
- 1多线程实操&&阻塞队列_后台阻塞一个线程,再次请求这个接口
- 2独家揭秘:AI漫画小说推文项目,实战攻略助你月入轻松破万_做小说推文用ai推文有收益吗
- 3opencv-python[cv2]读取中文路径图像_cv2读取中文路径
- 4银河麒麟搭建nodejs环境_麒麟系统安装node
- 5rust实战系列一百零二:Unsafe_rust什么情况下需要unsafe
- 6adb 切换usb模式_利用adb命令打开usb调试
- 7PyQt5 实现字体大小自适应分辨率的方法_python pyqt5 高dpi文字缩放
- 8当EAI遇见RPA:破解接口难题,助力数据打通_rpa实现无接口上传
- 9数论+线性dp——cf1174A
- 10JUC并发编程与源码分析笔记-目录
万字详解YOLOv8网络结构Backbone/neck/head以及Conv、Bottleneck、C2f、SPPF、Detect等模块_yolov8网络架构
赞
踩
YOLO目标检测创新改进与实战案例专栏
专栏目录: YOLO有效改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例
专栏链接: YOLO基础解析+创新改进+实战案例
简介
YOLOv8是由Ultralytics开发的最先进的目标检测模型,推升了速度、准确性和用户友好性的界限。YOLO这一缩写代表“你只看一次”(You Only Look Once),通过在一次网络传递中同时预测所有边界框,提升了算法的效率和实时处理能力。相比之下,其他一些目标检测技术需要经过多个阶段或过程来完成检测。YOLOv8在流行的YOLOv5架构上进行了扩展,在多个方面提供了改进。YOLOv8模型与其前身的主要区别在于使用了无锚点检测,这加速了非极大值抑制(Non-Maximum Suppression, NMS)的后处理过程。YOLOv8能够以惊人的速度和精度识别和定位图像和视频中的物体,并处理图像分类和实例分割等任务。
YOLOv8网络架构图1
下图是GitHub 用户 RangeKing 制作的YOLOv8网络架构的可视化结结构图。
这里的Neck和Head分开了

YOLOv8网络架构图2
下图是另一个版本的网络架构图,这个版本并没有区分neck和head。 但本质上两张图是一样的

yolov8的模型
- n:最小的模型,最快的推理,但最低的准确性
- S:型号小,速度和精度平衡好
- M:中等模型,比推理速度适中的小型模型精度更高
- L:模型大,准确率最高但推理速度最慢
- XL:超大模型,资源密集型应用的最佳精度

YOLOV8的网络结构概述
YOLOv8的网络结构主要由以下三个大部分组成:
Backbone
Backbone部分负责特征提取,采用了一系列卷积和反卷积层,同时使用了残差连接和瓶颈结构来减小网络的大小并提高性能。该部分采用了C2f模块作为基本构成单元,与YOLOv5的C3模块相比,C2f模块具有更少的参数量和更优秀的特征提取能力。具体来说,C2f模块通过更有效的结构设计,减少了冗余参数,提高了计算效率。此外,Backbone部分还包括一些常见的改进技术,如深度可分离卷积(Depthwise Separable Convolution)和膨胀卷积(Dilated Convolution),以进一步增强特征提取的能力。
Neck
Neck部分负责多尺度特征融合,通过将来自Backbone不同阶段的特征图进行融合,增强特征表示能力。具体来说,YOLOv8的Neck部分包括以下组件:
- SPPF模块(Spatial Pyramid Pooling Fast):用于不同尺度的池化操作,将不同尺度的特征图拼接在一起,提高对不同尺寸目标的检测能力。
- PAA模块(Probabilistic Anchor Assignment):用于智能地分配锚框,以优化正负样本的选择,提高模型的训练效果。
- PAN模块(Path Aggregation Network):包括两个PAN模块,用于不同层次特征的路径聚合,通过自底向上和自顶向下的路径增强特征图的表达能力。
Head
