
- 1Typora + 阿里云OSS + PicGo搭建图床_typora图床
- 2MySQL运算符_写出mysql运算符的分类,并分别写出对应的运算符及名称。
- 3文本比较算法Ⅲ——计算文本的相似度
- 4css实现优惠券样式_css 优惠券
- 5量子计算关键技术及应用发展分析_全球光量子计算机研究进展
- 6ChatTTS增强版V3【已开源】,长文本修复,中英混读,导入音色,批量SRT、TXT
- 7关于Stable diffusion的各种模型,看这篇就可以了!_stable diffusion常用模型
- 8Mac root 用户报无权限_mac root wheel没有权限
- 9AI大模型知识点大梳理_ai大模型是什么
- 10git commit提交规范_gitcommit规范
Qwen-Audio:推动通用音频理解的统一大规模音频-语言模型(开源)_qwne-audio
赞
踩
随着人工智能技术的不断进步,音频语言模型(Audio-Language Models)在人机交互领域变得越来越重要。然而,由于缺乏能够处理多样化音频类型和任务的预训练模型,该领域的进展受到了限制。为了克服这一挑战,研究者们开发了Qwen-Audio模型,这是一个能够覆盖超过30种任务和各种音频类型的统一大规模音语预训练模型。
Qwen-Audio模型介绍
Qwen-Audio模型通过扩展Qwen-7B语言模型,连接单一音频编码器,有效地感知音频信号。与以往主要处理特定音频类型(如人类语音)或专注于特定任务(如语音识别和字幕生成)的模型不同,Qwen-Audio在多任务学习框架中进行了扩展,涵盖了多种语言和音频类型,以促进通用音频理解能力的发展。
模型架构
Qwen-Audio模型的核心架构包括一个音频编码器和一个大语言模型(LLM)。音频编码器基于Whisper-large-v2模型初始化,能够处理各种类型的音频,如人类语音、自然声音、音乐和歌曲。该编码器将原始音频波形转换为80通道的melspectrogram,并通过池化层降低音频表示的长度,使得编码器输出的每一帧大约对应原始音频信号的40毫秒段。
大型语言模型部分则初始化自Qwen-7B模型,这是一个包含7.7亿参数的32层Transformer解码器模型。Qwen-Audio的训练目标是最大化给定音频表示和之前文本序列的下一个文本标记概率。
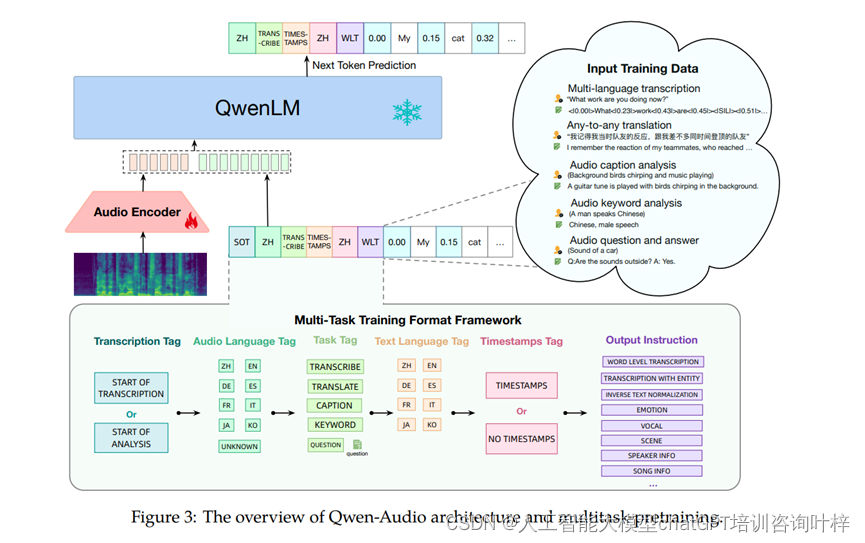
多任务学习框架
为了在多任务学习中有效地训练Qwen-Audio,研究者提出了一个多任务训练格式框架。该框架通过一系列层次化标签来指导解码器,包括转录标签、音频语言标签、任务标签、文本语言标签、时间戳标签和输出指令。这样的设计不仅促进了类似任务之间的知识共享,还通过区分不同任务和输出格式来避免模型的多对一映射问题。
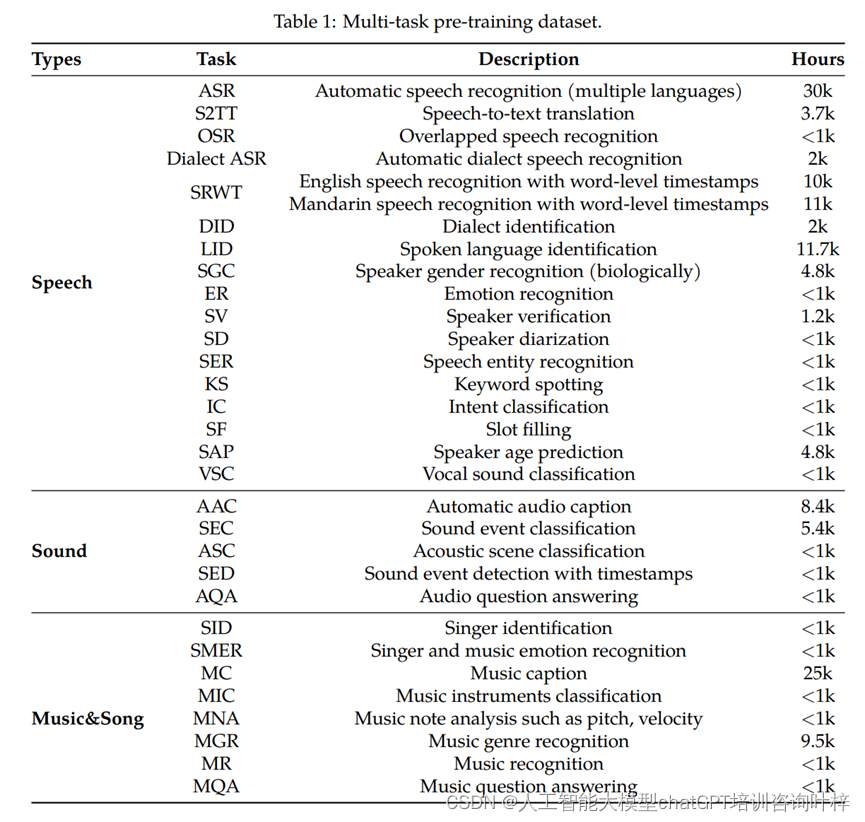
实验结果
Qwen-Audio在不需要任何任务特定微调的情况下,在多个基准测试任务上取得了令人印象深刻的性能,超越了其同类模型。特别是在Aishell1、cochlscene、ClothoAQA和VocalSound测试集上,Qwen-Audio实现了最先进的性能。
实验设置
