
- 12024年最全【微信小程序】电商移动前端API文档_免费的商城小程序api文档,2024年最新带你全面掌握高级知识点_微信小程序商城,真实api
- 2Lambda表达式及Stream的使用_stream lamda
- 3商汤用AI复活了汤老师
- 4用pycharm使用恒源云服务器的傻瓜操作_恒源云怎么将ide变成pycharm
- 5从天空到地面:无人机航拍推流直播技术在洞庭湖决口封堵中的全方位支援_基于决口形态及特征参数实时变化的装备辅助操控技术
- 6北漂生活第四弹-初入公司_北漂旭哥
- 7Android出海实战:Android14适配_android 14适配
- 8java反序列漏洞原理分析及防御修复方法_java反序列化的原理?
- 9Linux 登陆失败查询_linux如何查看ssh登录失败
- 10【JavaScript 逆向】dy滑块纯算,底图还原,captchaBody,轨迹算法,abogus_抖音滑块验证码 captchabody 逆向分析
目标检测学习笔记2——ResNet残差网络学习、ResNet论文解读_resnet目标检测论文
赞
踩
一、前言
在学习Yolo v3的过程中,了解到它借鉴了残差网络的快捷链路(shortcut connection),因此为了更好的理解yolo3,我对ResNet展开了学习,并阅读其论文。
ResNet—— Residual Network残差神经网络,是何恺明大神(Faster RCNN的作者)于2015年提出,在当年多个大赛中用此网络获得了第一名。
为什么会提出ResNet?
在深度神经网络中存在一个问题,大家都知道,网络层数加深,参数增多,网络表现能力理应更好。但随着深度的不断增加,会出现网络退化现象。
什么是网络退化现象?
神经网络随着层数加深,首先训练准确率会逐渐趋于饱和;若层数继续加深,反而训练准确率下降,效果不好了。
说通俗一点就是,我给孩子报了课外补习班(多加了好多层网络),但却发现我的孩子学习成绩反而没有参加课外补习班的孩子成绩好。
这既不是梯度爆炸、梯度消失造成,也不是过拟合造成。
梯度爆炸、梯度消失:梯度消失/爆炸是因为神经网络在反向传播的时候,反向连乘的梯度小于1(或大于1),导致连乘的次数多了之后(网络层数加深),传回首层的梯度过小甚至为0(过大甚至无穷大),这就是梯度消失/爆炸的概念。(我们已经在网络中加入了BN层(Batch Normalize),他可以通过规整数据的分布基本解决梯度消失/爆炸的问题,所以这个问题也不是导致深层网络退化的原因)
过拟合:网络在训练集上表现很好,在训练集上表现差。(如下图可见,无论是在训练集还是测试集中,拥有更深层次的网络表现均比浅层次的网络差,那显然就不是过拟合导致的)
如此图所示,从56层的表现反而比20层差。

那网络退化现象是什么造成的呢?
在MobileNet V2的论文中提到,由于非线性激活函数Relu的存在,每次输入到输出的过程都几乎是不可逆的,这也造成了许多不可逆的信息损失。我们试想一下,一个特征的一些有用的信息损失了,那他的表现还能做到持平吗?答案是显然的。
说通俗一点就是中间商赚差价。层数增多之后,信息在中间层损失掉了。
而ResNet正能解决网络退化问题。
ResNet要如何解决退化问题?
-
我们选择加深网络的层数,是希望深层的网络的表现能比浅层好,或者是希望它的表现至少和浅层网络持平(相当于直接复制浅层网络的特征)
-
如何持平看下图

