
- 1数据结构-常见排序的七大排序
- 2Android 在项目中使用 JiaoZiVideoPlayer 开源框架集成视频播放功能_jzmediaijk
- 3区块链+大数据+人工智能赋能白酒溯源防伪体系_酒的溯源系统如何实现
- 4[ 常用工具篇 ] burpsuite_pro 安装配置详解(附安装包)_burpsuite pro
- 5Vue3利用vue-plugin-hiprint插件实现无预览打印(静默打印)_vue3 hiprint
- 6【N年测试总结】 测试入职一家新公司的工作开展思路_测试进入一家新的公司怎么开展
- 7《学会 SpringMVC 系列 · 剖析出参处理》
- 8Redis-管道
- 9Go语言实现区块链(三)_go语言海鲜区块链系统的数据库 csdn
- 10开源威胁情报
人脸识别(Arcface模型)改进_facenet的改进模型
赞
踩
本文档主要记录对Arcface模型改进过程中所学习到的知识。
1.人脸识别发展历程
- 2014年DeepFace和DeepID系列都是主要先训练Softmax多分类器人脸识别框架;然后抽取特征层,用特征再训练另一个神经网络、孪生网络或组合贝叶斯等人脸验证框架。想同时拥有人脸验证和人脸识别系统,需要分开训练两个神经网络。但线性变换矩阵W的大小随着身份数量n的增加而线性增大。
- DeepFace、DeepID框架为 CNN+Softmax,网络在第一个FC层形成判别力很强的人脸特征,用于人脸识别。
- DeepID2、DeepID2+、DeepID3都采用 CNN+Softmax+Contrastive Loss,使得同类特征的L2距离尽可能小,不同类特征的L2距离大于某个间隔。
- 2015年FaceNet提出了一个绝大部分人脸问题的统一解决框架,直接学习嵌入特征,然后人脸识别、人脸验证和人脸聚类等都基于这个特征来做。FaceNet在 DeepID2 的基础上,抛弃了分类层,再将 Contrastive Loss 改进为 Triplet Loss,获得类内紧凑和类间差异。但人脸三元组的数量出现爆炸式增长,特别是对于大型数据集,导致迭代次数显著增加;样本挖掘策略造成很难有效的进行模型的训练。
- 2017年《In Defense of the Triplet Loss for Person Re-Identification》提出了 Soft-Margin 损失公式替代原始的 Triplet Loss 表达式,并引进了 Batch Hard Sampling。
- 2017年Wu, C等从导函数角度解释了为什么 Non-squared Distance 比 Squared-distance 好,并在这个 insight 基础上提出了 Margin Based Loss。此外,他们还提出了 Distance Weighted Sampling。文章认为 FaceNet 中的 Semi-hard Sampling,Deep Face Recognition 中的 Random Hard 和 Batch Hard 都不能轻易取到会产生大梯度(大 loss,即对模型训练有帮助的 triplets)。
- 2015年VGGNet为了加速 Triplet Loss 的训练,先用传统的 softmax 训练人脸识别模型,因为 Classficiation 信号的强监督特性,模型会很快拟合;之后移除Classificiation Layer,用 Triplet Loss 对模型进行特征层 finetune。
- 2016年Center Loss为每个类别学习一个中心,并将每个类别的所有特征向量拉向对应类别中心,根据每个特征向量与其类别中心之间的欧几里得距离,以获得类内紧度;而类间分散则由Softmax loss 的联合惩罚来保证。然而,在训练期间更新实际类别中心非常困难,因为可供训练的人脸类别数量最近急剧增加。
- 2017年COCO Loss,归一化了权值c,归一化了特征f,并乘尺度因子,在LFW上达到99.86%;
- 2017年SphereFace提出A-Softmax,是L-Softmax的改进,提出了角度间隔惩罚,又归一化了权值W,让训练更加集中在优化深度特征映射和特征向量角度上,降低样本数量不均衡问题。
