
热门标签
热门文章
- 1NLP实用小工具Tokenizer和pad_sequences进行文本的数字编码和长度填充或截断_tokenizer 统计特征的长度
- 2vue项目基于WebRTC实现一对一音视频通话_vue实战 1-1 webrtc点对点语音视频通话
- 3ADS仿真工具使用_ads仿真软件
- 4真实遇到的产品经理面试题
- 5【AI 大模型】提示工程 ① ( 通用人工智能 和 专用人工智能 | 掌握 提示工程 的优势 | 提示工程目的 | 提示词组成、迭代、调优及示例 | 思维链 | 启用思维链的指令 | 思维链原理 )_ai 提示词工程
- 6Item2vec_movielens item2vec
- 7JS常用方法_数组对象元素保留某些属性
- 8海康视觉平台VisionMaster使用学习笔记(1)_visionmaster图像源怎么连接相机
- 9【Pytorch】学习记录分享8——自然语言处理基础-词向量模型Word2Vec_pytorch word2vec
- 10⛳ TCP 协议详解
当前位置: article > 正文
大模型训练流程(一)预训练_大模型预训练
作者:空白诗007 | 2024-06-27 05:32:36
赞
踩
大模型预训练
预训练GPU内存分析:
GPU占用内存 = 模型权重 + 梯度 + 优化器内存(动量估计和梯度方差) + 中间激活值*batchsize + GPU初始化内存
训练流程
(选基座 —> 扩词表 —> 采样&切分数据 —> 设置学习参数 —> 训练 —> 能力测评)
https://zhuanlan.zhihu.com/p/636270877
1.选择一个预训练的模型基座
大部分优秀的语言模型都没有进行充分的中文预训练,因此,许多工作都尝试将在英语上表现比较优秀的模型用中文语料进行二次预训练。比如:[Chinese-LLaMA-Alpaca]。
2.Tokenizer Training
2.1 tokenizer 是将一句话进行切词并转化成模型可以学习的数字格式
tokenizer 有 2 种常用形式:WordPiece 和 BPE。
-
WordPiece:将所有的「常用字」和「常用词」都存到词表中,当需要切词的时候就从词表里面查找即可。BERT 就使用的这种切词法。
当遇到词表中不存在的字词时,tokenizer 会将其标记为特殊的字符 [UNK] -
Byte-level BPE(BBPE):按照 unicode 编码作为最小粒度。对于中文来讲,一个汉字是由 3 个 unicode 编码组成的(LLaMA 的 tokenizer 对中文就是如此)
能用unicode表示的汉字都可以训练,但模型需要通过充分学习来知道合法的 unicode 序列。当训练不充分则会出现乱码(不合法的 unicode 序列)
2.2 词表扩充
为了降低模型的训练难度,将一些常见的汉字 token 手动添加到原来的 tokenizer 中。
- Chinese LLaMA 在原始 tokenizer 上新增了17953 个 tokens,且加入 token 的大部分为汉字。
- BELLE 在 120w 行中文文本上训练出一个 5w 规模的 token 集合,并将这部分 token 集合与原来的 LLaMA
词表做合并,最后再在 3.2B 的中文语料上对这部分新扩展的 token embedding 做二次预训练。
3.预训练
输入语料让大模型进行Next Token Prediction 任务
3.1数据处理
- 开源数据集可以用于实验,如果想突破性能,则需要我们自己进行数据集构建。
- 在 Finetune 任务中,我们通常会直接使用 truncation 将超过阈值(2048)的文本给截断,但在 Pretrain 任务中为了让模型充分提高语言的连贯能力,是将长文章按照 seq_len(2048)作分割,将切割后的向量喂给模型做训练。
- 对不同的数据源会选择不同采样比,相对较大的数据集会使用相对较大的采样比例,使得模型不会太偏向于规模较大的数据集,从而失去对规模小但作用大的数据集上的学习信息。
3.2 Warmup & Learning Ratio 设置
在继续预训练中,我们通常会使用 warmup 策略,此时我们按照 2 种不同情况划分:
- 当训练资源充足时,应尽可能选择较大的学习率以更好的适配下游任务;
- 当资源不充足时,更小的学习率和更长的预热步数或许是个更好的选择。
4. 模型效果测评
- 采用[PPL],[BPC] 评估模型对于生成结果和目标文本的拟合程度,测评生成流畅和通顺语句能力。
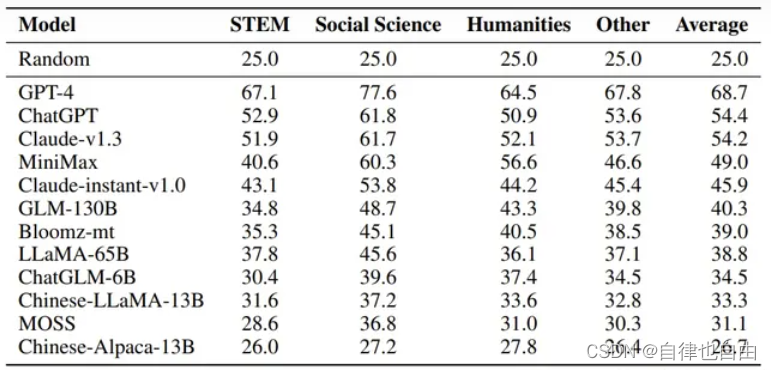
- 测评模型知识蕴含能力,中文知识能力测试数据集是 [C-Eval],涵盖1.4w 道选择题,共 52 个学科。将题目写进 prompt 中,并让模型续写 1 个 token,判断这个续写 token 的答案是不是正确答案。使用 Five-shot 的方式给模型提供五个问答样例来让模型知道如何输出答案。
Five-shot评分:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/空白诗007/article/detail/761447
推荐阅读
相关标签

