
- 1深入解读 ChatGPT 的基本原理(个人总结版)_chatgpt详解
- 2Python学习记录-ZOJ刷题篇 01_zoj python a+b
- 3thinkphp 5.0 用户注册登录_thinkphp 5.0 注册登录
- 4计算机电子书 2018 BiliDrive 备份_29e8d44b-c82a-4069-b3e0-015a5eb34087
- 5《数据结构》线性表之单链表(C语言)
- 6Window10:不能建立到远程计算机的连接。你可能需要更改此连接的网络设置。_不能建立到远程计算机的连接你可能需要更改
- 7自己总结的ICT云计算题库_华为ict云赛道题库
- 8SqlServer——系统函数
- 9【NumPy】全面解析NumPy的where函数:高效条件操作指南_numpy where
- 10YOLOv8改进 添加倒置残差注意力机制iRMB_倒残差自注意力
CentOS7下搭建Hadoop(3.3.4)集群_conf.configuration: resource-types.xml not found
赞
踩
7.0 MapReduce 编程 | 菜鸟教程
1. 前期准备
1)规划
| 主机 | IP | 角色 |
| 172.16.10.67 | 172.16.10.67 | NameNode、SecondaryNameNode、ResourceManager、DataNode、NodeManager |
| 172.16.10.68 | 172.16.10.68 | DataNode、NodeManager |
| 172.16.10.68 | 172.16.10.69 | DataNode、NodeManager |
2、环境搭建
一、配置host(三台机器) 我没配置,如果配置
- # 设置主机名
- hostnamectl set-hostname node01
-
- # hosts映射
- cat /etc/hosts
-
- 172.16.10.67 node01
- 172.16.10.68 node02
- 172.16.10.69 node03
二、关闭防火墙(三台机器)
- # 查看防火墙状态
- firewall-cmd --state
- # 停止firewalld服务
- systemctl stop firewalld.service
- # 开机禁用firewalld服务
- systemctl disable firewalld.service
三、ssh免密登录
注:只需要配置node1至node1、node2、node3即可
- #node1生成公钥私钥 (一路回车)
- ssh-keygen
-
- #node1配置免密登录到node1 node2 node3
- ssh-copy-id node1
- ssh-copy-id node2
- ssh-copy-id node3
四、集群时间同步(三台机器)
- yum install ntpdate
- # 网络时间同步
- ntpdate ntp5.aliyun.com
五、创建统一工作目录(三台机器)
mkdir -p /root/hadoop/server六、安装Hadoop,所有节点
- [root@172 server]# wget --no-check-certificate -c https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
-
-
- JAVA_HOME=/usr/java/jdk
- PATH=$GRADLE_HOME/bin:$JAVA_HOME/bin:$NODE_HOME/bin:$NODE_HOME1/bin:$PATH
- CLASSPATH=.:$JAVA_HOME/jre/lib/ext:$JAVA_HOME/jre/lib/ext/jar:$JAVA_HOME/lib/tools.jar
- export PATH JAVA_HOME CLASSPATH
-
- export HADOOP_HOME=/root/hadoop/server/hadoop
- export HADOOP_INSTALL=$HADOOP_HOME
- export HADOOP_MAPRED_HOME=$HADOOP_HOME
- export HADOOP_HDFS_HOME=$HADOOP_HOME
- export HADOOP_COMMON_HOME=$HADOOP_HOME
- export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
-
- # 配置文件生效
- source /etc/profile
-
- # 检查是否成功
- [root@172 server]# hadoop version
- Hadoop 3.3.4
- Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb
- Compiled by stevel on 2022-07-29T12:32Z
- Compiled with protoc 3.7.1
- From source with checksum fb9dd8918a7b8a5b430d61af858f6ec
- This command was run using /root/hadoop/server/hadoop/share/hadoop/common/hadoop-common-3.3.4.jar

七、修改配置文件
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 | 作用 |
|---|---|---|
| [core-site.xml] | hadoop-common-2.7.2.jar/ core-default.xml | hdaoop核心模块配置文件 |
| [hdfs-site.xml] | hadoop-hdfs-2.7.2.jar/ hdfs-default.xml | hdfs文件系统模块配置 |
| [yarn-site.xml] | hadoop-yarn-common-2.7.2.jar/ yarn-default.xml | yarn模块配置 |
| [mapred-site.xml] | hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml | MapReduce模块配置 |
core-site.xml:
- [root@172 hadoop]# cat core-site.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!--
- Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License. See accompanying LICENSE file.