Head部分负责最终的目标检测和分类任务,包括一个检测头和一个分类头:
- 检测头:包含一系列卷积层和反卷积层,用于生成检测结果。这些层负责预测每个锚框的边界框回归值和目标存在的置信度。
- 分类头:采用全局平均池化(Global Average Pooling)对每个特征图进行分类,通过减少特征图的维度,输出每个类别的概率分布。分类头的设计使得YOLOv8能够有效地处理多类别分类任务。
其他优化
除了上述结构外,YOLOv8还引入了一些新的优化技术,如:
- Anchor-free机制:减少了锚框的超参数设置,通过直接预测目标的中心点来简化训练过程。
- 自适应NMS(Non-Maximum Suppression):改进了传统的NMS算法,通过自适应调整阈值,减少误检和漏检,提高检测精度。
- 自动混合精度训练(Automatic Mixed Precision Training):通过在训练过程中动态调整计算精度,加快训练速度,同时减少显存占用。
YOLOv8架构中使用的模块
卷积块(Conv Block)

这是架构中最基本的模块,包括Conv2d层、BatchNorm2d层和SiLU激活函数。
Conv2d层
卷积是一种数学运算,涉及将一个小矩阵(称为核或滤波器)滑动到输入数据上,执行元素级的乘法,并将结果求和以生成特征图。“2D”在Conv2d中表示卷积应用于两个空间维度,通常是高度和宽度。
- k k k(kernel数量):滤波器或核的数量,代表输出体积的深度,每个滤波器负责检测输入中的不同特征。
- s s s(stride步幅):步幅,指滤波器/核在输入上滑动的步长。较大的步幅会减少输出体积的空间维度。
- p p p(padding填充):填充,指在输入的每一侧添加的额外零边框,有助于保持空间信息,并可用于控制输出体积的空间维度。
- c c c(channels输入通道数):输入的通道数。例如,对于RGB图像, c c c为3(每个颜色:红色、绿色和蓝色各一个通道)。
BatchNorm2d层
批归一化(BatchNorm2d)是一种在深度神经网络中使用的技术,用于提高训练稳定性和收敛速度。在卷积神经网络(CNN)中,BatchNorm2d层特定地对2D输入进行批归一化,通常是卷积层的输出。它通过在每个小批次的数据中标准化特征,使每个特征在小批次中的均值接近0、方差接近1,确保通过网络的数据不会太大或太小,这有助于防止训练过程中出现的问题。
SiLU激活函数
SiLU(Sigmoid Linear Unit)激活函数,也称为Swish激活函数,是神经网络中使用的激活函数。SiLU激活函数定义如下:
[ SiLU ( x ) = x ⋅ σ ( x ) ] [ \text{SiLU}(x) = x \cdot \sigma(x) ] [SiLU(x)=x⋅σ(x)]
其中, σ ( x ) \sigma(x) σ(x)是Sigmoid函数,定义为:
[ σ ( x ) = 1 1 + e − x ] [ \sigma(x) = \frac{1}{1 + e^{-x}} ] [σ(x)=1+e−x1]
SiLU的关键特性是它允许平滑的梯度,这在神经网络训练过程中是有益的。平滑的梯度可以帮助避免如梯度消失等问题,这些问题会阻碍深度神经网络的学习过程。
瓶颈块(Bottleneck Block)
在深度神经网络,尤其是残差网络(ResNet)中,Bottleneck Block(瓶颈块)是一种常用的模块设计。Bottleneck Block旨在通过引入瓶颈结构,减少计算复杂度和参数数量,同时保留模型的性能。以下是Bottleneck Block的详细介绍。
Bottleneck Block 的典型结构
Bottleneck Block 典型地由三个卷积层(Conv2d)组成:
- 第一个 1x1 卷积层:用于减少通道数(压缩瓶颈)。
- 第二个 3x3 卷积层:用于在减少后的通道数上进行卷积操作。
- 第三个 1x1 卷积层:用于恢复通道数(扩展瓶颈)。
这些卷积层之间通常会插入 BatchNorm 和激活函数。一个 Bottleneck Block 还包括一个恒等映射(Identity Mapping)或一个卷积映射(Convolutional Mapping),用于实现残差连接。残差连接使得输入可以绕过中间卷积层,直接加到输出上,从而减轻梯度消失的问题。
