
- 1贪心算法原理_贪心算法不是最优解
- 2token一般出现的位置_token怎么在网页里找
- 3Springboot为啥要有第二级缓存_spring二级缓存有什么用
- 4用递归实现1到n的从小到大排列(数字不重复)_1、给定数组a,其中有n个元素且按照字典序从小到大排列: a={1, 3, 5, 7} 使用递归
- 5编程二十年,38岁Google程序员万字长文给出16条建议,涉创业、技术淘汰、拿大厂offer...值得学习思考_程序员如何创业
- 6数据结构-C语言链表模拟_p=(node)malloc(sizeof(node))
- 7首批成员单位!九州未来加入“算力网络+”先锋计划
- 8MySQL进阶-MySQL管理
- 9关闭和卸载亚信安全助手
- 10AI全栈大模型工程师(十)查询数据库_大模型 数据查询
计算机眼中的图像-基于OpenCV的深入解析与实践
赞
踩
本文收录于专栏:精通AI实战千例专栏合集
https://blog.csdn.net/weixin_52908342/category_11863492.html
- 1
从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。
每一个案例都附带关键代码,详细讲解供大家学习,希望可以帮到大家。正在不断更新中~
计算机眼中的图像-基于OpenCV的深入解析与实践
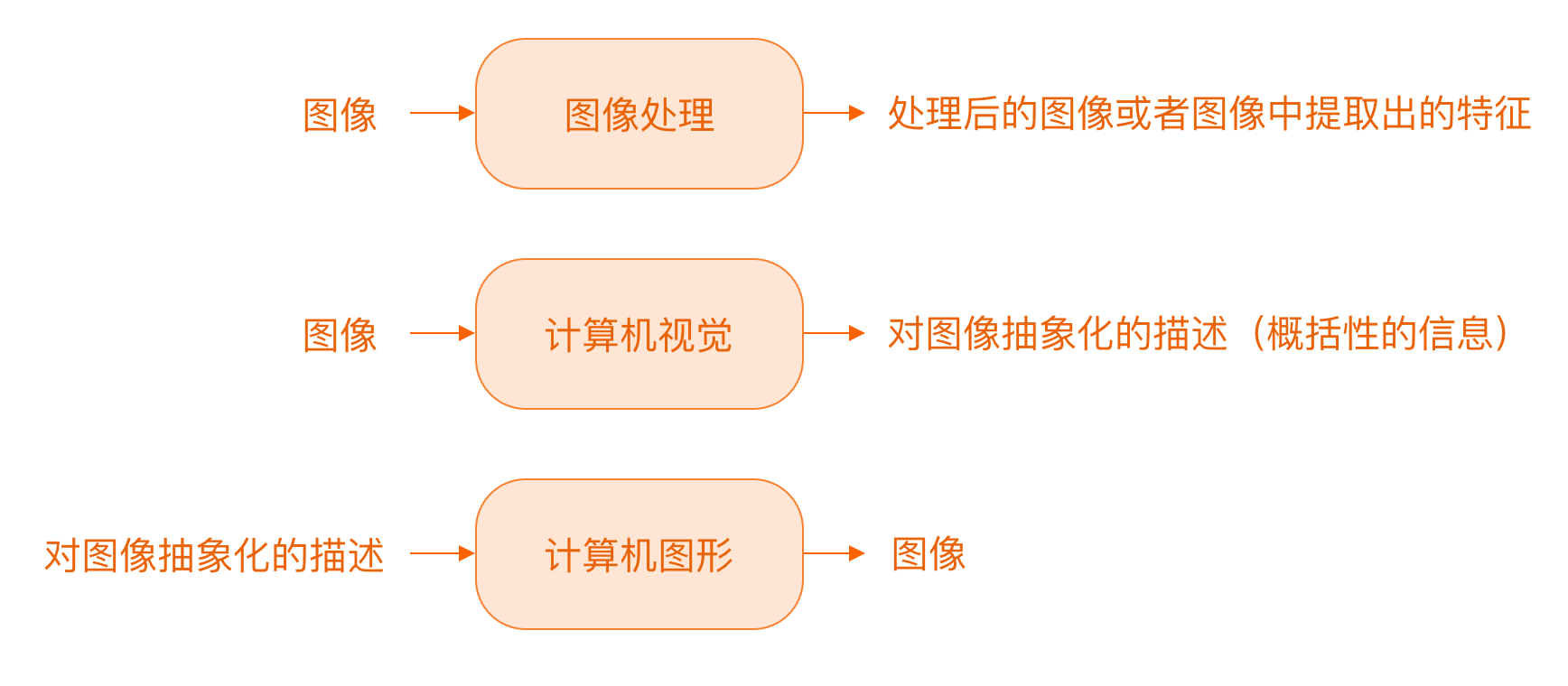
在计算机视觉领域,图像是计算机感知世界的窗口。计算机通过图像处理算法将图像转化为可以理解和分析的信息。这一过程涉及多个阶段,包括图像预处理、特征提取、对象检测和图像分析等。OpenCV(Open Source Computer Vision Library)是一个强大的开源库,广泛用于计算机视觉和图像处理任务。本文将探讨计算机如何“看到”图像,并通过OpenCV代码示例展示如何实现这些技术。
1. 图像预处理
在计算机处理图像之前,通常需要对图像进行预处理,以提高后续处理的准确性。常见的预处理操作包括灰度化、图像平滑和去噪。
1.1 灰度化
灰度化是将彩色图像转换为灰度图像的过程。灰度图像包含的信息较少,但处理速度更快,适合进行后续分析。
import cv2
# 读取彩色图像
color_image = cv2.imread('color_image.jpg')
# 转换为灰度图像
gray_image = cv2.cvtColor(color_image, cv2.COLOR_BGR2GRAY)
# 显示灰度图像
cv2.imshow('Gray Image', gray_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
1.2 图像平滑与去噪
图像平滑可以去除图像中的噪声。常用的平滑方法包括高斯模糊和中值滤波。
# 高斯模糊
smooth_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
# 中值滤波
median_image = cv2.medianBlur(gray_image, 5)
# 显示结果
cv2.imshow('Gaussian Blur', smooth_image)
cv2.imshow('Median Blur', median_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2. 特征提取
特征提取是从图像中提取有用信息的过程。这些特征可以用于图像分类、目标检测等任务。常见的特征提取方法包括边缘检测和角点检测。
2.1 边缘检测
边缘检测用于识别图像中物体的边界。常用的边缘检测算法是Canny边缘检测。
# Canny边缘检测
edges = cv2.Canny(gray_image, 100, 200)
# 显示边缘检测结果
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.2 角点检测
角点检测用于检测图像中角点的位置。Harris角点检测是常用的方法之一。
# Harris角点检测
harris_corners = cv2.cornerHarris(gray_image, 2, 3, 0.04)
# 归一化和显示结果
harris_corners = cv2.dilate(harris_corners, None)
color_image[harris_corners > 0.01 * harris_corners.max()] = [0, 0, 255]
cv2.imshow('Harris Corners', color_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

3. 对象检测
对象检测旨在识别和定位图像中的对象。常见的对象检测技术包括基于模板匹配和基于机器学习的方法。
3.1 模板匹配
模板匹配是一种简单的对象检测方法,通过与模板图像的匹配来识别目标。