- -->
-
- <!-- Put site-specific property overrides in this file. -->
-
- <configuration>
- <!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://172.16.10.67:8020</value>
- </property>
-
- <!-- 设置Hadoop本地保存数据路径 -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/root/hadoop/server/hadoop</value>
- </property>
-
- <!-- 设置HDFS web UI用户身份 -->
- <property>
- <name>hadoop.http.staticuser.user</name>
- <value>root</value>
- </property>
-
- <!-- 整合hive 用户代理设置 -->
- <property>
- <name>hadoop.proxyuser.root.hosts</name>
- <value>*</value>
- </property>
-
- <property>
- <name>hadoop.proxyuser.root.groups</name>
- <value>*</value>
- </property>
-
- <!-- 文件系统垃圾桶保存时间 -->
- <property>
- <name>fs.trash.interval</name>
- <value>1440</value>
- </property>
- </configuration>
hdfs-site.xml
- [root@172 hadoop]# cat hdfs-site.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!--
- Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License. See accompanying LICENSE file.
- -->
-
- <!-- Put site-specific property overrides in this file. -->
-
- <configuration>
-
- <!-- 设置SNN进程运行机器位置信息 -->
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>172.16.10.67:9868</value>
- </property>
- </configuration>
yarn-site.xml
- [root@172 hadoop]# cat yarn-site.xml
- <?xml version="1.0"?>
- <!--
- Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License. See accompanying LICENSE file.
- -->
- <configuration>
-
- <!-- Site specific YARN configuration properties -->
-
- <!-- 设置YARN集群主角色运行机器位置 -->
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>172.16.10.67</value>
- </property>
-
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
-
- <!-- 是否将对容器实施物理内存限制 -->
- <property>
- <name>yarn.nodemanager.pmem-check-enabled</name>
- <value>false</value>
- </property>
-
- <!-- 是否将对容器实施虚拟内存限制。 -->
- <property>
- <name>yarn.nodemanager.vmem-check-enabled</name>
- <value>false</value>
- </property>
-
- <!-- 开启日志聚集 -->
- <property>
- <name>yarn.log-aggregation-enable</name>
- <value>true</value>
- </property>
-
- <!-- 设置yarn历史服务器地址 -->
- <property>
- <name>yarn.log.server.url</name>
- <value>http://172.16.10.67:19888/jobhistory/logs</value>
- </property>
-
- <!-- 历史日志保存的时间 7天 -->
- <property>
- <name>yarn.log-aggregation.retain-seconds</name>
- <value>604800</value>
- </property>
-
- <!--每个磁盘的磁盘利用率百分比-->
- <property>
- <name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
- <value>95.0</value>
- </property>
- <!--集群内存-->
- <property>
- <name>yarn.nodemanager.resource.memory-mb</name>
- <value>2048</value>
- </property>
- <!--调度程序最小值-分配-->
- <property>
- <name>yarn.scheduler.minimum-allocation-mb</name>
- <value>2048</value>
- </property>
- <!--比率,具体是啥比率还没查...-->
- <property>
- <name>yarn.nodemanager.vmem-pmem-ratio</name>
- <value>2.1</value>
- </property>
- </configuration>
mapred-site.xml
- [root@172 hadoop]# cat mapred-site.xml
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!--
- Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License. See accompanying LICENSE file.
