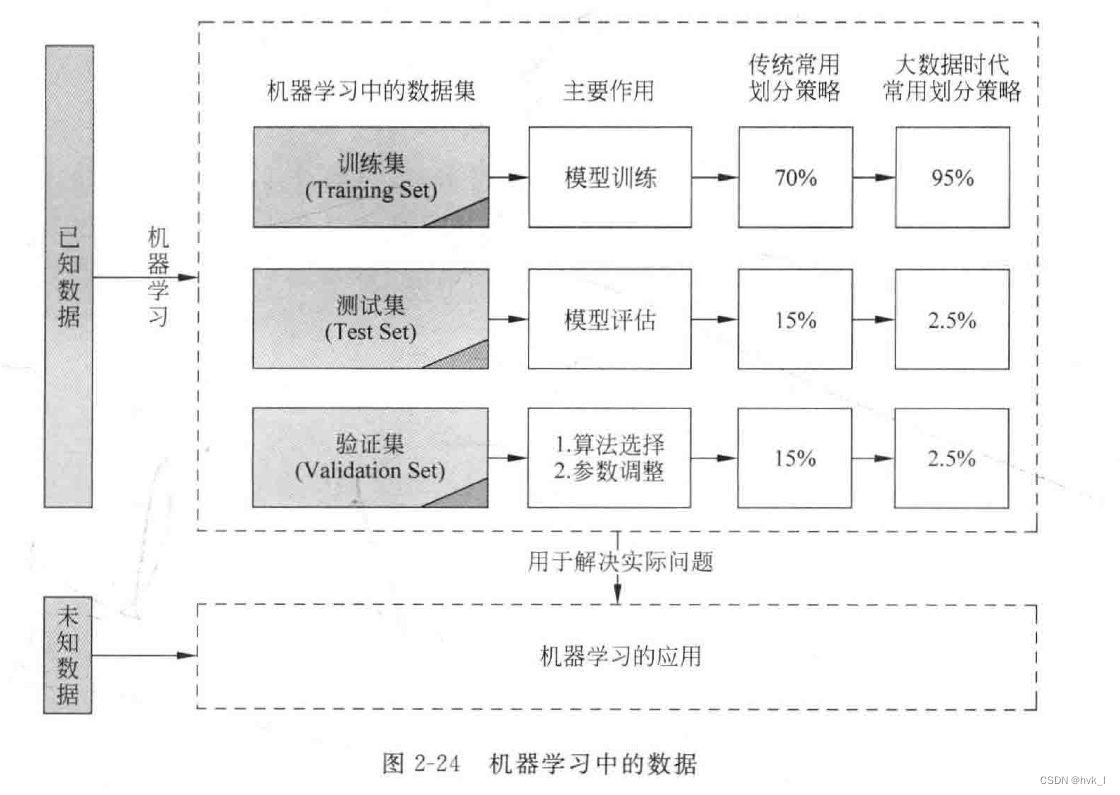
机器学习领域所面临的主要挑战:
- 过拟合( Overfitting)
- 维度灾难( Curse of Dimensionality)
- 特征工程( Feature Engineering)
- 算法的可扩展性( Scalability):机器学习算法的可扩展性不仅要考虑硬件(如内存、CPU等)和软件(如跨操作系统、跨平台等)上的扩展性,而且还需要重视训练集上的可扩展性。
- 模型集成( Model Ensemble)
数据科学中常用的统计模型与机器学算法:
1.常用统计模型
2.核心机器学习算法
4 数据可视化
重要地位主要表现:
(1)视觉是人类获得信息的最主要途径。
(2)相对于统计分析,数据可视化的主要优势体现在两个方面。
- 数据可视化处理可以洞察统计分析无法发现的结构和细节。
- 数据可视化处理结果的解读对用户知识水平的要求较低。
(3)可视化能够帮助人们提高理解与处理数据的效率。
总结
1.数据科学视角下的统计学
- 不是随机样本,而是全体数据
- 不是精确性,而是混杂性。
- 不是因果关系,而是相关关系
2.数据科学视角下的机器学习
机器学习领域所面临的主要挑战:
- 过拟合( Overfitting)
- 维度灾难( Curse of Dimensionality)
- 特征工程( Feature Engineering)
- 算法的可扩展性( Scalability):机器学习算法的可扩展性不仅要考虑硬件(如内存、CPU等)和软件(如跨操作系统、跨平台等)上的扩展性,而且还需要重视训练集上的可扩展性。
- 模型集成( Model Ensemble)
机器学习是数据分析的重要手段,也是数据科学家的重要方法之一。数据科学家不仅需要深入学习机器学习的知识,而且还应以大数据处理为背景将机器学习、数据挖掘、统计学、数据可视化、数据存储和数据计算的知识融合起来。
3.机器学习、统计学、数据可视化的区别和联系:
(1) 统计学和机器学习:
区别:统计学需要事先对处理对象(数据)的概率分布做出假定(如正态分布等),而机器学习则不需要做事先判断;统计学通过各种统计指标(如R方、置信区间等)来评价统计模型(如线性回归模型)的你和优度,而机器学习通过交叉验证或划分训练集和测试集的方法评价算法的准确度。
联系:从理论和方法的角度看,统计学的方法可以应用于机器学习,反之亦然。
(2) 机器学习和数据可视化:
区别:从数据分析的角度去看的话, 两者都是属于数据分析的工具,只是彼此从不同的角度去看数据。机器学习是从模型的角度,数据可视化是从图像的角度。
联系:前者是对复杂模型进行机器学习,通过可视化手段展示结果;后者是可视化中经常需要对数据进行筛选和整理才能更好的做出合理的可视化手段。

