
热门标签
热门文章
- 1生成3的乘方表 (15分)_7-13 生成3的乘方表 分数 15 作者 c课程组 单位 浙江大学 输入一个非负整数n,生成
- 2读书笔记-增强型分析:AI驱动的数据分析、业务决策与案例实践_增强型分析 ai
- 3PHY RGMII Interface Timing注意事项_rgmii-rxid
- 4三分钟彻底搞懂PostgreSQL 和 MySQL 区别之分_postgresql和mysql区别
- 5如何更改电脑密码?让黑客无机可乘!
- 6深入理解PHP的$_SESSION机制
- 7Fastjson反序列化漏洞(自学)_fastjson反序列化漏洞利用链
- 8计算机毕业设计springboot健康监测管理系统7f3049【附源码+数据库+部署+LW】_springbooth睡眠检测
- 9智能客服_qa机器人
- 10elasticsearch 对 SQL的支持_es的客户端支持sql语言开发吗
当前位置: article > 正文
Hive中SQL基本操作_hive sql
作者:神奇cpp | 2024-08-01 02:36:05
赞
踩
hive sql
1. Hive 中DDL
结构化语言查询对于所有数据库语法都大同小异的。
1) 数据库操作
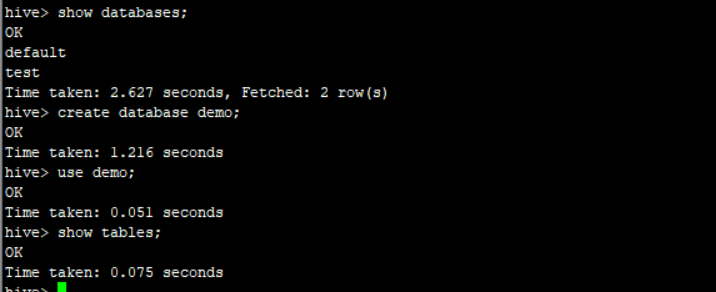
# 查询数据库
show databases;
# 切换数据库
USE database_name;
USE DEFAULT;
# 创建数据库
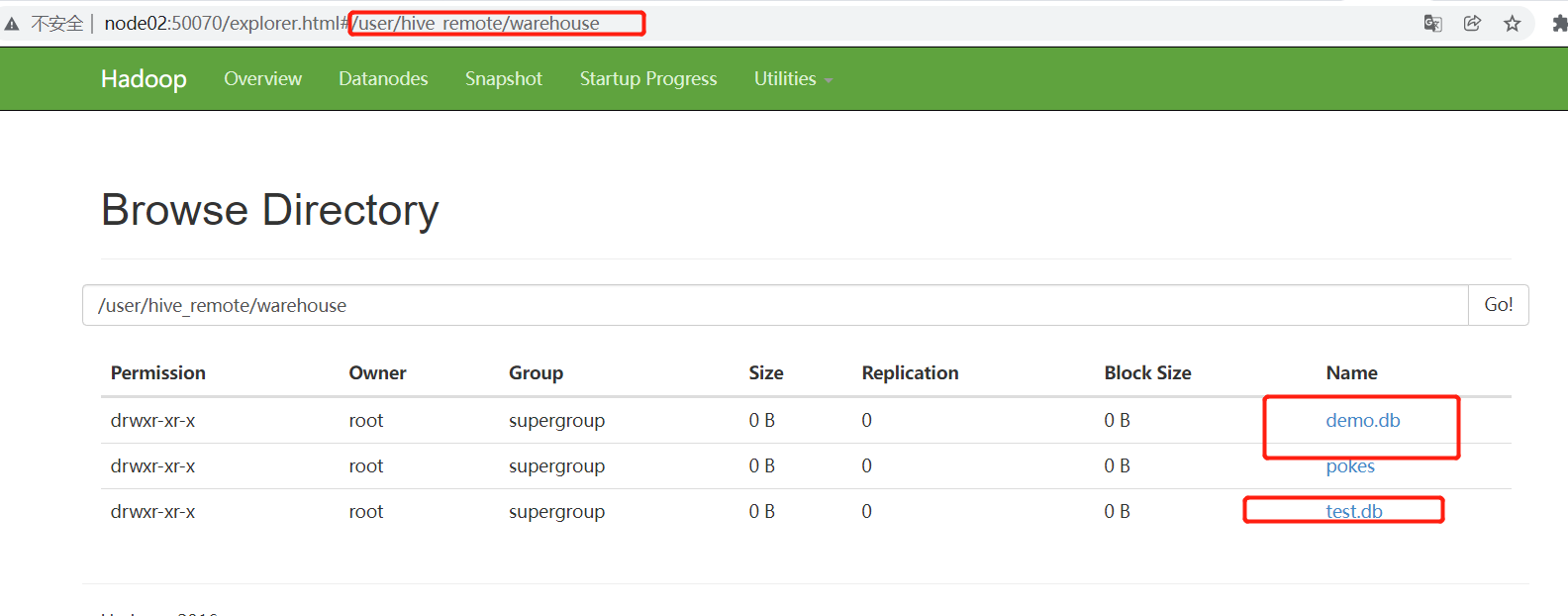
CREATE [REMOTE] (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
create DATABASE test;
# 删除数据库
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
drop database test;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
实操
2) 创建表 Create table
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later) [(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)] ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES] [ [ROW FORMAT row_format] [STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later) ] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later) [AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables) CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name LIKE existing_table_or_view_name [LOCATION hdfs_path]; # 数据类型 data_type : primitive_type | array_type | map_type | struct_type | union_type -- (Note: Available in Hive 0.7.0 and later) # 基本数据类型 primitive_type : TINYINT | SMALLINT | INT | BIGINT | BOOLEAN | FLOAT | DOUBLE | DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later) | STRING | BINARY -- (Note: Available in Hive 0.8.0 and later) | TIMESTAMP -- (Note: Available in Hive 0.8.0 and later) | DECIMAL -- (Note: Available in Hive 0.11.0 and later) | DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later) | DATE -- (Note: Available in Hive 0.12.0 and later) | VARCHAR -- (Note: Available in Hive 0.12.0 and later) | CHAR -- (Note: Available in Hive 0.13.0 and later) ## List集合 array_type : ARRAY < data_type > # map集合 map_type : MAP < primitive_type, data_type > # 结构 struct_type : STRUCT < col_name : data_type [COMMENT col_comment], ...> union_type : UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later) # 行格式,分隔符 row_format : DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later) | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)] # 文件格式 file_format: : SEQUENCEFILE | TEXTFILE -- (Default, depending on hive.default.fileformat configuration) | RCFILE -- (Note: Available in Hive 0.6.0 and later) | ORC -- (Note: Available in Hive 0.11.0 and later) | PARQUET -- (Note: Available in Hive 0.13.0 and later) | AVRO -- (Note: Available in Hive 0.14.0 and later) | JSONFILE -- (Note: Available in Hive 4.0.0 and later) | INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname # 列约束 column_constraint_specification: : [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ] default_value: : [ LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ] constraint_specification: : [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ] [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ] [, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE [, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ] [, CONSTRAINT constraint_name CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