具体结构
假设输入张量为 X X X,输出张量为 Y Y Y。Bottleneck Block 的具体结构如下:
-
第一个 1x1 卷积层:
- 输入: X X X
- 卷积: C o n v 2 d ( 1 × 1 ) Conv2d(1 \times 1) Conv2d(1×1)
- 批归一化: B a t c h N o r m 2 d BatchNorm2d BatchNorm2d
- 激活函数: S i L U SiLU SiLU
- 输出: X 1 X_1 X1
-
第二个 3x3 卷积层:
- 输入: X 1 X_1 X1
- 卷积: C o n v 2 d ( 3 × 3 ) Conv2d(3 \times 3) Conv2d(3×3)
- 批归一化: B a t c h N o r m 2 d BatchNorm2d BatchNorm2d
- 激活函数: S i L U SiLU SiLU
- 输出: X 2 X_2 X2
-
第三个 1x1 卷积层:
- 输入: X 2 X_2 X2
- 卷积: C o n v 2 d ( 1 × 1 ) Conv2d(1 \times 1) Conv2d(1×1)
- 批归一化: B a t c h N o r m 2 d BatchNorm2d BatchNorm2d
- 输出: X 3 X_3 X3
-
残差连接:
- 输入: X X X 和 X 3 X_3 X3
- 输出: Y = X + X 3 Y = X + X_3 Y=X+X3
这种结构设计使得 Bottleneck Block 在减少计算量的同时,保留了网络的表达能力和训练稳定性。
总结
Bottleneck Block 的设计通过在中间引入较少通道的卷积操作,实现了计算效率和性能之间的平衡。以下是 Bottleneck Block 的主要特点:
- 降维和升维:通过 1x1 卷积实现通道数的压缩和扩展,降低计算复杂度。
- 残差连接:通过残差连接保留输入信息,有助于缓解梯度消失问题,提高网络的训练效果。
- 高效计算:通过减少中间层的通道数,在保证性能的同时减少计算量和参数数量。
yoloV8中Bottleneck Block结构
下图是yoloV8中Bottleneck Block结构,并不是典型的结构。
YOLOv8瓶颈块结构说明
-
卷积层 1(Conv 1):首先输入通过一个卷积层,通常卷积核大小为 ( 1 × 1 ) (1 \times 1) (1×1),用于减少特征图的通道数。
-
卷积层 2(Conv 2):紧接着输入通过一个卷积层,通常卷积核大小为 ( 3 × 3 ) (3 \times 3) (3×3),用于提取特征并增加感受野。
-
跳跃连接(Skip Connection):在卷积层之间加入跳跃连接,将输入直接连接到输出。这种连接方式可以缓解梯度消失问题,帮助网络更好地学习。
-
拼接(Concatenate):最后,将跳跃连接后的输出与卷积层的输出进行拼接,形成最终输出。
参数表解读
-
输入(Input):输入特征图的尺寸,例如 ( 64 × 64 × 256 ) (64 \times 64 \times 256) (64×64×256)。
-
Conv 1:第一个卷积层的参数,通常包括卷积核大小、步长和填充方式等。例如,卷积核大小为 ( 1 × 1 ) (1 \times 1) (1×1),输出通道数为 64。
-
Conv 2:第二个卷积层的参数,通常包括卷积核大小、步长和填充方式等。例如,卷积核大小为 ( 3 × 3 ) (3 \times 3) (3×3),输出通道数为 128。
-
跳跃连接(Skip Connection):表示是否使用跳跃连接。
-
输出(Output):输出特征图的尺寸。
功能和优势
- 减少参数和计算量:通过 ( 1 × 1 ) (1 \times 1) (1×1) 卷积层减少特征图的通道数,降低计算复杂度。