- -->
-
- <!-- Put site-specific property overrides in this file. -->
-
- <configuration>
-
- <!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
-
- <!-- MR程序历史服务地址 -->
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>172.16.10.67:10020</value>
- </property>
-
- <!-- MR程序历史服务器web端地址 -->
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>172.16.10.67:19888</value>
- </property>
-
- <property>
- <name>yarn.app.mapreduce.am.env</name>
- <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
- </property>
-
- <property>
- <name>mapreduce.map.env</name>
- <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
- </property>
-
- <property>
- <name>mapreduce.reduce.env</name>
- <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
- </property>
- <property>
- <name>mapreduce.application.classpath</name>
- <value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib-examples/*</value>
- </property>
- </configuration>
workers:
- [root@172 hadoop]# cat workers
- 172.16.10.67
- 172.16.10.68
- 172.16.10.69
八、启动集群
1. <!-- 如果报错Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster需要添加以下配置-->
解决:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
2.INFO conf.Configuration: resource-types.xml not found
INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
解决:<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
注:如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
(1)如果第一次启动集群需格式化NameNode 三个节点都操作
[root@172 hadoop]# hdfs namenode -format(2)启动Namenode
- [root@172 hadoop]# start-all.sh 启动所有
- [root@172 hadoop]# jcmd | grep hadoo
- 23942 org.apache.hadoop.hdfs.server.namenode.NameNode
- 24726 org.apache.hadoop.yarn.server.nodemanager.NodeManager
- 24087 org.apache.hadoop.hdfs.server.datanode.DataNode
- 24587 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
- 24335 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
- [root@172 hadoop]# jps
- 23942 NameNode
- 24726 NodeManager
- 24087 DataNode
- 24587 ResourceManager
- 17643 Jps
- 24335 SecondaryNameNode
-
-
-
- 指定启动Namenode;注:一个集群只有一个Namenode
- [root@172 hadoop]# hdfs --daemon start namenode
-
-
- 其他节点执行:
- 启动Datanode和secondarynamenode
- [root@173 hadoop]# hdfs --daemon start datanode
- [root@173 hadoop]# hdfs --daemon start secondarynamenode
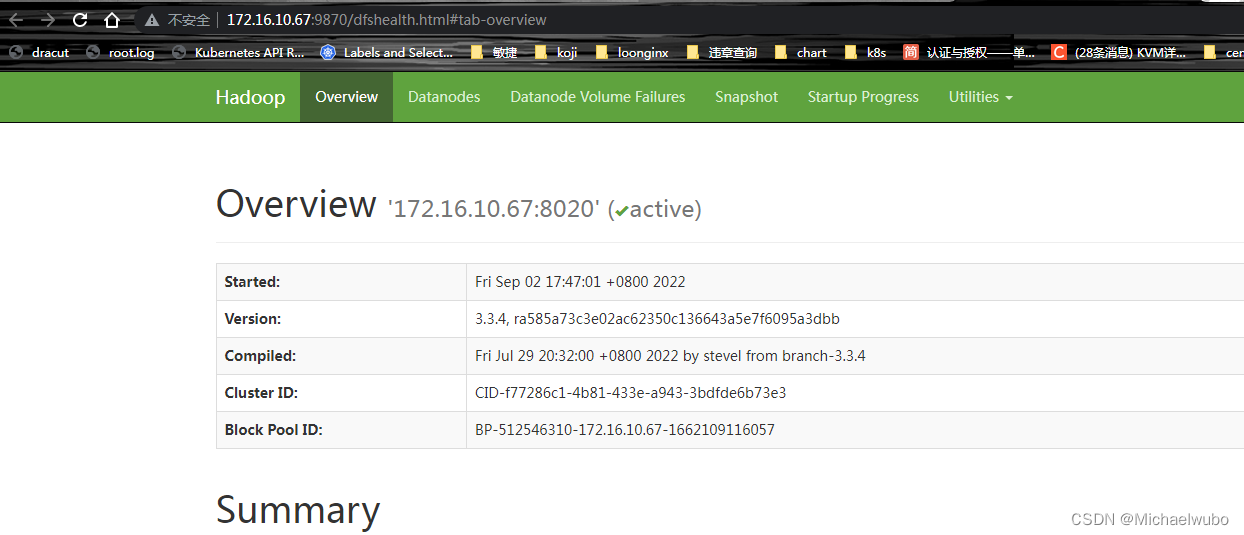