实操
- 创建表从本地加载文件
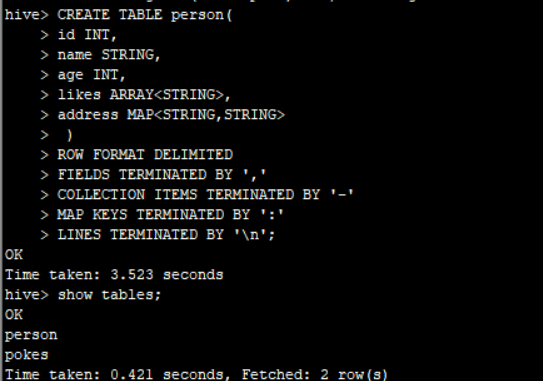
CREATE TABLE person(
id INT,
name STRING,
age INT,
likes ARRAY<STRING>,
address MAP<STRING,STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 准备数据文件
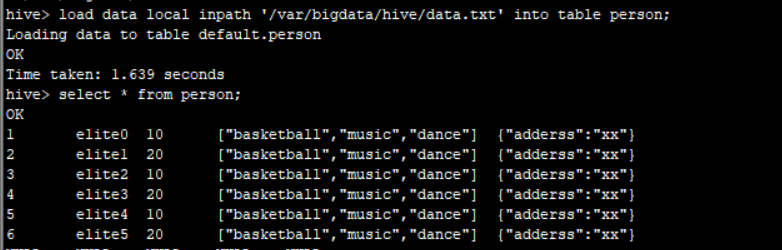
1,elite0,10,basketball-music-dance,adderss:xx
2,elite1,20,basketball-music-dance,adderss:xx
3,elite2,10,basketball-music-dance,adderss:xx
4,elite3,20,basketball-music-dance,adderss:xx
5,elite4,10,basketball-music-dance,adderss:xx
6,elite5,20,basketball-music-dance,adderss:xx
- 1
- 2
- 3
- 4
- 5
- 6
- 在linux下创建文件
mkdir -p /var/bigdata/hive/
cd /var/bigdata/hive/
vi data.txt
- 1
- 2
- 3
- 从文件加载数据到表
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
#加载本地文件到表
load data local inpath '/var/bigdata/hive/data.txt' into table person;
# 查询加载的数据
select * from person;
- 1
- 2
- 3
- 4
- 5
3)内部外部表区别
| 内部表 | 外部表 | |
|---|---|---|
| 创建语法 | CREATE TABLE [IF NOT EXISTS] table_name | CREATE EXTERNAL TABLE [IF NOT EXISTS] table_name |
| 区别 | 删除表时,元数据与数据都会被删除 | 删除外部表只删除metastore的元数据,不删除hdfs中的表数据 |
4) Create Table As Select (CTAS)
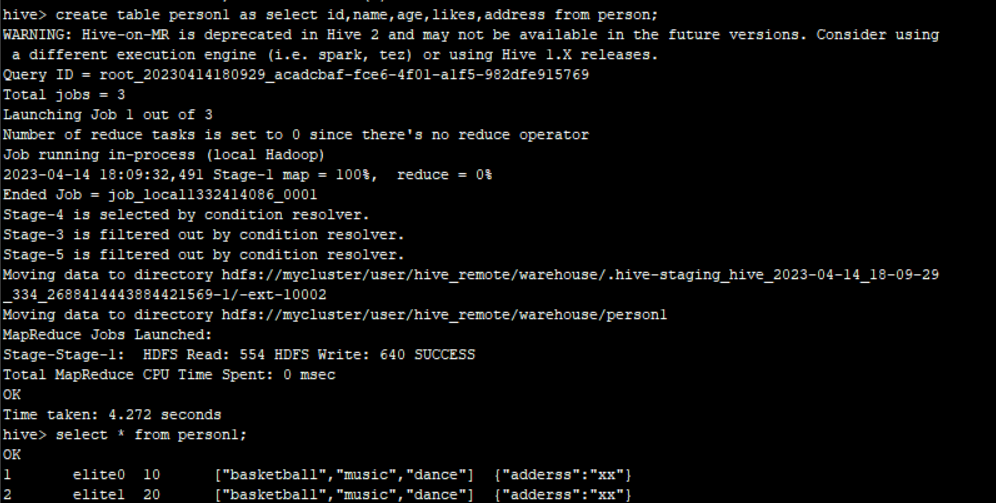
4)分区表 partition
单分区建表语句:
create table day_table (id int, content string) partitioned by(col string);
# 需要注意分区表的列创建的时候字段就不需要加,加上创建会报列重复
CREATE TABLE person3(
id INT,
name STRING,
likes ARRAY<STRING>,
address MAP<STRING,STRING>
)partitioned by(age int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
加载文件数据的时候需要指定分区
