
- 1深度学习评价标准:TP、FN、FP、TN、AP、MAP_tp5 fn
- 2【海思SS626 | VB】关于 视频缓存池 的理解
- 3Vue项目通过宝塔部署之后,页面刷新后浏览器404页面。_宝塔面板404
- 4RabbitMQ的四种交换器以及死信队列介绍_rabbitmq多个交换机共享消息队列
- 5Github Copilot 用账号登录,完美支持chat,不妨试试_copilot账号
- 6【开发环境搭建篇】NodeJS版本管理工具NVM的安装和配置_node版本管理工具
- 7基于S3C6410的ARM11学习(三) 核心初始化之设置中断向量表_arm 初始化中断向量
- 8python训练模型报错:BrokenPipeError: [Errno 32] Broken pipe_python print方法 valueerror:
- 9区块链开源的项目有哪些?_开源区块链
- 10如何实现数据库的优化_数据库结构如何优化
基于python的分类预测_机器学习算法(五): 基于支持向量机的分类预测
赞
踩
声明:本次撰写以Datawhale团队提供的学习材料以自学为主,代码为Datawhale团队提供,利用阿里云天池实验室与编辑器pycharm完成测试。
支持向量机(Support Vector Machine,SVM)是一个非常优雅的算法,具有非常完善的数学理论,常用于数据分类,也可以用于数据的回归预测中,由于其优美的理论保证和利用核函数对于线性不可分问题的处理技巧, 在上世纪90年代左右,SVM曾红极一时。 本文将不涉及非常严格和复杂的理论知识,力求于通过直觉来感受 SVM。
Demo实践Step1:库函数导入 Step2:构建数据集并进行模型训练 Step3:模型参数查看 Step4:模型预测 Step5:模型可视化学习目标
*了解支持向量机的分类标准;
*了解支持向量机的软间隔分类;
*了解支持向量机的非线性核函数分类;
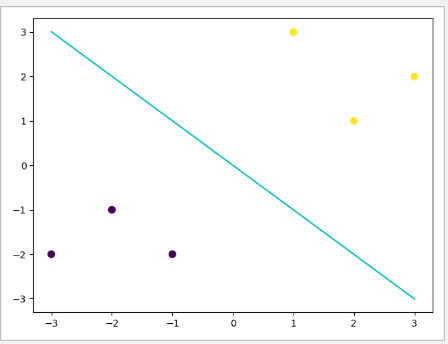
可以对照之前的逻辑回归模型的决策边界,我们可以发现两个决策边界是有一定差异的(可以对比两者在X,Y轴 上的截距),这说明这两个不同在相同数据集上找到的判别线是不同的,而这不同的原因其实是由于两者选择的 最优目标是不一致的。接下来我们进行SVM的一些简单介绍。支持向量机的介绍
我们常常会碰到这样的一个问题,首先给你一些分属于两个类别的数据
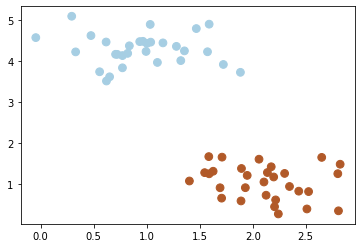
现在需要一个线性分类器,将这些数据分开来。
我们可能会有多种分法:
那么现在有一个问题,两个分类器,哪一个更好呢?
为了判断好坏,我们需要引入一个准则:好的分类器不仅仅是能够很好的分开已有的数据集,还能对未知数据集 进行两个的划分。
假设,现在有一个属于红色数据点的新数据(3, 2.8)
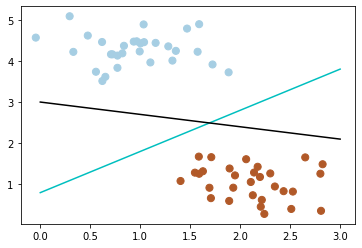
可以看到,此时黑色的线会把这个新的数据集分错,而蓝色的线不会。
我们刚刚举的例子可能会带有一些主观性。
那么如何客观的评判两条线的健壮性呢?
此时,我们需要引入一个非常重要的概念:最大间隔。
最大间隔刻画着当前分类器与数据集的边界,以这两个分类器为例:
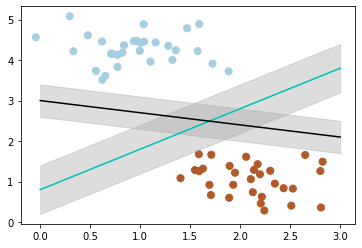
可以看到, 蓝色的线最大间隔是大于黑色的线的。
所以我们会选择蓝色的线作为我们的分类器。