HDFS集群: http://172.16.10.67:9870/
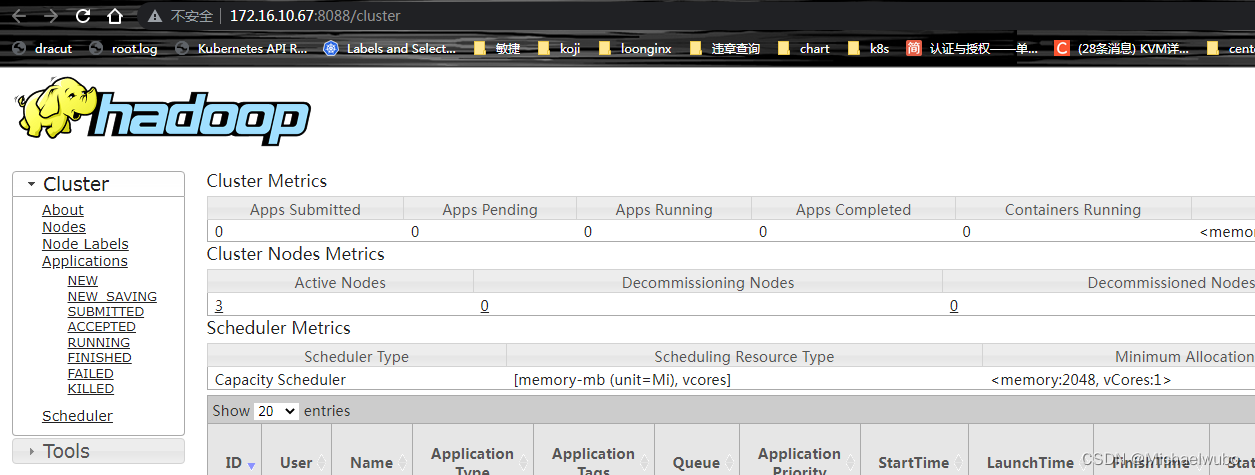
YARN集群:http://172.16.10.67:8088/
九:文件传输测试
HDFS界面:http://172.16.10.67:9870/
查看NameNode状态;
该端口的定义位于core-site.xml中,可以在hdfs-site.xml 中修改;
如果通过该端口看着这个页面,NameNode节点是存活的
⒈ 上传文件到集群
构建一个测试文本和HDFS存储目录
- 创建目录:
- [root@172 hadoop]# hadoop fs -mkdir /jettech
-
- [root@172 work]# cat input.txt
- I love runoob
- I like runoob
- I love hadoop
- I like hadoop
-
- 上传:
- [root@172 hadoop]# hadoop fs -put input.txt /jettech
-
- 查看:
- [root@172 work]# hadoop fs -ls /jettech
- Found 5 items
- -rw-r--r-- 3 root supergroup 15217 2022-09-02 16:59 /jettech/LICENSE.txt
- -rw-r--r-- 3 root supergroup 56 2022-09-02 17:00 /jettech/input.txt
- drwxr-xr-x - root supergroup 0 2022-09-02 17:05 /jettech/output
- drwxr-xr-x - root supergroup 0 2022-09-02 17:07 /jettech/output1
- drwxr-xr-x - root supergroup 0 2022-09-02 17:21 /jettech/output2
- [root@172 work]# hadoop fs -cat /jettech/input.txt
- I love runoob
- I like runoob
- I love hadoop
- I like hadoop
如果不想要可以用rm删除,hdfs dfs命令之后附加的命令和Linux下常用命令基本相同。
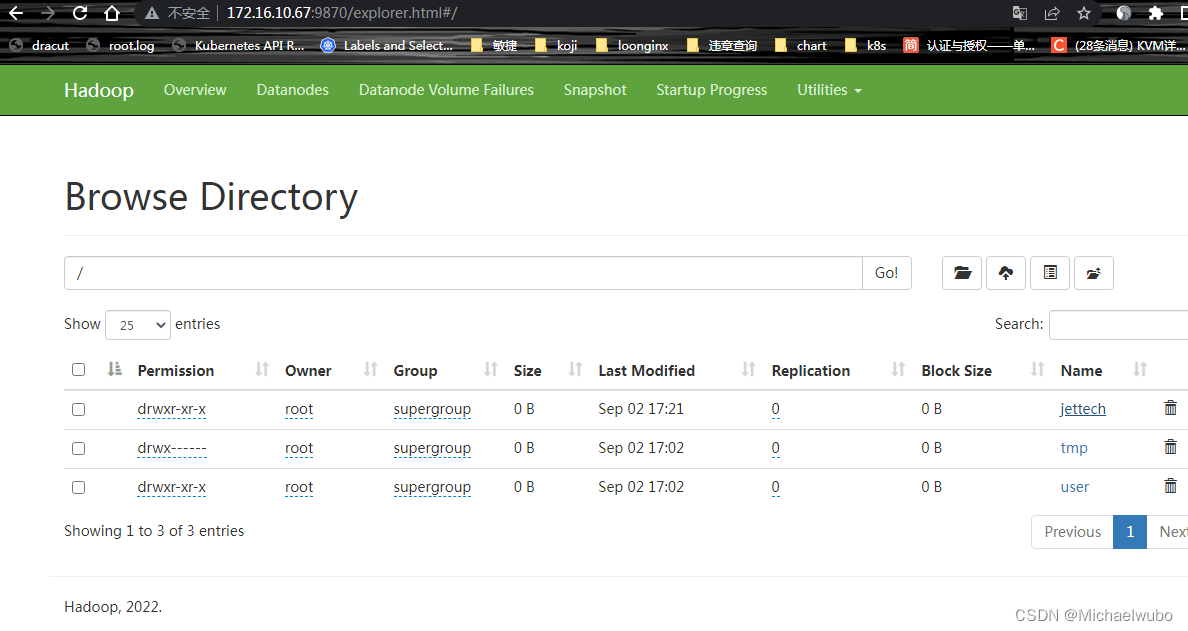
Size为当前大小,Block Size为一个存储块最大的存储容量为128M。
可从网站上进行下载,如果上传的文件容量大于规定的128M,将会把此文件分成两个块进行存储。同时,也可找到该文件存储目录下对应的blk_id,自行按顺序进行拼接后,可还原成原始文件。

- [root@172 work]# ls /root/hadoop/server/hadoop/dfs/data/current/BP-512546310-172.16.10.67-1662109116057/current/finalized/subdir0/subdir0/
- blk_1073741825 blk_1073741839_1015.meta blk_1073741851 blk_1073741862_1038.meta blk_1073741874 blk_1073741885_1061.meta
- blk_1073741825_1001.meta blk_1073741840 blk_1073741851_1027.meta blk_1073741863 blk_1073741874_1050.meta blk_1073741886
- blk_1073741826 blk_1073741840_1016.meta blk_1073741852 blk_1073741863_1039.meta blk_1073741875 blk_1073741886_1062.meta
- blk_1073741826_1002.meta blk_1073741841 blk_1073741852_1028.meta blk_1073741870 blk_1073741875_1051.meta blk_1073741887
- blk_1073741836 blk_1073741841_1017.meta blk_1073741859 blk_1073741870_1046.meta blk_1073741882 blk_1073741887_1063.meta
- blk_1073741836_1012.meta blk_1073741848 blk_1073741859_1035.meta blk_1073741871 blk_1073741882_1058.meta blk_1073741888
- blk_1073741837 blk_1073741848_1024.meta blk_1073741860 blk_1073741871_1047.meta blk_1073741883 blk_1073741888_1064.meta