-
我们把右边的网络理解为左边浅层网络加深了三层(框起来的部分)
假如我们希望右边的深层网络与左边的浅层网络持平,即是希望框起来的三层跟没加一样,也就是加的三层的输入等于输出。 -
我们假设这三层的输入为 x x x,输出为 H ( x ) H(x) H(x),那么深层网络与浅层网络表现持平的直观理解即是: H ( x ) = x H(x)=x H(x)=x,这种让输出等于输入的方式,就是论文中提到的恒等映射(identity mapping)。
-
所以ResNet的初衷,就是让网络拥有这种恒等映射的能力,能够在加深网络的时候,至少能保证深层网络的表现至少和浅层网络持平。
说通俗一点就是,我给孩子报了课外补习班(加的3层网络),我希望他的成绩要么就是提升,要么至少不要比没有上课外补习班的孩子成绩差。
ResNet是通过残差模块实现的,保留原本分支和学习过的分支中好的一个。
- 想要网络不退化,根本原因就是如何做到恒等映射。事实上,已有的神经网络很难拟合潜在的恒等映射函数 H ( x ) = x H(x)=x H(x)=x。但如果把网络设计为 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x,即直接把恒等映射作为网络的一部分,就可以把问题转化为学习一个残差函数 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x.只要 F ( x ) = 0 F(x)=0 F(x)=0,就构成了一个恒等映射 H ( x ) = x H(x)=x H(x)=x。
- 而且,拟合残差至少比拟合恒等映射容易得多。原因在第四部分讲解。
二、残差模块
我们看一下残差结构与正常结构对比图。
普通的神经网络如图所示:
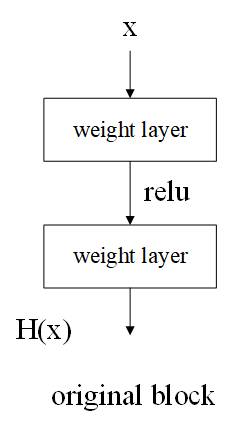
残差模块的结构图如图所示:

- 残差模块比普通模块多右边的曲线,这条曲线叫做:shortcut connection,skip connection,或identity
- H ( x ) = F ( x , W i ) + x H(x)=F(x,Wi)+x H(x)=F(x,Wi)+x,相加是逐元素相加
- 我们的模型想要学习的是 F ( x , W i ) F(x,Wi) F(x,Wi)这个残差,而不是普通模块的 H ( x ) H(x) H(x).公式则可以变换为: F ( x , W i ) = H ( x ) − x F(x,Wi)=H(x)-x F(x,Wi)=H(x)−x.
三、残差模块的优点
- 用恒等映射和残差相加,并不会增加模型的参数量,没有引入额外的参数,也为增加计算复杂度;
- 对比左图普通模块与右图残差网络,增加残差模块后模型的收敛速度加快(即误差下降的梯度更大);

- 可以解决退化问题,因为这样计算至少不会比没有加深网络差;
- 加了残差模块,网络就可以实现很深了;
- 准确率也有了很大的提升
四、残差模块发挥了作用的原因
- 加了残差结构后,给了输入 x x x一个多的选择。若神经网络学习到这层的参数是冗余的时候,它可以选择直接走这条“跳接”曲线(shortcut connection),跳过这个冗余层,而不需要再去拟合参数使得输出 H ( x ) H(x) H(x)等于 x x x。
- 学习残差的计算量比学习输出等于输入小。假设普通网络为A,残差网络为B,输入为2,输出为2(输入和输出一样是为了模拟冗余层需要恒等映射的情况),那么普通网络就是 A ( 2 ) = 2 A(2)=2 A(2)=2,而残差网络就是 B ( 2 ) = F ( 2 ) + 2 = 2 B(2)=F(2)+2=2 B(2)=F(2)+2=2,显然残差网络中的 F ( 2 ) = 0 F(2)=0 F(2)=0。我们知道网络中权重一般会初始化成0附近的数,那么我们就很容易理解,为什么让 F ( 2 ) F(2) F(2)(经过权重矩阵)拟合0会比 A ( 2 ) = 2 A(2)=2 A(2)=2容易了。
- ReLU能够将负数激活为0,而正数输入等于输出。这相当于过滤了负数的线性变化,让 F ( 2 ) = 0 F(2)=0 F(2)=0变得更加容易。
- 我们知道残差网络可以表示成 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x,这就说明了在求输出 H ( x ) H(x) H(x)对输入 x x x的倒数(梯度),也就是在反向传播的时候, H ( x ) ′ = F ( x ) ′ + 1 H(x)'=F(x)'+1 H(x)′=F(x)′+1,残差结构的这个常数1也能保证在求梯度的时候梯度不会消失。
五、ResNet网络结构
如下图展示的是ResNet34的网络结构。