- 《Learning towards minimum hyperspherical energy》又说了它的损失函数需要一系列近似才能计算出来,从而导致网络训练不稳定。为了稳定训练,他们提出混合Softmax loss损失函数,经验上,softmax loss 在训练过程中占主导地位,因为基于整数的乘性角度间隔使得目标逻辑曲线非常陡峭,从而阻碍了收敛。
- 2018年ArcFace提出加性角度间隔损失,θ+m,还归一化特征向量和权重,几何上有恒定的线性角度margen。直接优化弧度,为了性能的稳定,ArcFace不需要与其他loss函数实现联合监督。
- 2018年MobileFaceNets,MobileNetV2+ArcFace Loss,轻量化模型。
- 2019年AdaFace引入了自适应特征正则化的方法,根据样本的难度动态调整正则化强度,从而提高了对困难样本的处理能力,并提升了模型的鲁棒性,特别是在处理复杂背景和光照变化时表现出色。
- PFE将人脸嵌入表示为概率分布而不是确定值,通过将不确定性纳入考虑,提升了模型在不同条件下的表现。
- 2020年CurricularFace提出了一种课程学习策略,通过逐步增加训练样本的难度,提高了模型的学习效率和识别性能。
- 2021年AFS (Attention-aware Face Super-Resolution)利用注意力机制对低分辨率人脸图像进行超分辨率重建,提升了低质量图像的人脸识别性能。
- Partial FC (Partial Fully Connected Layer)通过减少全连接层的计算量,显著提升了训练速度和内存效率,同时保持了高识别准确率。提高了大规模人脸识别训练的效率,适用于大数据集和大模型的训练。
- 2022年SAM (Self-Attention Mechanism)SAM将自注意力机制应用于人脸识别,通过捕捉全局上下文信息,提高了特征提取的准确性和鲁棒性。
- FairFace++致力于解决人脸识别中的公平性问题,提出了改进的数据采集和训练方法,减少了算法对不同种族和性别的偏见。
-
2023年EfficientFace采用了一系列模型压缩和加速技术,如量化、剪枝和蒸馏,使得人脸识别模型在移动设备和边缘设备上运行更加高效。提升了模型的运行效率和实时性,适用于资源受限的应用场景。
2.Arcface模型分析
2.1 网络结构
Arcface网络的输入是H*W*3的图片,输出为512维的特征向量,其网络结构主要模块为:
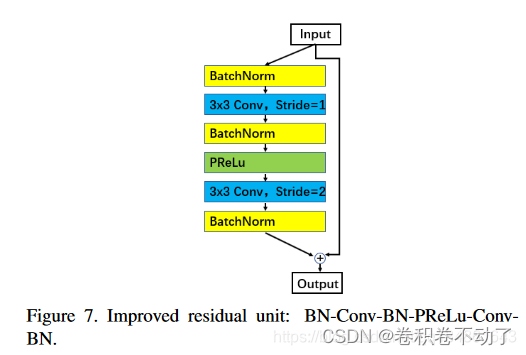
主干网络通过多个上述模块堆叠,输出512维特征向量。
2.2 Arcface损失函数
在此之前常用的softmax损失函数:
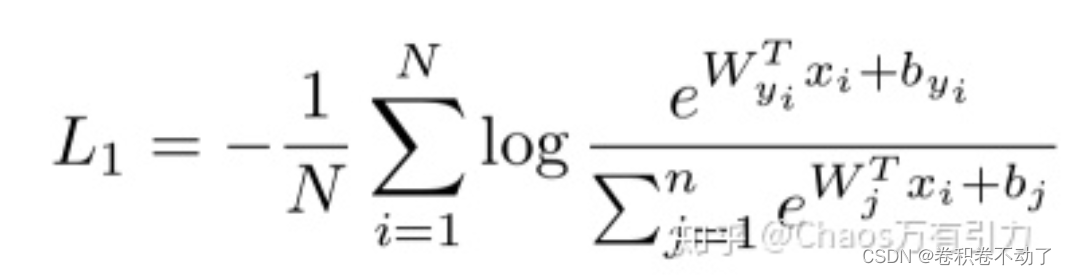
其中为第i个样本的输出特征,真实的分类为第
类,
为最后一层全连接层的权重中第
列,
为最后全连接层的偏置,
为最后一层全连接层的权重中第
列,m 为批量数,n为类别数。Softmax损失函数没有明确优化特征以使正对样本的相似性得分更高,而负对样本的相似性得分更低,导致该损失函数在人脸识别中性能存在明显瓶颈。
Arcface在softmax损失函数的基础上进行改进,根据向量乘法的定义:

通过L2归一化固定,固定
并重新缩放到s,通过该方法简化计算,损失函数中仅取决于特征向量和权重之间的角度。在
中添加一个角度余量
,由于
小于
,当
时,Arcface损失函数为:
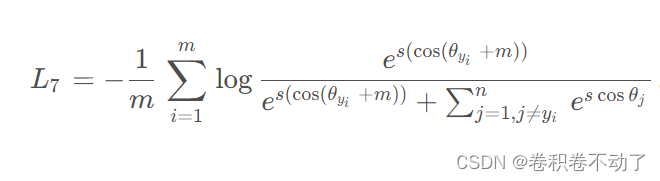
其中的约束条件为:
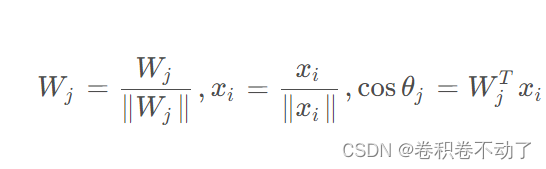
实际上Arcface的损失函数遵循增大类间距离,减小类内距离的原则,角度余量起到增大类间边际距离的作用,分类效果如下所示:
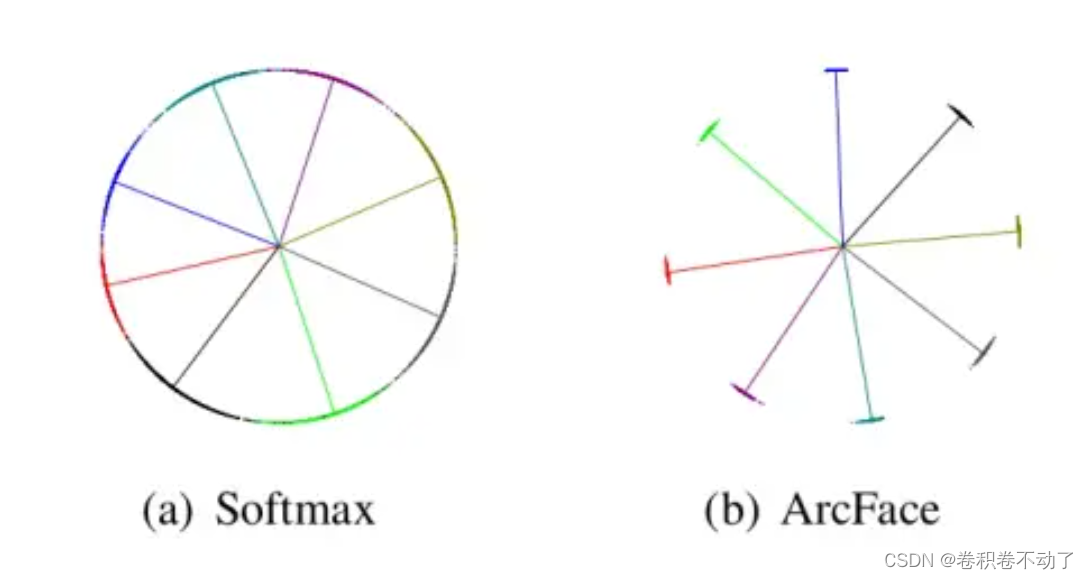
Softmgeax损失函数的目的是为了找出各类的分界,而Arcface的损失函数的优化目标是为了尽可能的增大类间距离,将不同类按照一定距离区分开来。
3.Arcface改进实验记录
3.1 替换Backbone
3.1.1 更改Backbone为fasternet
fasternet 论文:https://arxiv.org/abs/2303.03667
相关博客:【CVPR 2023】FasterNet论文详解_cvpr2023 fasternet-CSDN博客