- blk_1073741837_1013.meta blk_1073741849 blk_1073741860_1036.meta blk_1073741872 blk_1073741883_1059.meta
- blk_1073741838 blk_1073741849_1025.meta blk_1073741861 blk_1073741872_1048.meta blk_1073741884
- blk_1073741838_1014.meta blk_1073741850 blk_1073741861_1037.meta blk_1073741873 blk_1073741884_1060.meta
- blk_1073741839 blk_1073741850_1026.meta blk_1073741862 blk_1073741873_1049.meta blk_1073741885
创建tmp.file用来存放文件内容,开始拼接
- # cat blk_1073741836>>tmp.file
- # cat blk_1073741837>>tmp.file
案例:集群模式下,需要先上传到集群中
统计案例
- [root@172 work]# yarn jar /root/hadoop/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /jettech/input.txt /jettech/output4
- 2022-09-05 11:27:12,265 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /172.16.10.67:8032
- 2022-09-05 11:27:12,846 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1662112035948_0001
- 2022-09-05 11:27:13,571 INFO input.FileInputFormat: Total input files to process : 1
- 2022-09-05 11:27:14,477 INFO mapreduce.JobSubmitter: number of splits:1
- 2022-09-05 11:27:14,635 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1662112035948_0001
- 2022-09-05 11:27:14,635 INFO mapreduce.JobSubmitter: Executing with tokens: []
- 2022-09-05 11:27:14,817 INFO conf.Configuration: resource-types.xml not found
- 2022-09-05 11:27:14,818 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
- 2022-09-05 11:27:15,265 INFO impl.YarnClientImpl: Submitted application application_1662112035948_0001
- 2022-09-05 11:27:15,305 INFO mapreduce.Job: The url to track the job: http://172.16.10.67:8088/proxy/application_1662112035948_0001/
- 2022-09-05 11:27:15,306 INFO mapreduce.Job: Running job: job_1662112035948_0001
- 2022-09-05 11:27:23,514 INFO mapreduce.Job: Job job_1662112035948_0001 running in uber mode : false
- 2022-09-05 11:27:23,517 INFO mapreduce.Job: map 0% reduce 0%
- 2022-09-05 11:27:28,659 INFO mapreduce.Job: map 100% reduce 0%
- 2022-09-05 11:27:32,710 INFO mapreduce.Job: map 100% reduce 100%
- 2022-09-05 11:27:33,737 INFO mapreduce.Job: Job job_1662112035948_0001 completed successfully
- 2022-09-05 11:27:33,875 INFO mapreduce.Job: Counters: 54
- File System Counters
- FILE: Number of bytes read=62
- FILE: Number of bytes written=553631
- FILE: Number of read operations=0
- FILE: Number of large read operations=0
