
- 1JAVA实现二分查找,斐波那契数列,深度优先搜索详情教程【包含代码】
- 2代码随想录刷题Day59 | 503. 下一个更大元素 II | 42. 接雨水_go实现给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是
- 3【LeetCode每日一题】2381. 字母移位 II&&2406. 将区间分为最少组数 (差分数组)_leetcode 字母位移
- 4深度学习原理与实战:深度学习在医疗领域的应用_机器学习或者深度学习在医学方面的运用csdn
- 5Python制作自动化脚本通用版教程_python编写自动化挂机脚本
- 6Week8-C++基础3(构造函数、静态成员函数和变量、运算符重载学习)_w8wja8c++yuk51k
- 7Javaweb之javascript事件案例的详细解析_点击 “点亮”按钮 点亮灯泡,点击“熄灭”按钮熄灭灯泡; (2)输入框鼠标聚焦后,展
- 8Linux命令——ss_linux中ss命令
- 9使用 vllm 本地部署 Qwen2-7B-Instruct
- 10什么是自动化测试框架?我们该如何搭建自动化测试框架?_自动化测试框架搭建思路
大模型--意图对齐--Instruction Tuning_instruction input output
赞
踩
Introduction
目的
让模型学会输出符合 instruction 的回答。
方法
构建形式为 instruction + content + answer 的样本集,然后有监督的方式训练 LLM。
构建样本集的方法
主要是用一些 prompt template 来让 GPT-3/GPT-3.5/GPT-4 自动输出一些符合要求的高质量的样本。
也可以使用已有的公开的数据集,将他们转化成 instruction + content + answer 的形式。
相关研究
Self-instruct
Introduction
GPT-3 文本生成能力很强,不总是能生成符合 instruction 的输出,但是某些情况下可以。
给GPT-3输入有效的 prompt,从而引导它生成符合 instruction 的文本,构建样本集。
然后再用监督训练的方式让GPT-3学会遵守instruction。
用有效的 prompt 来激发GPT-3本身的能力,再通过训练来强化。
sample formate
instruction + input + output
instruction
任务的描述
一个 instruction 可以对应多个(input, output)
input
如果 instruction 是一个通用的任务,则 input 会是一个具体的任务输入。
例如:
Instruction: Given an address and city, come up with the zip code.
Input: Address: 123 Main Street, City: San Francisco
Output: 94105
- 1
- 2
- 3
不一定每个 sample 都有,例如
Instruction: Write a letter from the perspective of a cat.
Input: Null
Output:
Dear [Owner], I am writing to you today because I
have a problem. You see, I’ve been living with you
for the past [Number of Years] and I love it here.
The food is great, the bed is comfy, and there are
plenty of toys to play with. But lately, I’ve
noticed that you’re not as affectionate towards
me as you used to be. In fact, sometimes