针对特征提取中各通道的特征图具有高度相似性,存在计算冗余的问题,作者提出一种新型的卷积方式(PConv + PWConv),PConv 为在输入特征图的个通道上进行卷积,其余通道上不变,但为了充分地利用各个通道的信息,在剩余通道上附加PWConv(逐点卷积),如图5(b)所示,形成T形Conv。
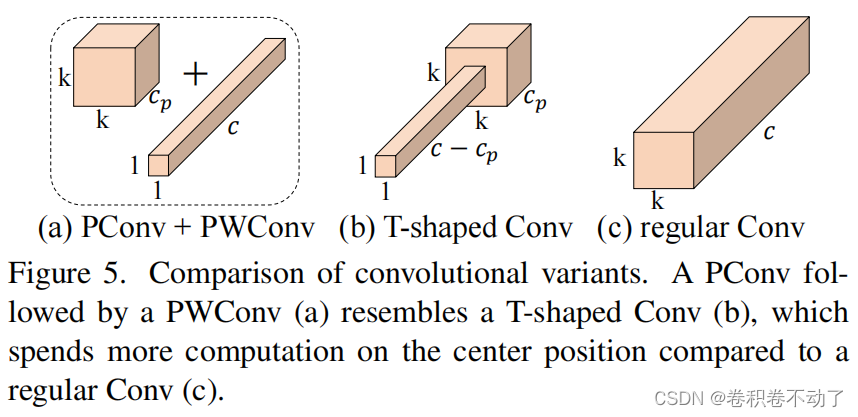
鉴于新型PConv和现成的PWConv作为主要的算子,进一步提出FasterNet,这是一个新的神经网络家族,运行速度非常快,对许多视觉任务非常有效。作者的目标是使体系结构尽可能简单,使其总体上对硬件友好。
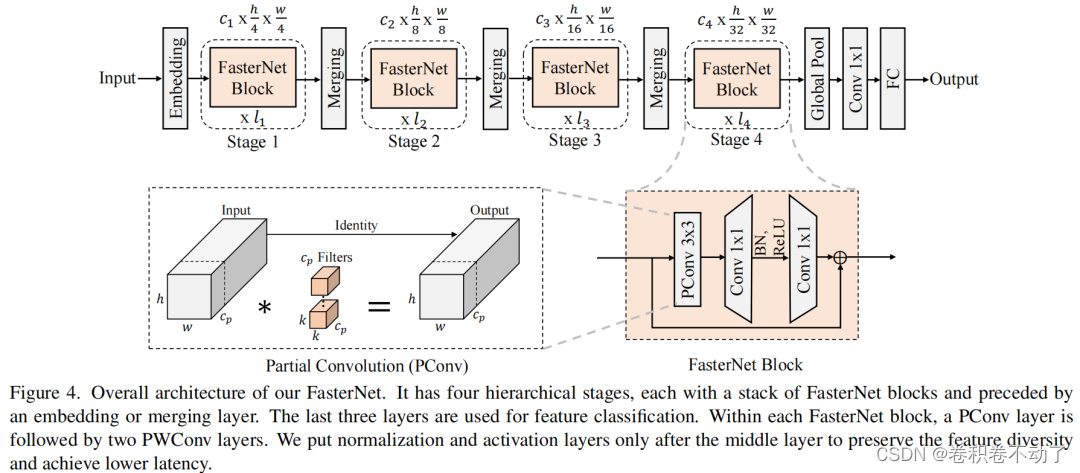
在图4中展示了整体架构。它有4个层次级,每个层次级前面都有一个嵌入层(步长为4的常规4×4卷积)或一个合并层(步长为2的常规2×2卷积),用于空间下采样和通道数量扩展。每个阶段都有一堆FasterNet块。最后两个阶段中的块消耗更少的内存访问,并且倾向于具有更高的FLOPS,因此,放置了更多FasterNet块,并相应地将更多计算分配给最后两个阶段。每个FasterNet块有一个PConv层,后跟2个PWConv(或Conv 1×1)层。它们一起显示为倒置残差块,其中中间层具有扩展的通道数量,并且放置了Shorcut以重用输入特征。
除了上述算子,标准化和激活层对于高性能神经网络也是不可或缺的。然而,许多先前的工作在整个网络中过度使用这些层,这可能会限制特征多样性,从而损害性能。它还可以降低整体计算速度。相比之下,只将它们放在每个中间PWConv之后,以保持特征多样性并实现较低的延迟。
此外,使用批次归一化(BN)代替其他替代方法。BN的优点是,它可以合并到其相邻的Conv层中,以便更快地进行推断,同时与其他层一样有效。对于激活层,根据经验选择了GELU用于较小的FasterNet变体,而ReLU用于较大的FasterNet变体,同时考虑了运行时间和有效性。最后三个层,即全局平均池化、卷积1×1和全连接层,一起用于特征转换和分类。
Fasternet的代码实现,保存在backbone/mobilefacenet中,代码为:
- class FasterNet(nn.Module):
-
- def __init__(self,
- in_chans=3,
- num_classes=512,
- embed_dim=96,
- depths=(1, 2, 8, 2),
- mlp_ratio=2.,
- n_div=4,
- patch_size=4,
- patch_stride=4,
- patch_size2=2, # for subsequent layers
- patch_stride2=2,
- patch_norm=True,
- feature_dim=1280,
- drop_path_rate=0.1,
- layer_scale_init_value=0,
- norm_layer='BN',
- act_layer='RELU',
- fork_feat=False,
- init_cfg=None,
- pretrained=None,
- pconv_fw_type='split_cat',
- **kwargs):
- super().__init__()
-
- if norm_layer == 'BN':
- norm_layer = nn.BatchNorm2d
- else:
- raise NotImplementedError
-
- if act_layer == 'GELU':
- act_layer = nn.GELU
- elif act_layer == 'RELU':
- act_layer = partial(nn.ReLU, inplace=True)
- else:
- raise NotImplementedError
-
- if not fork_feat:
- self.num_classes = num_classes
- self.num_stages = len(depths)
- self.embed_dim = embed_dim
- self.patch_norm = patch_norm
- self.num_features = int(embed_dim * 2 ** (self.num_stages - 1))
- self.mlp_ratio = mlp_ratio
- self.depths = depths