- FILE: Number of write operations=0
- HDFS: Number of bytes read=163
- HDFS: Number of bytes written=36
- HDFS: Number of read operations=8
- HDFS: Number of large read operations=0
- HDFS: Number of write operations=2
- HDFS: Number of bytes read erasure-coded=0
- Job Counters
- Launched map tasks=1
- Launched reduce tasks=1
- Rack-local map tasks=1
- Total time spent by all maps in occupied slots (ms)=2599
- Total time spent by all reduces in occupied slots (ms)=2680
- Total time spent by all map tasks (ms)=2599
- Total time spent by all reduce tasks (ms)=2680
- Total vcore-milliseconds taken by all map tasks=2599
- Total vcore-milliseconds taken by all reduce tasks=2680
- Total megabyte-milliseconds taken by all map tasks=5322752
- Total megabyte-milliseconds taken by all reduce tasks=5488640
- Map-Reduce Framework
- Map input records=4
- Map output records=12
- Map output bytes=104
- Map output materialized bytes=62
- Input split bytes=107
- Combine input records=12
- Combine output records=5
- Reduce input groups=5
- Reduce shuffle bytes=62
- Reduce input records=5
- Reduce output records=5
- Spilled Records=10
- Shuffled Maps =1
- Failed Shuffles=0
- Merged Map outputs=1
- GC time elapsed (ms)=135
- CPU time spent (ms)=1340
- Physical memory (bytes) snapshot=576929792
- Virtual memory (bytes) snapshot=5615321088
- Total committed heap usage (bytes)=486014976
- Peak Map Physical memory (bytes)=345632768
- Peak Map Virtual memory (bytes)=2804011008
- Peak Reduce Physical memory (bytes)=231297024
- Peak Reduce Virtual memory (bytes)=2811310080
- Shuffle Errors
- BAD_ID=0
- CONNECTION=0
- IO_ERROR=0
- WRONG_LENGTH=0
- WRONG_MAP=0
- WRONG_REDUCE=0
- File Input Format Counters
- Bytes Read=56
- File Output Format Counters
- Bytes Written=36
查看执行结果
- [root@172 work]# hadoop fs -cat /jettech/output4/part-r-00000
- I 4
- hadoop 2
- like 2
- love 2
- runoob 2
在学习了 MapReduce 的使用之后,我们已经可以处理 Word Count 这类统计和检索任务,但是客观上 MapReduce 可以做的事情还有很多。
MapReduce 主要是依靠开发者通过编程来实现功能的,开发者可以通过实现 Map 和 Reduce 相关的方法来进行数据处理。
为了简单的展示这一过程,我们将手工编写一个 Word Count 程序。
注意:MapReduce 依赖 Hadoop 的库,但由于本教程使用的 Hadoop 运行环境是 Docker 容器,难以部署开发环境,所以真实的开发工作(包含调试)将需要一个运行 Hadoop 的计算机。在这里我们仅学习已完成程序的部署。
- root@172 work]# mkdir -p com/runoob/hadoop/
-