when I try to cuddle up next to you on the
couch, you push me away ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
output
期待模型输出的东西
dataset generation
从人工写的 seed 开始,逐渐循环迭代生成,下图为生成的流程
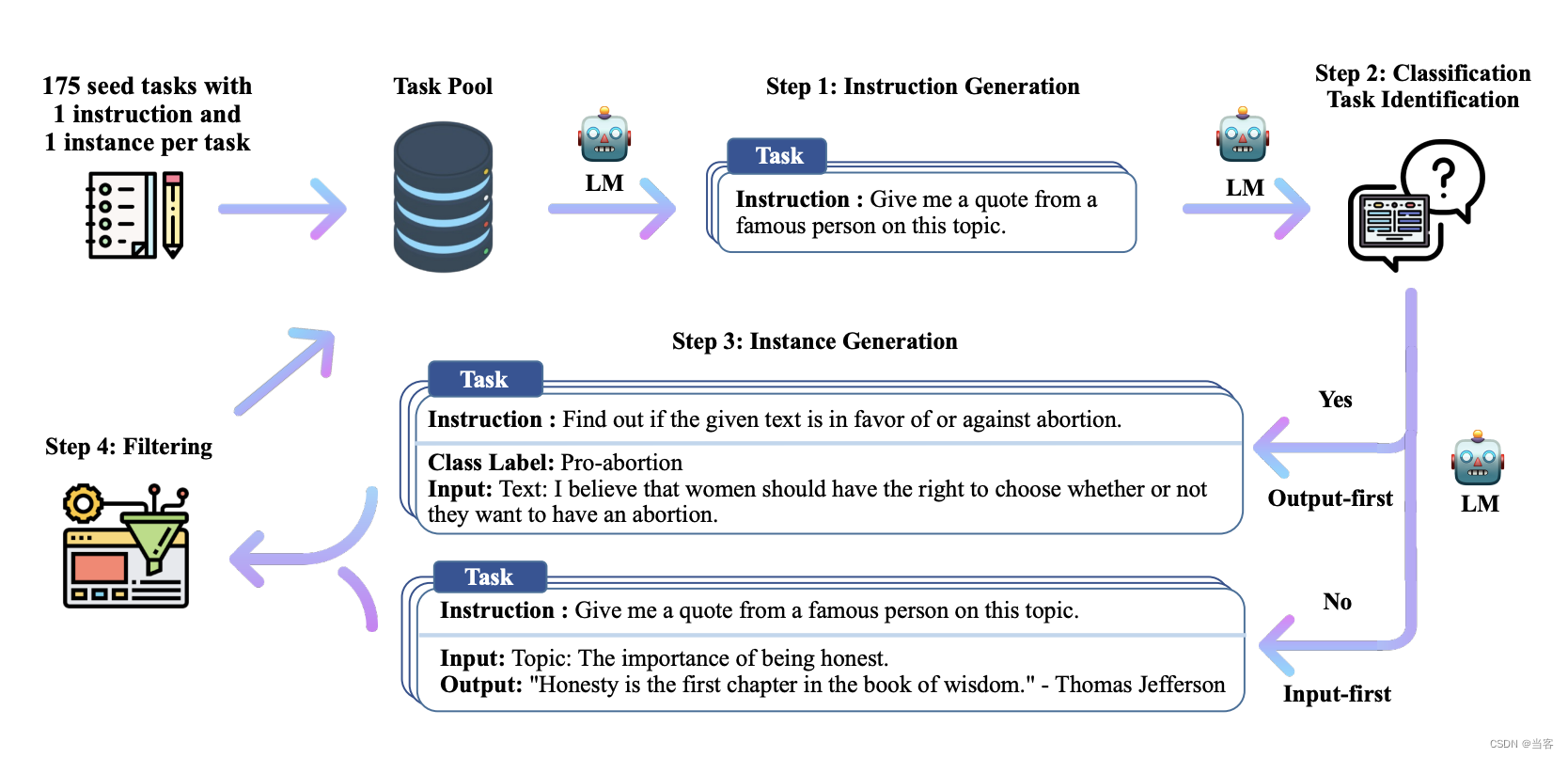
从seed 开始
作者和同事从头手写了 175 task
每个 task 有一个seed
seed 是手工写的 instruction+input+output 的样本
generate instructions
leverages the existing collection of instructions to create more broad-coverage instructions
每次 sample 8 个已有的 instruction(6 个手写的,2 个自动生成的)
把 8 个 instruction 输出模型,让模型仿照这 8 个 instruction,生成新的 instruction,一次生成一个 instruction
下图为一个例子

Classification Task Identification
作者把任务分成了 2 种类型:分类和非分类。两种任务需要用不同方式处理,所以需要区分两种任务。
using 12 classification instructions and 19 non-classification instructions from the seed tasks 用来生成 prompt
下图为一个例子的 prompt

Instance Generation
creates input-output instances for newly generated set of instructions
这里分了 2 种类型的 prompt: input first 和 output first。
因为在作者的实验中,对分类任务,如果用 input-first 的 prompt 的话,生成的样本总是会偏向于某一些类别,一些类别特别多,一些特别少。于是对分类任务使用 output-first 的 prompt,先生成类别标签(output),再生成 input,对非分类任务使用 input-first。
下图为 input first 的例子:

下图为 output first 的例子:

Filtering and Postprocessing
过滤掉一些质量不好的。以下为一些过滤方法:
- 过滤 instruction
只增加和已有的 instruction 相似度低于 0.7 的样本,目的是增加多样性,使用的是ROUGE-L similarity
用关键词过滤一些 instruction,例如 image, picture, graph,目的是去掉 LM 无法处理的样本 - 过滤 instance
去掉相同的
去掉 input 相同,output 却不同的 - 过滤 invalid
用一些启发式的方法去掉 invalid 的样本,e.g., instruction is too long or too short, instance output is a repetition of the input
fine-tuning
用生成的 large-scale instruction data 做监督训练。
会用一些规则来处理样本从而让模型更 robust。
For example, the instruction can be prefixed with “Task:” or not, the input can be prefixed with “Input:” or not, “Output:” can be appended at the end of the prompt or not, and different numbers of break lines can be put in the middle, etc.