-
- # split image into non-overlapping patches
- self.patch_embed = PatchEmbed(
- patch_size=patch_size,
- patch_stride=patch_stride,
- in_chans=in_chans,
- embed_dim=embed_dim,
- norm_layer=norm_layer if self.patch_norm else None
- )
-
- # stochastic depth decay rule
- dpr = [x.item()
- for x in torch.linspace(0, drop_path_rate, sum(depths))]
-
- # build layers
- stages_list = []
- for i_stage in range(self.num_stages):
- stage = BasicStage(dim=int(embed_dim * 2 ** i_stage),
- n_div=n_div,
- depth=depths[i_stage],
- mlp_ratio=self.mlp_ratio,
- drop_path=dpr[sum(depths[:i_stage]):sum(depths[:i_stage + 1])],
- layer_scale_init_value=layer_scale_init_value,
- norm_layer=norm_layer,
- act_layer=act_layer,
- pconv_fw_type=pconv_fw_type
- )
- stages_list.append(stage)
-
- # patch merging layer
- if i_stage < self.num_stages - 1:
- stages_list.append(
- PatchMerging(patch_size2=patch_size2,
- patch_stride2=patch_stride2,
- dim=int(embed_dim * 2 ** i_stage),
- norm_layer=norm_layer)
- )
-
- self.stages = nn.Sequential(*stages_list)
-
- self.fork_feat = fork_feat
-
- if self.fork_feat:
- self.forward = self.forward_det
- # add a norm layer for each output
- self.out_indices = [0, 2, 4, 6]
- for i_emb, i_layer in enumerate(self.out_indices):
- if i_emb == 0 and os.environ.get('FORK_LAST3', None):
- raise NotImplementedError
- else:
- layer = norm_layer(int(embed_dim * 2 ** i_emb))
- layer_name = f'norm{i_layer}'
- self.add_module(layer_name, layer)
- else:
- self.forward = self.forward_cls
- # Classifier head
- self.avgpool_pre_head = nn.Sequential(
- nn.AdaptiveAvgPool2d(1),
- nn.Conv2d(self.num_features, feature_dim, 1, bias=False),
- act_layer()
- )
- self.head = nn.Linear(feature_dim, num_classes) \
- if num_classes > 0 else nn.Identity()
-
- self.apply(self.cls_init_weights)
- self.init_cfg = copy.deepcopy(init_cfg)
- if self.fork_feat and (self.init_cfg is not None or pretrained is not None):