- root@172 work]# cat com/runoob/hadoop/
- Map.class MyWordCount.class MyWordCount.java Reduce.class
- [root@172 work]# cat com/runoob/hadoop/MyWordCount.java
- /**
- * 引用声明
- * 本程序引用自 http://hadoop.apache.org/docs/r1.0.4/cn/mapred_tutorial.html
- */
- package com.runoob.hadoop;
- import java.io.IOException;
- import java.util.*;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.*;
- import org.apache.hadoop.mapred.*;
- /**
- * 与 `Map` 相关的方法
- */
- class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- public void map(LongWritable key,
- Text value,
- OutputCollector<Text, IntWritable> output,
- Reporter reporter)
- throws IOException {
- String line = value.toString();
- StringTokenizer tokenizer = new StringTokenizer(line);
- while (tokenizer.hasMoreTokens()) {
- word.set(tokenizer.nextToken());
- output.collect(word, one);
- }
- }
- }
- /**
- * 与 `Reduce` 相关的方法
- */
- class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
- public void reduce(Text key,
- Iterator<IntWritable> values,
- OutputCollector<Text, IntWritable> output,
- Reporter reporter)
- throws IOException {
- int sum = 0;
- while (values.hasNext()) {
- sum += values.next().get();
- }
- output.collect(key, new IntWritable(sum));
- }
- }
- public class MyWordCount {
- public static void main(String[] args) throws Exception {
- JobConf conf = new JobConf(MyWordCount.class);
- conf.setJobName("my_word_count");
- conf.setOutputKeyClass(Text.class);
- conf.setOutputValueClass(IntWritable.class);
- conf.setMapperClass(Map.class);
- conf.setCombinerClass(Reduce.class);
- conf.setReducerClass(Reduce.class);
- conf.setInputFormat(TextInputFormat.class);
- conf.setOutputFormat(TextOutputFormat.class);
- // 第一个参数表示输入
- FileInputFormat.setInputPaths(conf, new Path(args[0]));
- // 第二个输入参数表示输出
- FileOutputFormat.setOutputPath(conf, new Path(args[1]));
- JobClient.runJob(conf);
- }
- }
编译:
[root@172 work]# javac -classpath /root/hadoop/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.4.jar -classpath /root/hadoop/server/hadoop/share/hadoop/client/hadoop-client-api-3.3.4.jar com/runoob/hadoop/MyWordCount.java打包:
[root@172 work]# jar -cf wubo-word-count.jar com执行:
[root@172 work]# hadoop jar wubo-word-count.jar com.runoob.hadoop.MyWordCount /jettech/input.txt /jettech/output5