# 读取模板图像和待检测图像 template = cv2.imread('template.jpg', 0) w, h = template.shape[::-1] # 使用模板匹配 res = cv2.matchTemplate(gray_image, template, cv2.TM_CCOEFF_NORMED) threshold = 0.8 loc = np.where(res >= threshold) # 绘制矩形框 for pt in zip(*loc[::-1]): cv2.rectangle(color_image, pt, (pt[0] + w, pt[1] + h), (0, 255, 0), 2) cv2.imshow('Template Matching', color_image) cv2.waitKey(0) cv2.destroyAllWindows()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.2 基于机器学习的检测
更复杂的对象检测方法包括基于卷积神经网络(CNN)的检测算法,如YOLO和SSD。这些方法能够处理复杂的检测任务,但在这里我们将不详细介绍这些方法的实现。
好的,我们继续深入探讨计算机如何理解和处理图像,从对象检测开始。
4. 对象检测
4.1 模板匹配
模板匹配是一种经典的对象检测技术,通过在图像中滑动模板并计算匹配度来识别目标。尽管简单,但在某些应用中仍然有效,特别是当目标在图像中变化不大时。
以下是模板匹配的详细代码示例:
import cv2 import numpy as np # 读取待检测图像和模板图像 image = cv2.imread('image.jpg') gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) template = cv2.imread('template.jpg', 0) w, h = template.shape[::-1] # 模板匹配 res = cv2.matchTemplate(gray_image, template, cv2.TM_CCOEFF_NORMED) threshold = 0.8 loc = np.where(res >= threshold) # 绘制矩形框标记匹配结果 for pt in zip(*loc[::-1]): cv2.rectangle(image, pt, (pt[0] + w, pt[1] + h), (0, 255, 0), 2) cv2.imshow('Template Matching', image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4.2 基于机器学习的检测
在实际应用中,模板匹配方法的局限性很明显,特别是在目标形状、大小或旋转角度发生变化时。为了处理这些复杂的情况,计算机视觉领域引入了基于机器学习的方法。以下是一些主流的对象检测技术:
4.2.1 YOLO(You Only Look Once)
YOLO是一种高效的对象检测方法,通过将整个图像划分为网格,并在每个网格中预测边界框和类别。YOLO的关键特点是其端到端的训练方式,使其在实时检测中表现出色。
OpenCV库支持YOLO模型的加载和推理。以下是如何使用YOLO进行对象检测的示例代码:
import cv2 # 加载YOLO模型 net = cv2.dnn.readNet('yolov3.weights', 'yolov3.cfg') layer_names = net.getLayerNames() output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()] # 读取图像 image = cv2.imread('image.jpg') height, width, channels = image.shape # 预处理图像 blob = cv2.dnn.blobFromImage(image, 0.00392, (416, 416), (0, 0, 0), True, crop=False) net.setInput(blob) outs = net.forward(output_layers) # 解析检测结果 class_ids = [] confidences = [] boxes = [] for out in outs: for detection in out: for obj in detection: scores = obj[5:] class_id = np.argmax(scores) confidence = scores[class_id] if confidence > 0.5: center_x = int(obj[0] * width) center_y = int(obj[1] * height) w = int(obj[2] * width) h = int(obj[3] * height) x = int(center_x - w / 2) y = int(center_y - h / 2) boxes.append([x, y, w, h]) confidences.append(float(confidence)) class_ids.append(class_id) # 应用非极大值抑制 indices = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4) for i in indices: i = i[0] box = boxes[i] x, y, w, h = box cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2) cv2.imshow('YOLO Detection', image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