- self.init_weights()
-
- def cls_init_weights(self, m):
- if isinstance(m, nn.Linear):
- trunc_normal_(m.weight, std=.02)
- if isinstance(m, nn.Linear) and m.bias is not None:
- nn.init.constant_(m.bias, 0)
- elif isinstance(m, (nn.Conv1d, nn.Conv2d)):
- trunc_normal_(m.weight, std=.02)
- if m.bias is not None:
- nn.init.constant_(m.bias, 0)
- elif isinstance(m, (nn.LayerNorm, nn.GroupNorm)):
- nn.init.constant_(m.bias, 0)
- nn.init.constant_(m.weight, 1.0)
-
- # init for mmdetection by loading imagenet pre-trained weights
- def init_weights(self, pretrained=None):
- logger = get_root_logger()
- if self.init_cfg is None and pretrained is None:
- logger.warn(f'No pre-trained weights for '
- f'{self.__class__.__name__}, '
- f'training start from scratch')
- pass
- else:
- assert 'checkpoint' in self.init_cfg, f'Only support ' \
- f'specify `Pretrained` in ' \
- f'`init_cfg` in ' \
- f'{self.__class__.__name__} '
- if self.init_cfg is not None:
- ckpt_path = self.init_cfg['checkpoint']
- elif pretrained is not None:
- ckpt_path = pretrained
-
- ckpt = _load_checkpoint(
- ckpt_path, logger=logger, map_location='cpu')
- if 'state_dict' in ckpt:
- _state_dict = ckpt['state_dict']
- elif 'model' in ckpt:
- _state_dict = ckpt['model']
- else:
- _state_dict = ckpt
-
- state_dict = _state_dict
- missing_keys, unexpected_keys = \
- self.load_state_dict(state_dict, False)
-
- # show for debug
- print('missing_keys: ', missing_keys)
- print('unexpected_keys: ', unexpected_keys)
-
- def forward_cls(self, x):
- # output only the features of last layer for image classification
- x = self.patch_embed(x)
- x = self.stages(x)
- x = self.avgpool_pre_head(x) # B C 1 1
- x = torch.flatten(x, 1)
- x = self.head(x)
-
- return x
-
- def forward_det(self, x: Tensor) -> Tensor:
- # output the features of four stages for dense prediction
- x = self.patch_embed(x)
- outs = []