- 增加网络深度和非线性能力:通过增加 ( 3 × 3 ) (3 \times 3) (3×3) 卷积层,提取更多特征,提高模型表达能力。
- 跳跃连接:缓解梯度消失问题,帮助训练更深的网络。
结论
YOLOv8 的瓶颈块通过减少参数、增加网络深度和缓解梯度消失问题,显著提高了模型的性能和训练效果。该结构在保持计算效率的同时,增强了特征提取的能力,使得 YOLOv8 在目标检测任务中表现出色。

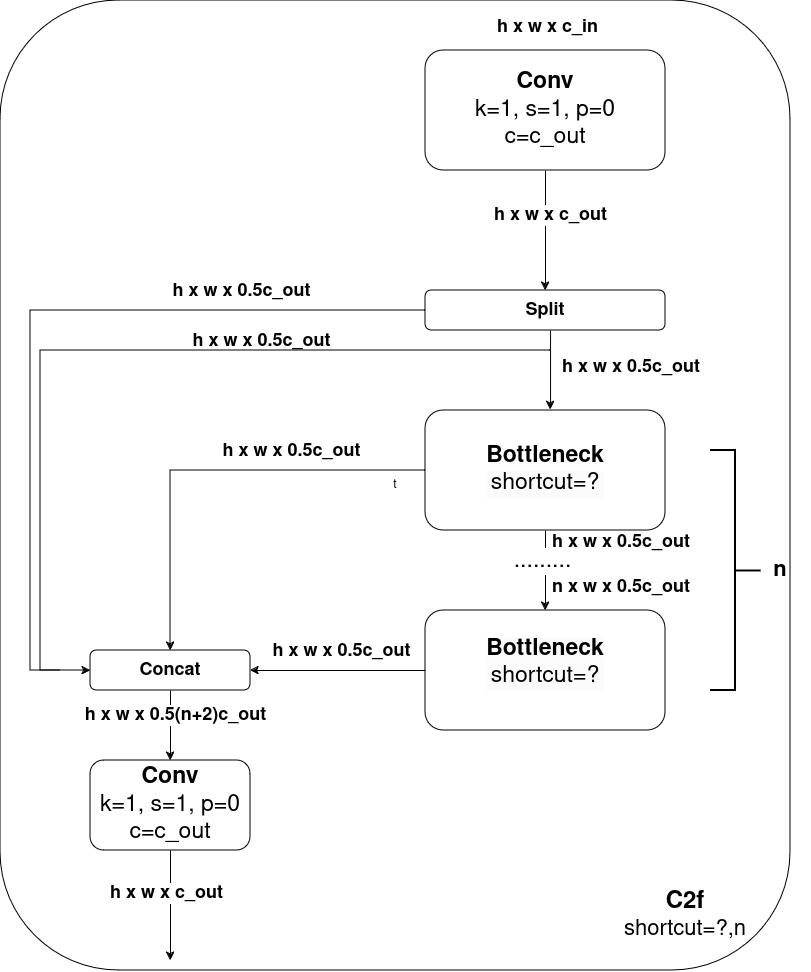
C2f 模块
下图显示了YOLOv8的C2f模块结构:
结构概述
- C2f块:首先由一个卷积块(Conv)组成,该卷积块接收输入特征图并生成中间特征图。
- 特征图拆分:生成的中间特征图被拆分成两部分,一部分直接传递到最终的Concat块,另一部分传递到多个Bottleneck块进行进一步处理。
- Bottleneck块:输入到这些Bottleneck块的特征图通过一系列的卷积、归一化和激活操作进行处理,最后生成的特征图会与直接传递的那部分特征图在Concat块进行拼接(Concat)。
- 模型深度控制:在C2f模块中,Bottleneck模块的数量由模型的depth_multiple参数定义,这意味着可以根据需求灵活调整模块的深度和计算复杂度。
- 最终卷积块:拼接后的特征图会输入到一个最终的卷积块进行进一步处理,生成最终的输出特征图。
模块功能
- 特征提取:通过初始的卷积块提取输入图像的基本特征。
- 特征增强:通过多个Bottleneck块进一步提炼和增强特征,这些Bottleneck块可以捕捉更复杂的模式和细节。
- 特征融合:通过Concat块将直接传递的特征图和处理后的特征图进行融合,使得模型可以综合利用多尺度、多层次的信息。
- 输出生成:通过最后的卷积块生成最终的特征图,为后续的检测和分类任务提供丰富的特征表示。
空间金字塔池化快速(SPPF)模块:
SPPF(Spatial Pyramid Pooling - Fast)块是为了高效地捕捉多尺度信息而设计的,它利用简化版的空间金字塔池化。这个块允许网络处理不同尺度的特征,这在目标检测任务中特别有用,因为目标在图像中可能以不同的大小出现。
SPPF块的结构
-
初始卷积块:
- 输入特征图首先通过一个卷积块处理。 卷积核大小为1x1,输出通道数与输入特征图相同。这个卷积层的作用是减少计算量,同时提取初步特征。
- 组件:
- 卷积层(Conv2d)
- 批归一化(BatchNorm2d)
- 激活函数(通常是SiLU或ReLU)
-
MaxPool2d层:
池化层用于下采样输入体积的空间维度,减少网络的计算复杂度并提取主要特征。最大池化是一种特定的池化操作,对于输入张量的每个区域,仅保留最大值,其他值则被丢弃。
在MaxPool2d的情况下,池化在输入张量的高度和宽度维度上进行。该层通过指定池化核的大小和步幅来定义。核大小决定每个池化区域的空间范围,步幅则决定连续池化区域之间的步长。
- 初始卷积块的输出特征图经过三个MaxPool2d层。
- 每个MaxPool2d层使用特定的卷积核大小和步幅对特征图进行池化,下采样特征图。
- 这些层通过在特征图的不同区域上进行池化来捕捉不同尺度的信息。
-
拼接:
- 三个MaxPool2d层的输出特征图在通道维度上拼接。
- 这个操作将多尺度特征结合到一个特征图中,丰富了特征表示。
-
最终卷积块: 拼接后的特征图再经过一个卷积层,卷积核大小为1x1,输出通道数与初始输入特征图相同。这个卷积层的作用是融合不同尺度的特征,生成最终的输出特征图。
- 组件:
- 卷积层(Conv2d)
- 批归一化(BatchNorm2d)
- 激活函数(通常是SiLU或ReLU)
- 组件:
SPPF块的伪代码
以下是SPPF块的概念伪代码表示:
import torch import torch.nn as nn class SPPFBlock(nn.Module): def __init__(self, in_channels, out_channels, pool_size=5): super(SPPFBlock, self).__init__() self.initial_conv = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0), nn.BatchNorm2d(out_channels), nn.SiLU() ) self.pool1 = nn.MaxPool2d(kernel_size=pool_size, stride=1, padding=pool_size // 2) self.pool2 = nn.MaxPool2d(kernel_size=pool_size, stride=1, padding=pool_size // 2) self.pool3 = nn.MaxPool2d(kernel_size=pool_size, stride=1, padding=pool_size // 2) self.final_conv = nn.Sequential( nn.Conv2d(out_channels * 4, out_channels, kernel_size=1, stride=1, padding=0), nn.BatchNorm2d(out_channels), nn.SiLU() ) def forward(self, x): x_initial = self.initial_conv(x) x1 = self.pool1(x_initial) x2 = self.pool2(x1) x3 = self.pool3(x2) x_concat = torch.cat((x_initial, x1, x2, x3), dim=1) x_final = self.final_conv(x_concat) return x_final # 使用示例 sppf_block = SPPFBlock(in_channels=64, out_channels=128) output = sppf_block(input_tensor)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
代码解释
-
SPPFBlock 类:
- 构造函数初始化了三个主要组件:
initial_conv、pool1、pool2、pool3和final_conv。 initial_conv是一个顺序块,包括卷积、批归一化和SiLU激活。pool1、pool2和pool3是三个MaxPool2d层,它们通过不同的卷积核大小和步幅对特征图进行池化。final_conv是一个卷积块,用于处理拼接后的特征图。
- 构造函数初始化了三个主要组件:
-
forward 方法:
- 输入张量
x通过initial_conv处理。 - 输出特征图依次通过
pool1、pool2和pool3层。 - 这些层的输出在通道维度上拼接。
- 拼接后的特征图通过
final_conv处理,生成最终的输出。
- 输入张量

检测块(Detect Block)
检测块负责检测物体。与之前版本的YOLO不同,YOLOv8是一个无锚点模型,这意味着它直接预测物体的中心,而不是从已知的锚点框的偏移量进行预测。无锚点检测减少了框预测的数量,加快了推理后筛选候选检测结果的复杂后处理步骤。检测块包含两个轨道。第一轨道用于边界框预测,第二轨道用于类别预测。这两个轨道都包含两个卷积块,随后是一个单独的Conv2d层,分别给出边界框损失和类别损失。
检测块的结构
- 输入特征图:
- 输入特征图来自之前网络层的输出。
- 两个卷积块(每个轨道):
- 每个卷积块包含以下组件:
- 卷积层(Conv2d)
- 批归一化(BatchNorm2d)
- 激活函数(通常是SiLU或ReLU)
- 每个卷积块包含以下组件:
- 单独的Conv2d层(每个轨道):
- 用于边界框预测的轨道输出一个Conv2d层,得到边界框损失。
- 用于类别预测的轨道输出一个Conv2d层,得到类别损失。

Backbone
由最上面的YOLOv8网络结构图我们可以看出在其中的Backbone部分,由5个卷积模块和4个C2f模块和一个SPPF模块组成,

对应到yolo的yaml文件中的:
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 第0层,-1代表将上层的输入作为本层的输入。第0层的输入是640*640*3的图像。Conv代表卷积层,相应的参数:64代表输出通道数,3代表卷积核大小k,2代表stride步长。
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 第1层,本层和上一层是一样的操作(128代表输出通道数,3代表卷积核大小k,2代表stride步长)
- [-1, 3, C2f, [128, True]] # 第2层,本层是C2f模块,3代表本层重复3次。128代表输出通道数,True表示Bottleneck有shortcut。
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 第3层,进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为80*80*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/8。
- [-1, 6, C2f, [256, True]] # 第4层,本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。256代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是80*80*256。
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 第5层,进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/16。
- [-1, 6, C2f, [512, True]] # 第6层,本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。512代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是40*40*512。
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 第7层,进行卷积操作(1024代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*1024(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/32。
- [-1, 3, C2f, [1024, True]] #第8层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是20*20*1024。
- [-1, 1, SPPF, [1024, 5]] # 9 第9层,本层是快速空间金字塔池化层(SPPF)。1024代表输出通道数,5代表池化核大小k。结合模块结构图和代码可以看出,最后concat得到的特征图尺寸是20*20*(512*4),经过一次Conv得到20*20*1024。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
第0层:Conv卷积
在Block 0中,处理从大小为 ( 640 × 640 × 3 ) (640 \times 640 \times 3) (640×640×3)的输入图像开始,输入图像被送入一个卷积块,该卷积块的参数如下:卷积核大小为3,步长为2,填充为1。当使用步长为2时,空间分辨率会减少。以下是具体的计算过程:
-
输入图像:输入图像的尺寸为 ( 640 × 640 × 3 ) (640 \times 640 \times 3) (640×640×3),其中640表示高度和宽度,3表示颜色通道(RGB)。
-
卷积块参数:
- 卷积核大小:3
- 步长:2
- 填充:1
-
步长和填充的影响:
- 步长:步长为2意味着卷积核每次移动2个像素。这将输入图像的空间尺寸减半。
- 填充:填充为1意味着在输入图像的每一边都增加一圈零,这有助于在卷积后保持空间维度。