- 从图中可看出,我们使用步长stride为2的卷积代替池化层进行下采样;
- 从图中可看出,实线部分的残差模块
x
x
x和
F
(
x
)
F(x)
F(x)的
c
h
a
n
n
e
l
channel
channel相同,可以直接相加(但是是在对
x
x
x进行降采样后再相加,因为降采样后两者的长宽深才完全一致)。但虚线部分的
F
(
x
)
F(x)
F(x)的channel加倍,因此无法相加。比如说,
x
x
x是31×31×128,
F
(
x
)
F(x)
F(x)是12×12×256,它们的维度不相同,无法直接对应位置元素相加,有2种处理方法:
1. 对 x x x少的 c h a n n e l channel channel直接补零,然后降采样,再与 F ( x ) F(x) F(x)直接逐元素相加。这个过程没有产生额外的参数。
2. 用1×1卷积 对 x x x进行升维处理后,然后降采样,再与 F ( x ) F(x) F(x)逐元素相加。这个过程产生了额外的参数(因为1×1卷积的卷积核参数)
方法2比方法1效果更好,因为方法1在升维时,用补零的方式,相当于丢失了shortcut分支的信息,没有进行残差学习。
六、论文解读
ResNet论文pdf地址:https://arxiv.org/pdf/1512.03385.pdf

- 非常深的网络很难训练,会出现网络退化现象,ResNet残差网络可以解决非常深网络的退化问题和训练问题的,在实验中也可以证明残差网络是能很好的优化,并在加深网络的同时,提高网络准确率。相较于VGG,我们提出了一个152层的ResNet,是VGG深度的8倍,但拥有更低的复杂度,准确率更高。在各类大赛中,使用ResNet网络获得了第一名的好成绩。


- 深的网络可以集成浅层、中层、深层的特征,对于视觉识别等任务是十分重要的。但是一味粗暴地去加深网络层数,会出现很多问题。
- 首先是臭名昭著的梯度消失、题都爆炸问题,阻碍了收敛。但这个问题已经可以通过适当的权重初始化和Batch Normolization(BN)进行解决。

- 收敛问题解决了之后,网络退化问题又暴露出来了:随着网络深度增加,准确率趋于饱和,继续加深,准确率开始下降。这不是过拟合造成的(过拟合问题是在训练集上表现好,在测试集上表现差)。
- 网络退化问题也揭示了,不是任何网络都能够简单的去用同样的方法优化,比如增加深度。因此提出让浅层模型的输出和更深的对应版本相加。added layer叫identity mapping,也就是 x x x;另一个是从浅层学习到的模型,也就是 F ( x ) F(x) F(x)。这样的思路就可以解决,让加深后的模型至少不会比浅层模型差。


- 模型不去拟合底层映射(underlying mapping) H ( x ) H(x) H(x),而是去拟合相对输入的残差(residual mapping) F ( x ) F(x) F(x)。 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x。如果identity mapping(也就是 x x x)已经足够优秀了,那 F ( x ) = 0 F(x)=0 F(x)=0就可以了,而不是用非线性层去拟合 H ( x ) = x H(x)=x H(x)=x。

- 残差模块结构如下图所示,仅仅是将
x
x
x于
F
(
x
)
F(x)
F(x)相加,加号这样一个运算是没有增加计算复杂度的。


- 在ImageNet数据集上做实验时,ResNet有如下优势:
- 非常深的网络也易于优化收敛(而仅仅堆叠深度的plain net 训练error会增加)
- 解决退化问题,在深度增加时,acc大大提升。


-
反正在各类的比赛中都获得很好地成绩(第一名),所以这个残差网络的普适性是很好的,可以应用与各类视觉问题或非视觉问题中。




-
残差
-
shortcut connection:就像门控函数一样,门关了就不学习新的,门开了就学习一些新的有用的。


- 将原本的式子变为 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x,从网络退化现象可知,original network直接去拟合恒等映射是很难的。使用残差网络,残差加上恒等映射后,深层网络至少不会比浅层更差。如果恒等映射已经最优,残差模块只要去拟合零映射即可。