- for idx, stage in enumerate(self.stages):
- x = stage(x)
- if self.fork_feat and idx in self.out_indices:
- norm_layer = getattr(self, f'norm{idx}')
- x_out = norm_layer(x)
- outs.append(x_out)
-
- return outs

3.1.2 更改Backbone为GhostFaceNet
GhostFaceNet的主要思想是卷积过程中,各个通道的卷积特征图高度相似,因此提出对部分通道进行卷积,将卷积得到的特征图进行线性变换得到剩余通道的特征图,减少特征映射冗余,减少计算量。
GhostFacenets的网络模型 :

其中的G-Bneckv1结构如下:
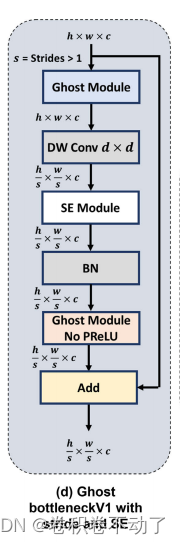
Ghost Module 的主要结构:
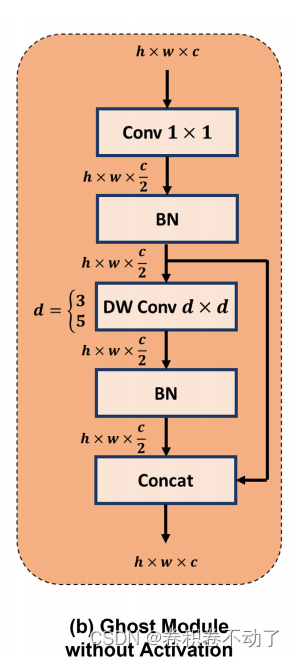
深度可分离卷积分为逐通道卷积和逐点卷积两部分:
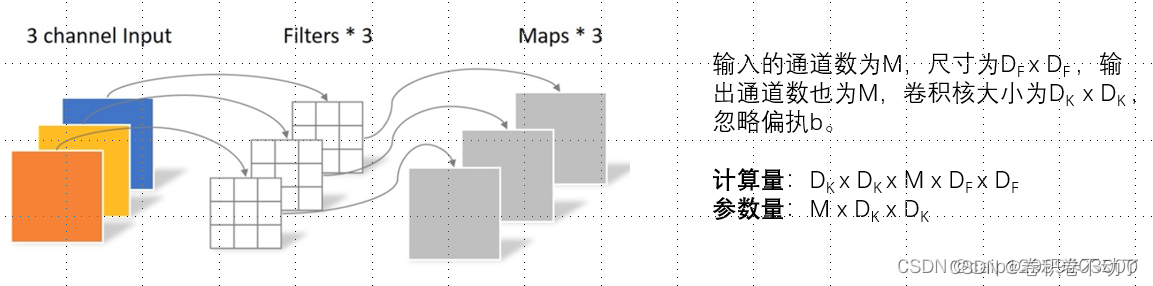
逐通道卷积的输出通道仅通过一个卷积核。
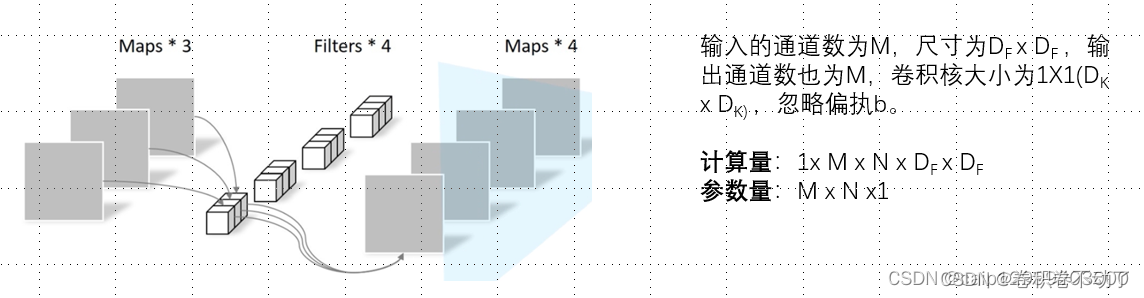 逐点卷积的实现方式与普通卷积类似,区别在于逐点卷积的卷积核为1x1。
逐点卷积的实现方式与普通卷积类似,区别在于逐点卷积的卷积核为1x1。
利用深度可分离卷积实现对部分通道卷积,剩余通道通过逐点卷积生成。
主要的创新点:
1.使用极简轻量化的GhostFaceNet网络作为人脸识别网络的主干。
2. 在主干网络输出特征的最后一层将GAP层更换为GDC(全局深度卷积模块),GAP层平等地对待输出特征映射的每个单元,这与在提取人脸特征向量时,不同类型的单元为理论带来不同数量的判别信息的假设相冲突。,所以在最终输出特征向量时,不采用全局平均池化。
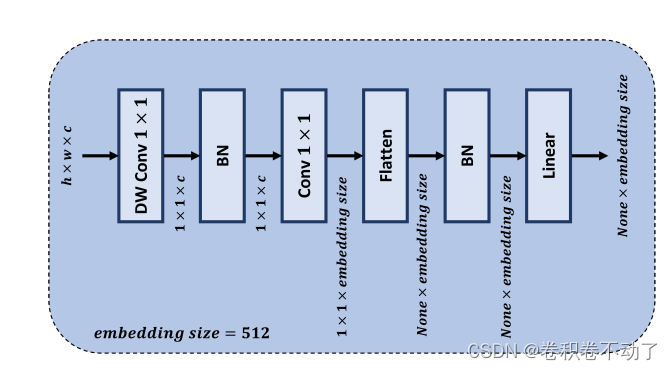
3.将非线性激活函数ReLU改为PReLU,支持负激活,增强学习非线性函数的能力,提高网络性能。
该激活函数可以自适应地学习矫正线性单元的参数,并且能够在增加可忽略的额外计算成本下提高准确率。
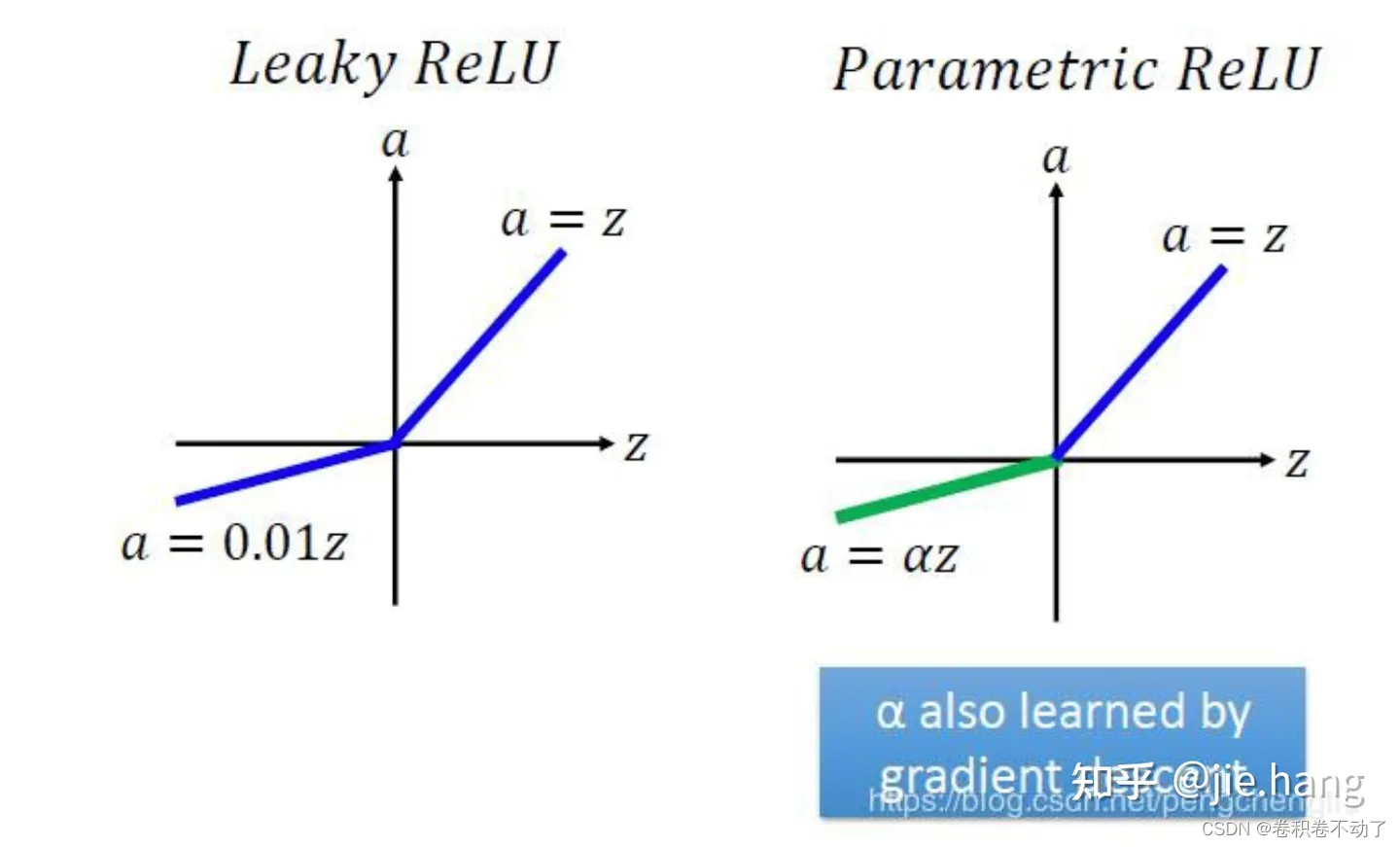
PRelu与LeakyRelu激活函数类似,不同点在于LeakyRelu的激活函数在负值方向的斜率为固定值,而PRelu的斜率为自适应斜率,在方向传播的过程中会更新负值方向的权重。当斜率为0时,则退化为Relu.
代码实现:
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import math
- from torchviz import make_dot
- def _make_divisible(v, divisor, min_value=None):
- """
- This function is taken from the original tf repo.
- It ensures that all layers have a channel number that is divisible by 8
- It can be seen here:
- https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
- """
- if min_value is None:
- min_value = divisor
- new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
- # Make sure that round down does not go down by more than 10%.
- if new_v < 0.9 * v:
- new_v += divisor
- return new_v
-
- def hard_sigmoid(x, inplace: bool = False):
- if inplace:
- return x.add_(3.).clamp_(0., 6.).div_(6.)
- else:
- return F.relu6(x + 3.) / 6.
