
- 1CVSS4.0将于2023年底正式发布_cvss4.0 3.1
- 2数据结构(4.1)——树的性质
- 3OpenssH 漏洞修复_openssh漏洞
- 4深度学习论文导航 | 11 LaneNet:基于实例分割方法的车道线检测网络_基于实例分割的车道线检测算法
- 5c++编码规范(五)_禁止使用rand生成伪随机数
- 6GitHub十大Python项目推荐,Star最高26_github 排行 python
- 7vs code配置MySQL,实现连接、查询等功能
- 8Element UI 消息提示 Message_element-ui message
- 9每天一个数据分析题(四百二十九)- 假设检验
- 10小程序消息推送(含源码)java实现小程序推送,springboot实现微信消息推送_微信小程序发送消息通知 java代码
最新酷狗音乐反爬来袭,Python掌握酷狗排行榜加密规则(1)_酷狗反爬
赞
踩
歌曲的数据都是来自网页源代码
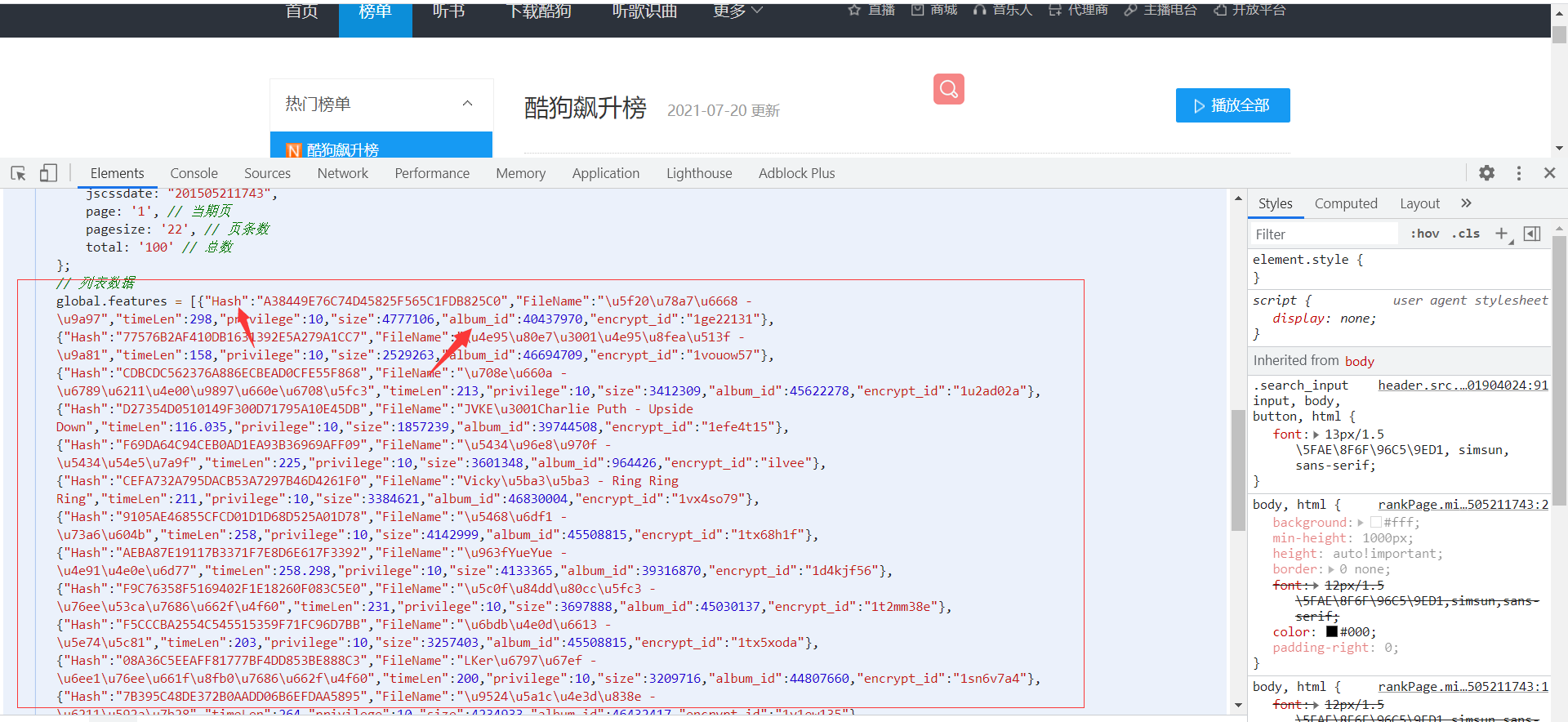
梳理整体思路:
-
从首页源码里提取出对应的hash、album_id值
-
组合成新的url地址
-
获取到json数据总的歌曲播放地址##
简易源码分析
本章内容只限学习,切勿用作其他用途!!!!!
import requests
import re
import time
def Tools(url):
headers = {
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70’
}
response = requests.get(url, headers=headers)
return response
def Save(name, url):
mp3 = Tools(url).content # 请求mp3地址链接 返回格式是16进制
f = open(‘./kugou/{}.mp3’.format(name), ‘wb’) # w 文件存在就写入 不存在就会创建 b进制读写
f.write(mp3)
f.close()
print(‘{}下载完成…’.format(name))
url = ‘https://www.kugou.com/yy/html/rank.html’
response = Tools(url).text
album_id = re.findall(r’“album_id” 本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

