
- 1探索mp-html:小程序富文本组件的强大力量
- 2sql注入(5), sqlmap工具_sqlmap注入等级
- 3Elasticsearch搜索中文分词优化-ik_max_word,和ik_smart模式_ik max word
- 4中文自然语言处理入门实战_中文自然语言处理基础与实战
- 5OpenCV移植到ARM9_arm+lvgl+opencv
- 6信号处理 | 短时傅里叶变换实战
- 7使用JsonPath字符串获取json内容_jsonpath提取json数据
- 8【十八】【C++】deque双端队列简单使用和deque底层实现探究(部分代码)_c++ 双端队列dqueue
- 9HarmonyOS实战开发-如何在鸿蒙开发中使用数据库_鸿蒙数据库开发
- 10神经网络与自然语言处理(NLP)相关的模型网络总结_机器学习 卷积神经网络 和大语言模型关系
2024年最新大数据开发八股文总结——Hadoop_大数据八股文(1),各种风格的大数据开发面试题进来了解一下_数据分析八股文
赞
踩

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
一旦NameNode断电,就会合并Fsimage文件和Edits文件,合成元数据。引入的Secondary NameNode 专门用于合并两个文件。


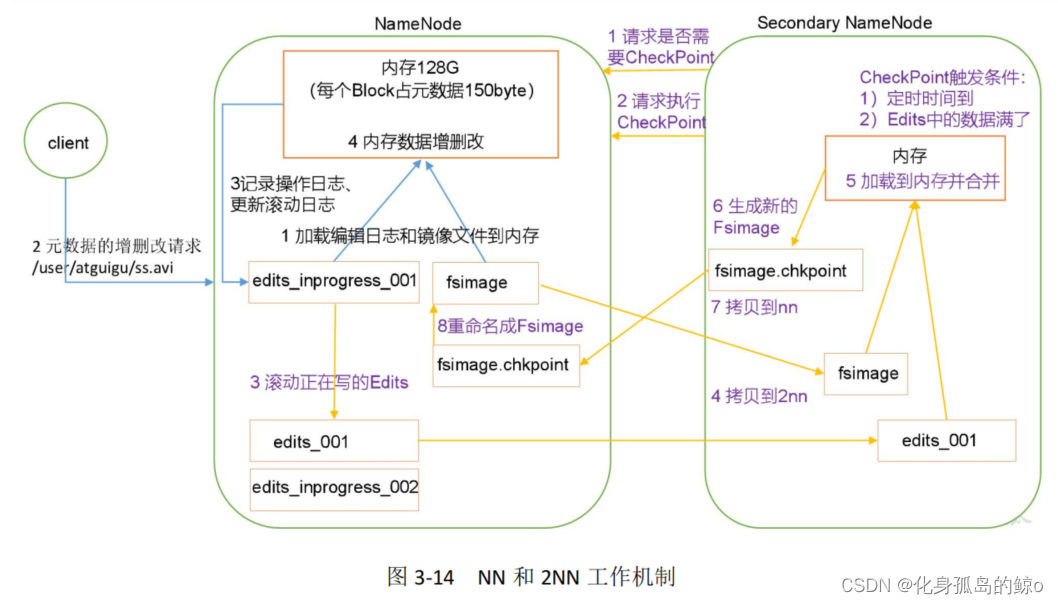
第一阶段:NameNode 启动
(1)第一次启动 NameNode 格式化后,创建 Fsimage 和 Edits 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode 记录操作日志,更新滚动日志。
(4)NameNode 在内存中对数据进行增删改。
第二阶段:Secondary NameNode 工作
(1)Secondary NameNode 询问 NameNode 是否需要 CheckPoint。直接带回 NameNode是否检查结果。
(2)Secondary NameNode 请求执行 CheckPoint。
(3)NameNode 滚动正在写的 Edits 日志。
(4)将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode。
(5)Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件 fsimage.chkpoint。
(7)拷贝 fsimage.chkpoint 到 NameNode。
(8)NameNode 将 fsimage.chkpoint 重新命名成 fsimage。
扩展问题:为什么HDFS不适合批量存储小文件?
小文件的定义:
文件大小小于或者等于30M的文件
HDFS小文件带来危害:
(1)小文件数量过多(例如图片)会占用批量占用Namenode的内存,因为每个存储在HDFS中的文件的元数据(包括目录树,位置信息,命名空间镜像fsimage,文件编辑信息edits)都会在Namenode中占用150B的内存,如果Namenode存储空间满了,就不能继续存储新文件了。
(2)如果有多小文件,会造成寻道时间>=读取文件时间(传输文件时间 = 寻道时间+读取文件时间),这与HDFS的原理相违背,HDFS的设计是为了减小寻道时间,使其远小于读取文件的时间。Hive或者Spark计算的时候会影响他们的速度,因为Spark计算时会将数据从硬盘读到内存,零碎的文件将产生较多的寻道过程。
(3)流式读取的方式,不适合多用户写入,以及任意位置写入。如果访问小文件,则必须从一个Datanode跳转到另外一个Datanode,这样大大降低了读取性能。



扩展问题:数据在DataNode中如何存储?
HDFS默认的数据存储块是64MB,现在新版本的hadoop环境(2.7.3版本后),默认的数据存储块是128MB。
一个文件如果小于128MB,则按照真实的文件大小独占一个数据存储块,存放到DataNode节点中。同时 DataNode一般默认存三份副本,以保障数据安全。 同时该文件所存放的位置也写入到NameNode的内存中,如果有Secondary NameNode高可用节点,也可同时复制一份过去。NameNode的内存数据将会存放到硬盘中,如果HDFS发生重启,将产生较长时间的元数据从硬盘读到内存的过程。
如果一个文件大于128MB,则HDFS自动将其拆分为128MB大小,存放到HDFS中,并在NameNode内存中留下其数据存放的路径。不同的数据块将存放到可能不同的DataNode中。
扩展问题:HDFS的文件存储格式有哪些?
Hadoop文件格式学习
HDFS的文件存储格式以及HDFS异构存储和存储策略
大数据存储数据,99%以上的场景都是使用的是列式存储。
MapReduce
1.什么是MapReduce?
MapReduce是一个分布式运算程序的编程框架,它的核心功能是将用户编写的业务逻辑代码和自带默认组件代码整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
扩展理解:
MapReduce是一种分布式计算模型,它主要用于大规模数据的处理和分析。在MapReduce模型中, Map函数和Reduce函数都是非常重要的组成部分,它们分别在数据预处理和结果合并阶段发挥重要作用。
Map函数一般用来对数据进行预处理。当MapReduce模型读取数据时, Map函数会对每个数据块进行处理。Map函数的输入是键-值对输出也是键-值对。Map函数可以将输入的键-值对映射为任意数量的键-值对输出。例如,一个典型的Map函数可以将一个文档分解为单词,并将每个单词映射为一个键-值对。在这个例子中,键是单词,值是1或者是出现次数。Ma