-
- class SqueezeExcite(nn.Module):
- def __init__(self, in_chs, se_ratio=0.25, reduced_base_chs=None,
- act_layer=nn.PReLU, gate_fn=hard_sigmoid, divisor=4, **_):
- super(SqueezeExcite, self).__init__()
- self.gate_fn = gate_fn
- reduced_chs = _make_divisible((reduced_base_chs or in_chs) * se_ratio, divisor)
- self.avg_pool = nn.AdaptiveAvgPool2d(1)
- self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
- self.act1 = act_layer()
- self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
-
- def forward(self, x):
- x_se = self.avg_pool(x)
- x_se = self.conv_reduce(x_se)
- x_se = self.act1(x_se)
- x_se = self.conv_expand(x_se)
- x = x * self.gate_fn(x_se)
- return x
-
- class ConvBnAct(nn.Module):
- def __init__(self, in_chs, out_chs, kernel_size,
- stride=1, act_layer=nn.PReLU):
- super(ConvBnAct, self).__init__()
- self.conv = nn.Conv2d(in_chs, out_chs, kernel_size, stride, kernel_size//2, bias=False)
- self.bn1 = nn.BatchNorm2d(out_chs)
- self.act1 = act_layer()
-
- def forward(self, x):
- x = self.conv(x)
- x = self.bn1(x)
- x = self.act1(x)
- return x
-
- class ModifiedGDC(nn.Module):
- def __init__(self, in_chs, image_size, num_classes, dropout, emb=512): #embedding = 512 from original code
- super(ModifiedGDC, self).__init__()
- image_kernel_size = 0
- self.dropout = dropout
-
- if image_size % 32 == 0:
- image_kernel_size = image_size//32
- else:
- image_kernel_size = (image_size//32) + 1
- self.conv_dw = nn.Conv2d(in_chs, in_chs, kernel_size=image_kernel_size, groups=in_chs, bias=False)
-
- self.bn1 = nn.BatchNorm2d(in_chs)
-
- self.conv = nn.Conv2d(in_chs, emb, kernel_size=1, bias=False)
- nn.init.xavier_normal_(self.conv.weight.data) #initialize weight
-
- self.bn2 = nn.BatchNorm1d(emb)
- self.linear = nn.Linear(emb, num_classes) if num_classes else nn.Identity()
-
- def forward(self, x):
- x = self.conv_dw(x)
- x = self.bn1(x)
- if self.dropout > 0. and self.dropout < 1.:
- x = F.dropout(x, p=self.dropout, training=self.training)
- x = self.conv(x)
- x = x.view(x.size(0), -1) #flatten
- x = self.bn2(x)
- x = self.linear(x)
- return x
-
- class GhostModuleV2(nn.Module):
- def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, prelu=True,mode=None,args=None):
- super(GhostModuleV2, self).__init__()
- self.mode=mode
- self.gate_fn=nn.Sigmoid()
-
- if self.mode in ['original']:
- self.oup = oup
- init_channels = math.ceil(oup / ratio)
- new_channels = init_channels*(ratio-1)
- self.primary_conv = nn.Sequential(
- nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
- nn.BatchNorm2d(init_channels),
- nn.PReLU() if prelu else nn.Sequential(),
- )
- self.cheap_operation = nn.Sequential(
- nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
- nn.BatchNorm2d(new_channels),
- nn.PReLU() if prelu else nn.Sequential(),
- )
- elif self.mode in ['attn']: #DFC
- self.oup = oup
- init_channels = math.ceil(oup / ratio)
- new_channels = init_channels*(ratio-1)
- self.primary_conv = nn.Sequential(
- nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
- nn.BatchNorm2d(init_channels),
- nn.PReLU() if prelu else nn.Sequential(),
- )
- self.cheap_operation = nn.Sequential(
- nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
- nn.BatchNorm2d(new_channels),
- nn.PReLU() if prelu else nn.Sequential(),
- )
- self.short_conv = nn.Sequential(
- nn.Conv2d(inp, oup, kernel_size, stride, kernel_size//2, bias=False),
- nn.BatchNorm2d(oup),
- nn.Conv2d(oup, oup, kernel_size=(1,5), stride=1, padding=(0,2), groups=oup,bias=False),
- nn.BatchNorm2d(oup),
- nn.Conv2d(oup, oup, kernel_size=(5,1), stride=1, padding=(2,0), groups=oup,bias=False),
- nn.BatchNorm2d(oup),
- )
-
- def forward(self, x):
- if self.mode in ['original']:
- x1 = self.primary_conv(x)
- x2 = self.cheap_operation(x1)
- out = torch.cat([x1,x2], dim=1)
- return out[:,:self.oup,:,:]
- elif self.mode in ['attn']:
- res=self.short_conv(F.avg_pool2d(x,kernel_size=2,stride=2))
- x1 = self.primary_conv(x)
- x2 = self.cheap_operation(x1)
- out = torch.cat([x1,x2], dim=1)
- return out[:,:self.oup,:,:]*F.interpolate(self.gate_fn(res),size=(out.shape[-2],out.shape[-1]),mode='nearest')
-
-
- class GhostBottleneckV2(nn.Module):
- def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,
- stride=1, act_layer=nn.PReLU, se_ratio=0.,layer_id=None,args=None):
- super(GhostBottleneckV2, self).__init__()
- has_se = se_ratio is not None and se_ratio > 0.
- self.stride = stride
-
- # Point-wise expansion
- if layer_id<=1:
- self.ghost1 = GhostModuleV2(in_chs, mid_chs, prelu=True,mode='original',args=args)
- else:
- self.ghost1 = GhostModuleV2(in_chs, mid_chs, prelu=True,mode='attn',args=args)