-
输出计算:
- 计算卷积操作输出尺寸
(
(
W
o
u
t
×
H
o
u
t
)
)
( (W_{out} \times H_{out}) )
((Wout×Hout))的公式为:
W o u t = ( W i n − 卷积核大小 + 2 × 填充 ) 步长 + 1 W_{out} = \frac{(W_{in} - \text{卷积核大小} + 2 \times \text{填充})}{\text{步长}} + 1 Wout=步长(Win−卷积核大小+2×填充)+1
H o u t = ( H i n − 卷积核大小 + 2 × 填充 ) 步长 + 1 H_{out} = \frac{(H_{in} - \text{卷积核大小} + 2 \times \text{填充})}{\text{步长}} + 1 Hout=步长(Hin−卷积核大小+2×填充)+1
代入公式计算:
W o u t = ( 640 − 3 + 2 × 1 ) 2 + 1 = 640 − 3 + 2 2 + 1 = 639 2 + 1 = 320 W_{out} = \frac{(640 - 3 + 2 \times 1)}{2} + 1 = \frac{640 - 3 + 2}{2} + 1 = \frac{639}{2} + 1 = 320 Wout=2(640−3+2×1)+1=2640−3+2+1=2639+1=320
H o u t = ( 640 − 3 + 2 × 1 ) 2 + 1 = 640 − 3 + 2 2 + 1 = 639 2 + 1 = 320 H_{out} = \frac{(640 - 3 + 2 \times 1)}{2} + 1 = \frac{640 - 3 + 2}{2} + 1 = \frac{639}{2} + 1 = 320 Hout=2(640−3+2×1)+1=2640−3+2+1=2639+1=320因此,输出特征图的尺寸为 ( 320 × 320 ) (320 \times 320) (320×320)。
- 计算卷积操作输出尺寸
(
(
W
o
u
t
×
H
o
u
t
)
)
( (W_{out} \times H_{out}) )
((Wout×Hout))的公式为:
-
输出特征图:
- 卷积块产生的特征图尺寸为 ( 320 × 320 × C ) (320 \times 320 \times C) (320×320×C),其中 ( C ) (C) (C)是卷积层的输出通道数量,由使用的卷积核数量决定。例如,如果卷积层有64个卷积核,输出特征图的尺寸将为 ( 320 × 320 × 64 ) (320 \times 320 \times 64) (320×320×64)。
经过一个卷积核大小为3、步长为2、填充为1的卷积块后,输入尺寸为 ( 640 × 640 × 3 ) (640 \times 640 \times 3) (640×640×3)的图像被减少到尺寸为 ( 320 × 320 ) (320 \times 320 ) (320×320)的特征图。由于步长为2,空间分辨率减半。
第2层 C2f模块
YOLOv8中的C2f模块由多个瓶颈块组成,具有两个关键参数:
-
shortcut:一个布尔值,表示瓶颈块是否使用快捷连接。- 如果
shortcut = true,则C2f模块内的瓶颈块使用快捷连接(残差连接)。输入 -----> 1x1卷积 -----> 3x3卷积 -----> 1x1卷积 -----> 输出 - 如果
shortcut = false,则C2f模块内的瓶颈块不使用快捷连接。输入 -----> 1x1卷积 -----> 3x3卷积 -----> 1x1卷积 -----> 输出
- 如果
-
n:- 该参数指定C2f模块内瓶颈块的数量。
- 它的计算公式为 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/995580?site
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