4.2.2 SSD(Single Shot MultiBox Detector)
SSD是一种基于卷积神经网络(CNN)的对象检测算法,通过在不同尺度的特征图上进行检测来处理多尺度的目标。
以下是如何使用SSD进行对象检测的示例代码:
import cv2 # 加载SSD模型 net = cv2.dnn.readNet('deploy.prototxt', 'ssd.caffemodel') layer_names = net.getLayerNames() output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()] # 读取图像 image = cv2.imread('image.jpg') height, width, channels = image.shape # 预处理图像 blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (127.5, 127.5, 127.5), swapRB=True, crop=False) net.setInput(blob) outs = net.forward(output_layers) # 解析检测结果 for detection in outs[0][0]: for obj in detection: confidence = obj[2] if confidence > 0.5: box = obj[3:7] * np.array([width, height, width, height]) (x, y, x2, y2) = box.astype('int') cv2.rectangle(image, (x, y), (x2, y2), (0, 255, 0), 2) cv2.imshow('SSD Detection', image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
5. 图像分割
图像分割是将图像分解为多个区域,以便进行更细致的分析。常用的分割方法包括阈值分割、轮廓检测和基于深度学习的方法。
5.1 阈值分割
阈值分割是一种简单而有效的图像分割技术,通过设置阈值将图像分成前景和背景。
# 二值化处理
_, binary_image = cv2.threshold(gray_image, 127, 255, cv2.THRESH_BINARY)
# 显示结果
cv2.imshow('Binary Image', binary_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.2 轮廓检测
轮廓检测用于提取图像中的边界信息,常用于对象的形状分析。
# 查找轮廓
contours, _ = cv2.findContours(binary_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制轮廓
cv2.drawContours(image, contours, -1, (0, 255, 0), 2)
cv2.imshow('Contours', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
5.3 基于深度学习的分割
深度学习方法,如U-Net和Mask R-CNN,提供了强大的图像分割能力,特别是在复杂场景下表现优异。
6. 目标跟踪
目标跟踪是指在视频序列中持续跟踪特定对象。常见的跟踪算法包括KLT跟踪、Meanshift和Camshift。
6.1 KLT跟踪
KLT(Kanade-Lucas-Tomasi)跟踪是一种基于角点的跟踪方法,适用于短期跟踪任务。
# 初始化视频捕捉 cap = cv2.VideoCapture('video.mp4') # 读取第一帧 ret, frame = cap.read() gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 检测角点 p0 = cv2.goodFeaturesToTrack(gray_frame, mask=None, **feature_params) # 创建掩码图像用于绘制 mask = np.zeros_like(frame) while True: ret, frame = cap.read() if not ret: break gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) p1, st, err = cv2.calcOpticalFlowPyrLK(gray_frame, gray_frame, p0, None) if p1 is