- 研究者们对Qwen-Audio进行了多任务预训练,并在随后的监督微调阶段创建了Qwen-Audio-Chat模型。
基准测试任务
- Qwen-Audio在多个基准测试任务上进行了评估,这些任务包括自动语音识别(ASR)、语音到文本翻译(S2TT)、自动音频字幕生成(AAC)、声学场景分类(ASC)、语音情感识别(SER)、音频问答(AQA)、声乐声音分类(VSC)和音乐音符分析(MNA)。
实验结果
- Qwen-Audio在没有进行任何任务特定微调的情况下,就在多个任务上取得了优异的性能。
- 具体来说,Qwen-Audio在以下测试集上实现了最先进的性能:
- Aishell1:这是一个中文普通话的自动语音识别数据集,Qwen-Audio在开发和测试集上均取得了最低的词错误率(WER)。
- cochlscene:声学场景分类任务的数据集,Qwen-Audio在测试集上达到了最高的准确率(ACC)。
- ClothoAQA:一个音频问答任务的数据集,Qwen-Audio在测试集上展现了最高的准确率。
- VocalSound:声乐声音分类任务的数据集,Qwen-Audio同样在测试集上取得了最高的准确率。
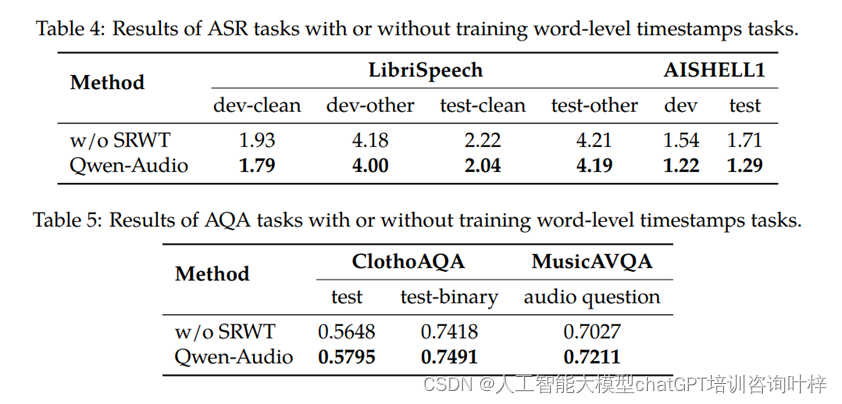
性能对比
- Qwen-Audio的性能不仅在上述提到的数据集上超越了其他模型,而且在其他多个任务和数据集上也展现了强劲的性能,这证明了其通用音频理解能力的广泛性和有效性。

Qwen-Audio-Chat
基于Qwen-Audio的能力,研究者进一步开发了Qwen-Audio-Chat,它允许来自各种音频和文本输入的输入,支持多轮对话,并支持各种以音频为中心的场景。Qwen-Audio-Chat 的目标是创建一个能够理解音频和文本输入、并支持多轮对话的模型。该模型旨在模拟人类对话的方式,能够根据用户的指令进行有效的互动。
指令微调过程
- Qwen-Audio-Chat 的开发涉及到使用指令微调技术,这是在多任务预训练的基础上进行的。具体来说,研究者们手动创建了每个任务的示例,包括原始文本标签、问题和答案。
- 利用 GPT-3.5 生成基于提供文本标签的更多问题和答案,以增强模型的对话能力。
数据集构建
- 为了有效地训练 Qwen-Audio-Chat,研究者们构建了一个包含音频对话数据的数据集。这个数据集通过手动注释、模型生成和策略串联来创建,帮助模型整合推理、故事生成和多图像理解能力。
多音频输入处理
- Qwen-Audio-Chat 能够处理多音频对话和多个音频输入,为此引入了使用 "Audio id:" 标记不同音频的约定,其中 id 对应于音频输入对话的顺序。
对话格式
- 在对话格式方面,Qwen-Audio-Chat 使用 ChatML 格式构建指令调优数据集。在这种格式中,每个交互的语句都标记有特殊的开始和结束标记(例如
<im_start>和<im_end>),以便于对话的终止。
结论
Qwen-Audio系列模型展示了作为通用音频理解模型的潜力。通过大规模的端到端训练,Qwen-Audio成功地弥合了音频和文本模态之间的差距,并在多种任务上展现了卓越的性能。
[1]论文链接:https://arxiv.org/pdf/2311.07919.pdf
[2]开源代码:https://github.com/QwenLM/Qwen-Audio