Dataset
最终得到了52k instructions,一共82K instance inputs and target outputs
Alpaca
用 self-instruct 的方法生成了一个新的数据集,然后用生成的数据集微调 LLama
生成方法相比 self-instruct 的变化
- 使用了 text-davinci-003 instead of davinci
用来生成样本的模型更强了 - wrote a new prompt
只是一个新的生成 instruction 的 prompt - 批量生成
例如一次生成20 个instruction,原方法一次只生成过一个 - 不再区分分类和非分类任务
- 一个 instruction 只生成一个 instance
Instruction Tuning with GPT-4
做了 3 件事
1. 用 GPT-4 构建了 instruction tuning 数据集
数据集分 4 个部分:
- English Instruction-Following Data
把 Alpaca 的英文 instruction 用 GPT-4重新生成答案 - Chinese Instruction-Following Data
Alpaca的 instruction 翻译成中文,再用 GPT-4重新生成答案 - Comparison Data
让 GPT-4 给 3 个模型生成的回复打分(GPT-4, GPT-3.5 and OPT-IML ),用来训练 reward model - Answers on Unnatural Instructions
The GPT-4 answers are decoded on the core dataset of 68K instruction-input-output triplets (Honovich et al., 2022).
The subset is used to quantify the gap between GPT-4 and our instruction-tuned models at scale.
没看懂,如何用这个数据来量化两个模型的差距?
2. instruction tuning on LLaMA 7B
分别训练了中文和英文两个模型
3. 训练了 REWARD MODEL
based on OPT 1.3B
训练样本构建
一个 prompt 有K 个 response,GPT-4给了每个(prompt,response)对一个得分(1到 10 分)
用 pair wise 的方法来训练,每个 pair 包括 2 个(prompt,response)对,一个得分高,一个得分低
一个 pair 的优化目标为最小化 log ( σ ( r θ ( x , y h ) − r θ ( x , y l ) ) ) \log(\sigma(r_{\theta}(x, y_h) - r_{\theta}(x, y_l))) log(σ(rθ(x,yh)−rθ(x,yl)))
效果评估
- 人工打分
在亚马逊的众包平台,对比两个模型的 helpful, honest, and harmless (HHH) - 用 GPT-4 来给 prompt-response 打分
个人认为作者的这个评分方法有问题,这里得分高只能证明对 GPT-4 的拟合程度高,并不能证明更好。
Wizardlm
通过一些方法,自动迭代 instruction,使得 instruction 变得越来越复杂,方法名字叫做 Evol-Instruct。
还是用 GPT-4 生成 instruction,生成数据集后在 llama 上微调
相比Alpaca和Instruction Tuning with GPT-4只是照搬 self-instruct,Wizardlm提出的 Evol-Instruct 是在 self-instruct 上有新的内容的。