not None: for i, (new, old) in enumerate(zip(p1, p0)): a, b = new.ravel() c, d = old.ravel() mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2) frame = cv2.circle(frame, (a, b), 5, color[i].tolist(), -1) img = cv2.add(frame, mask) cv2.imshow('KLT Tracking', img) if cv2.waitKey(30) & 0xFF == 27: break cap.release() cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
6.2 Meanshift和Camshift
Meanshift和Camshift算法用于对象跟踪,通过跟踪目标的颜色直方图来实现跟踪。
# 读取第一帧并初始化ROI ret, frame = cap.read() roi = cv2.selectROI(frame, False) hsv_roi = cv2.cvtColor(frame , cv2.COLOR_BGR2HSV) roi_hist = cv2.calcHist([hsv_roi], [0, 1], roi, [16, 16], [0, 180, 0, 256]) # 归一化直方图 roi_hist /= roi_hist.sum() # Meanshift初始化 term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1) while True: ret, frame = cap.read() if not ret: break hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) back_proj = cv2.calcBackProject([hsv], [0, 1], roi_hist, [0, 180, 0, 256], 1) ret, roi = cv2.meanShift(back_proj, roi, term_crit) x, y, w, h = roi frame = cv2.rectangle(frame, (x, y), (x+w, y+h), 255, 2) cv2.imshow('Meanshift Tracking', frame) if cv2.waitKey(30) & 0xFF == 27: break cap.release() cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
7. 图像恢复
图像恢复技术用于修复图像中的缺陷,例如去除噪声、修复丢失的区域等。常见的图像恢复技术包括去噪、图像修复和超分辨率重建。
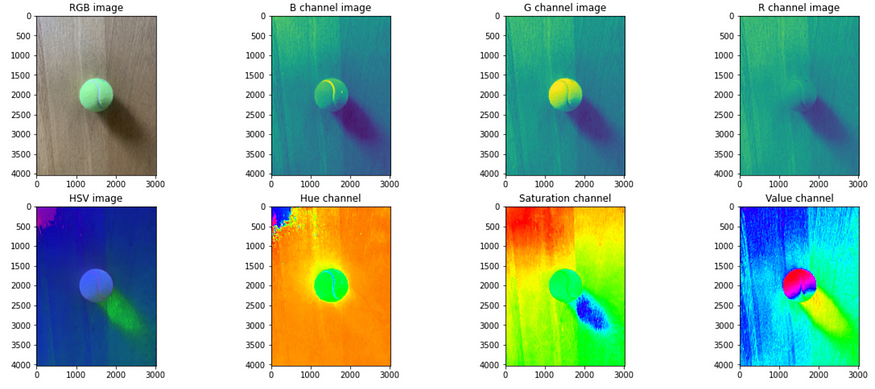
7.1 去噪
去噪技术包括多种滤波器,如高斯滤波器、双边滤波器等。
# 双边滤波
denoised_image = cv2.bilateralFilter(color_image, 9, 75, 75)
cv2.imshow('Denoised Image', denoised_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
7.2 图像修复
图像修复用于修补图像中的缺陷区域。OpenCV提供了inpaint函数来实现这一功能。
# 读取图像和掩模
image = cv2.imread('damaged_image.jpg')
mask = cv2.imread('mask.jpg', 0)
# 图像修复
restored_image = cv2.inpaint(image, mask, 3, cv2.INPAINT_TELEA)
cv2.imshow('Restored Image', restored_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
7.3 超分辨率重建
超分辨率技术通过重建更高分辨率的图像来提升图像质量。OpenCV提供了实现超分辨率的工具。
# 创建超分辨率重建对象
sr = cv2.dnn_superres.DnnSuperResImpl_create()
sr.readModel('EDSR_x3.pb')
sr.setModel('edsr', 3)
# 读取图像并应用超分辨率
image = cv2.imread('low_res_image.jpg')
result = sr.upsample(image)
cv2.imshow('Super Resolution', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
8. 结论
计算机眼中的图像处理技术涵盖了从图像预处理到目标检测、图像分割、目标跟踪和图像恢复的广泛领域。OpenCV提供了强大的工具和函数来实现这些技术,使得计算机视觉应用得以实现和优化。在实际应用中,结合这些技术可以构建出功能强大且高效的图像处理系统。