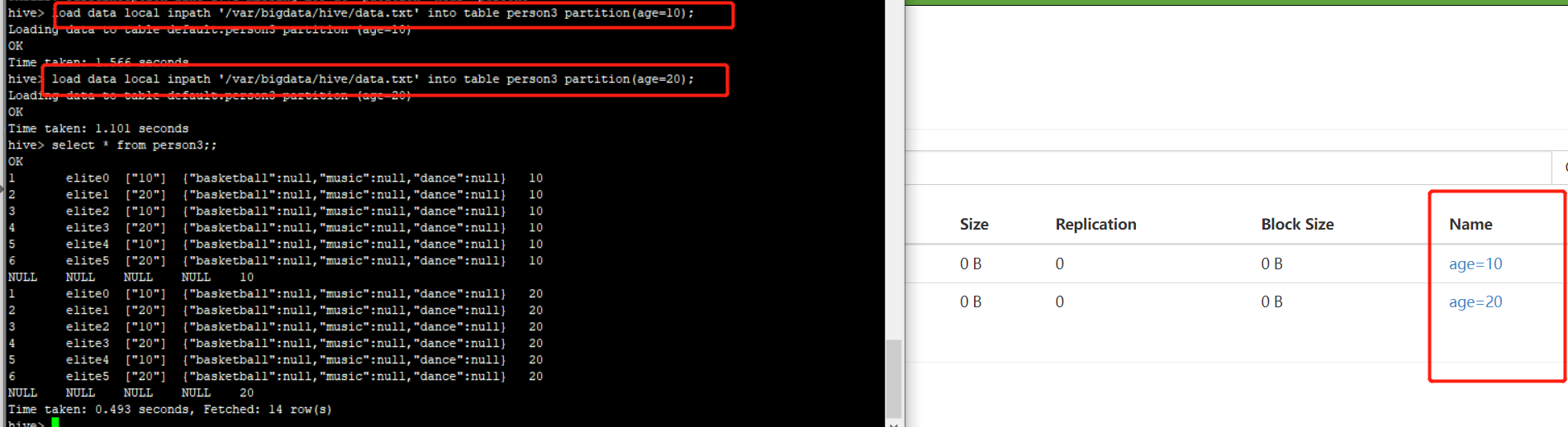
删除分区
ALTER TABLE table_name DROP partition_spec, partition_spec,...
##删除分区
ALTER TABLE person3 DROP partition(age=20)
- 1
- 2
- 3
效果如下
ALTER TABLE person3 DROP partition(age=20);
Dropped the partition age=20
OK
Time taken: 0.831 seconds
hive> select * from person3;;
OK
1 elite0 ["10"] {"basketball":null,"music":null,"dance":null} 10
2 elite1 ["20"] {"basketball":null,"music":null,"dance":null} 10
3 elite2 ["10"] {"basketball":null,"music":null,"dance":null} 10
4 elite3 ["20"] {"basketball":null,"music":null,"dance":null} 10
5 elite4 ["10"] {"basketball":null,"music":null,"dance":null} 10
6 elite5 ["20"] {"basketball":null,"music":null,"dance":null} 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
双分区建表语句:
create table day_hour_table (id int, content string)
partitioned by (col1 string, col string);
- 1
- 2
其他的可以参考官网进行实战。
2 .Hive中 DML
1)从文件加载数据 Loading files into tables
语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
- 1
- 2
- 3
上边已经操作过,不在操作。
2)插入 INSERT
-
into Hive tables from queries
-
into directories from queries
-
into Hive tables from SQL
3)更新 UPDATE
UPDATE tablename SET column = value [, column = value ...] [WHERE expression]
- 1
4)删除 DELETE
DELETE FROM tablename [WHERE expression]
- 1
5)合并 MERGE
MERGE INTO <target table> AS T USING <source expression/table> AS S
ON <boolean expression1>
WHEN MATCHED [AND <boolean expression2>] THEN UPDATE SET <set clause list>
WHEN MATCHED [AND <boolean expression3>] THEN DELETE
WHEN NOT MATCHED [AND <boolean expression4>] THEN INSERT VALUES<value list>
- 1
- 2
- 3
- 4
- 5
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