-
- # Depth-wise convolution
- if self.stride > 1:
- self.conv_dw = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride=stride,
- padding=(dw_kernel_size-1)//2,groups=mid_chs, bias=False)
- self.bn_dw = nn.BatchNorm2d(mid_chs)
-
- # Squeeze-and-excitation
- if has_se:
- self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
- else:
- self.se = None
-
- self.ghost2 = GhostModuleV2(mid_chs, out_chs, prelu=False,mode='original',args=args)
-
- # shortcut
- if (in_chs == out_chs and self.stride == 1):
- self.shortcut = nn.Sequential()
- else:
- self.shortcut = nn.Sequential(
- nn.Conv2d(in_chs, in_chs, dw_kernel_size, stride=stride,
- padding=(dw_kernel_size-1)//2, groups=in_chs, bias=False),
- nn.BatchNorm2d(in_chs),
- nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),
- nn.BatchNorm2d(out_chs),
- )
-
- def forward(self, x):
- residual = x
- x = self.ghost1(x)
- if self.stride > 1:
- x = self.conv_dw(x)
- x = self.bn_dw(x)
- if self.se is not None:
- x = self.se(x)
- x = self.ghost2(x)
- x += self.shortcut(residual)
- return x
-
-
- class GhostFaceNetV2(nn.Module):
- def __init__(self, cfgs, image_size=256, num_classes=1000, width=1.0, dropout=0.2, block=GhostBottleneckV2,
- add_pointwise_conv=False, args=None):
- super(GhostFaceNetV2, self).__init__()
- self.cfgs = cfgs
-
- # building first layer
- output_channel = _make_divisible(16 * width, 4)
- self.conv_stem = nn.Conv2d(3, output_channel, 3, 2, 1, bias=False)
- self.bn1 = nn.BatchNorm2d(output_channel)
- self.act1 = nn.PReLU()
- input_channel = output_channel
-
- # building inverted residual blocks
- stages = []
- layer_id=0
- for cfg in self.cfgs:
- layers = []
- for k, exp_size, c, se_ratio, s in cfg:
- output_channel = _make_divisible(c * width, 4)
- hidden_channel = _make_divisible(exp_size * width, 4)
- if block==GhostBottleneckV2:
- layers.append(block(input_channel, hidden_channel, output_channel, k, s,
- se_ratio=se_ratio,layer_id=layer_id,args=args))
- input_channel = output_channel
- layer_id+=1
- stages.append(nn.Sequential(*layers))
-
- output_channel = _make_divisible(exp_size * width, 4)
- stages.append(nn.Sequential(ConvBnAct(input_channel, output_channel, 1)))
-
- self.blocks = nn.Sequential(*stages)
-
- # building last several layers
- pointwise_conv = []
- if add_pointwise_conv:
- pointwise_conv.append(nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=True))
- pointwise_conv.append(nn.BatchNorm2d(output_channel))
- pointwise_conv.append(nn.PReLU())
- else:
- pointwise_conv.append(nn.Sequential())
-
- self.pointwise_conv = nn.Sequential(*pointwise_conv)
- self.classifier = ModifiedGDC(output_channel, image_size, num_classes, dropout)
-
- def forward(self, x):
- x = self.conv_stem(x)
- x = self.bn1(x)
- x = self.act1(x)
- x = self.blocks(x)
- x = self.pointwise_conv(x)
- x = self.classifier(x)
- return x
-
- def ghostfacenetv2(bn_momentum=0.9, bn_epsilon=1e-5, num_classes=None, **kwargs):
- cfgs = [
- # k, t, c, SE, s
- [[3, 16, 16, 0, 1]],
- [[3, 48, 24, 0, 2]],
- [[3, 72, 24, 0, 1]],
- [[5, 72, 40, 0.25, 2]],
- [[5, 120, 40, 0.25, 1]],
- [[3, 240, 80, 0, 2]],
- [[3, 200, 80, 0, 1],
- [3, 184, 80, 0, 1],
- [3, 184, 80, 0, 1],
- [3, 480, 112, 0.25, 1],
- [3, 672, 112, 0.25, 1]
- ],
- [[5, 672, 160, 0.25, 2]],
- [[5, 960, 160, 0, 1],
- [5, 960, 160, 0.25, 1],
- [5, 960, 160, 0, 1],
- [5, 960, 160, 0.25, 1]
- ]
- ]
-
- GhostFaceNet = GhostFaceNetV2(cfgs,
- num_classes=num_classes,
- image_size=kwargs['image_size'],
- width=kwargs['width'],
- dropout=kwargs['dropout'],
- args=kwargs['args'])
-
- for module in GhostFaceNet.modules():
- if isinstance(module, nn.BatchNorm2d):
- module.momentum, module.eps = bn_momentum, bn_epsilon
-
- return GhostFaceNet
-
-
- if __name__=='__main__':
-
-
- kwargs = {
- 'image_size': 112, # 示例图像大小
- 'width': 1.0, # 示例宽度
- 'dropout': 0.2, # 示例 dropout
- 'args': None # 示例额外参数
- }
- model = ghostfacenetv2(**kwargs)
- x = torch.randn(16,3,112,112)
- out = model(x)
- print(out.shape)
-
- graph = make_dot(out,params = dict(model.named_parameters()))
- graph.view()
4.网络轻量化方法
4.1 模型剪枝
模型剪枝主要出现在全连接层中,这主要是因为全连接层中每一个节点都与上一个节点相连,冗余程度最高,其中部分神经元对输出结果影响较小,可以选择去除。
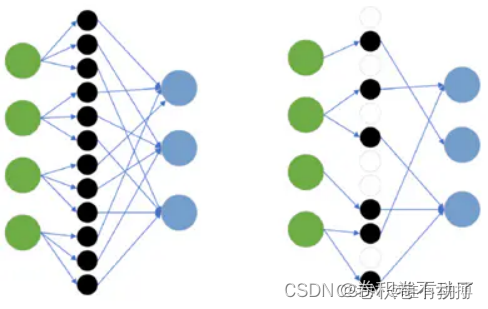
在选择的过程中,将权重绝对值较小的神经元去除,并移除对应的连接,这种操作可以有效减小全连接层的复杂程度,保留对输出结果起主要影响的神经元,但也会造成一定的误差,误差累积后会对网络的准确率造成一定影响。
4.2 网络高效化的模块
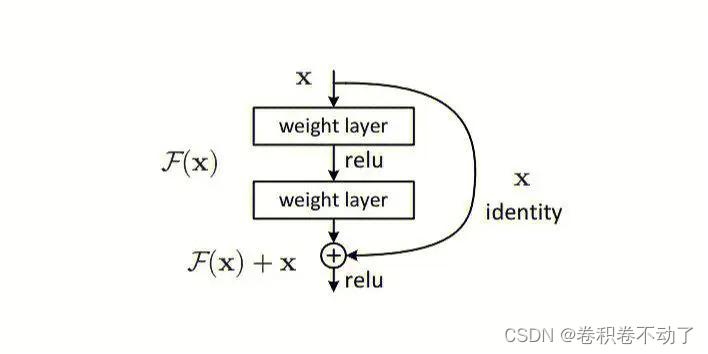
ResNet:残差结构主要解决较深的神经网络中出现参数冗余的问题,当网络中部分层在整体结构中发挥作用较小甚至不发挥作用时,这种情况下我们希望网络不对输入X做处理,即直接输出,但令神经网络学习到该参数较为复杂,残差边的出现将主干路的优化条件变为了
,降低了网络学习的难度的同时,也使得网络更快的收敛。
EfficientNet:提出复合缩放方法,对网络在不同的网络维度(深度、宽度、分辨率)上进行统一的缩放,以获得更好的性能。