- 每几层卷积形成一个残差,定义为 y = F ( x , W i ) + x y=F(x , { Wi } )+x y=F(x,Wi)+x. F ( x , W i ) F(x,{Wi}) F(x,Wi)表示深层学习过的结果。
- 在图2中,中间有两层,首先经过第一层,再使用激活函数(ReLu函数),再经过第二层,再与
x
x
x逐元素相加后,最后经过激活函数(ReLu函数)输出。

- 加入残差后,没有增加额外的参数,也没有增加复杂度。

- F ( x ) F(x) F(x)与 x x x需要维度相同才可以直接相加。如果不相同,需要对x进行一次线性变换。于是公式就变成了 y = F ( x , W i ) + W s ⋅ x y=F(x,Wi)+Ws·x y=F(x,Wi)+Ws⋅x.

- 但是为了使整个网络更经济,因此 W s Ws Ws仅仅在维度不相同时才这样处理,否则产生的参数就太多了。
- 这个残差结构可以有两层,或者三层,以及任意层,但不要只有1层,否则就没有展现出明显的优势。而且不一定是卷积层,也可以是全连接层。


- 对比了Plain Network(也就是普通网络)和残差网络。
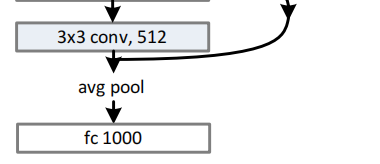
- Plain Network: 类似于VGG网络。卷积层的卷积核一般都是3×3,并且每个block内filter个数不变,当进入下一个block时,featur map大小减半,filter个数增倍。使用步长为2的卷积进行下采样,而不是pooling。最后接一个GAP层以取代全连接层,这样可以减少参数量和计算量。GAP层是把每个channel求平均值,有多少channel就有多少个值。然后使用softmax激活函数的全连接层去分类1000类。如图3所示最中间的图。可以发现我们的模型比VGG有更少的filter。



- Residual Network: 在plain network的基础上,我们插入了shortcut connection。如图3最右边所示。当通道数相同时,可以直接相加。如果通道数加倍了,有两个选择:1.在identity mapping增加的通道上补零。2.使用1×1的卷积去处理identity mapping。不管采取哪种匹配维度的方案,shortcut分支第一个卷积层步长都为2.


- 从图4和表2可以看出,残差网络收敛的更快,且解决了网络退化问题。


- 由于我们使用了BN层,可以保证不会梯度消失,且前向/反向传播都很良好。所以可以确定优化的困难不是梯度消失导致的。我们推测是模型的本身的上限就已经不是很高。



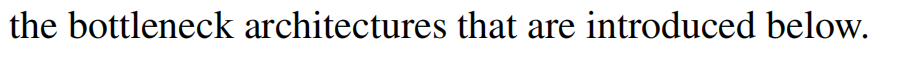
- A.维度提升时,用0填充不足的维度。没有产生新的参数。
- B.维度提升时,用projection shortcut 1×1卷积去提升维度;维度没有提升时,还是identity。
- C.所有的shortcut都是projection shortcut 1×1卷积。
- 从表3结果可看出,C>B>A.但是C成本太高,会增加计算复杂度和模型大小。


- Deeper Bottleneck Architectures: 更深的网络时,担心训练时间,修改了building block 为 bottleneck design。先用1×1的卷积降维,然后3×3卷积,最后用1×1卷积升维,像个沙漏一样。在这个结构中,无参数的identity shortcut尤其重要。如果引入了projection,那么时间复杂度、计算量、模型尺度、参数量都会加倍。



但网络也不能一味地去加深。如下图所示,当加深到ResNet-1202是,错误率增加了。推测是由于过拟合造成的。需要增加数据量去训练。

此篇文章借鉴了很多前辈的博客,我贴出一些我觉得还不错的。
https://zhuanlan.zhihu.com/p/106764370
推荐B站同济子豪兄讲解ResNet的视频。

