
热门标签
热门文章
- 1微信开发者工具和gitee实现多人协作_微信开发者工具多人开发
- 2AI编程助手太好用了:百度Baidu Comate,让代码飞舞在指尖_百度ai辅助前端开发工具 结合 用起来最顺手最符合自己的习惯,功能完整度,拓展性
- 3【React】React 的StrictMode作用是什么,怎么使用?
- 4角色转变:新手项目管理的三大误区_新手项目经理认知误区
- 5Mendix UI页面布局以案说法_mendix 弹窗
- 6这应该是Spring中关于Bean的作用域与生命周期总结的最全文章了_以下有关spring中的bean的相关说法正确的是
- 7使用servlet+jsp实现学生管理系统_jsp+servlet+spring+dao系统
- 8c++调用YOLOv3模型批量测试目标检测结果_yolov3 ++c
- 9RGB、YUV和HSV颜色空间模型_hvvvvvhagrb
- 10前端新手小白的Vue3入坑指南
当前位置: article > 正文
智谱AI GLM-4V-9B视觉大模型环境搭建&推理
作者:神奇cpp | 2024-06-30 23:40:28
赞
踩
glm-4v
引子
最近在关注多模态大模型,之前4月份的时候关注过CogVLM(CogVLM/CogAgent环境搭建&推理测试-CSDN博客)。模型整体表现还不错,不过不支持中文。智谱AI刚刚开源了GLM-4大模型,套餐里面包含了GLM-4V-9B大模型,模型基于 GLM-4-9B 的多模态模型 GLM-4V-9B。GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。嗯,,,很厉害 ,OK,那就让我们开始吧。
一、环境搭建
1、模型下载
git clone 魔搭社区
2、代码下载
git clone GitHub - THUDM/GLM-4: GLM-4 series: Open Multilingual Multimodal Chat LMs | 开源多语言多模态对话模型
3、安装环境
docker run -it -v /datas/work/zzq/:/workspace --gpus=all pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel bash
cd /workspace/GLM-4V/GLM-4/composite_demo
pip install -r requirements.txt -i Simple Index
二、代码运行
1、官方代码运行
- import torch
- from PIL import Image
- from transformers import AutoModelForCausalLM, AutoTokenizer
-
- device = "cuda"
-
- tokenizer = AutoTokenizer.from_pretrained("model/glm-4v-9b", trust_remote_code=True)
-
- query = '描述这张图片'
- image = Image.open("longbench.png").convert('RGB')
- inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}],
- add_generation_prompt=True, tokenize=True, return_tensors="pt",
- return_dict=True) # chat mode
-
- inputs = inputs.to(device)
- model = AutoModelForCausalLM.from_pretrained(
- "model/glm-4v-9b",
- torch_dtype=torch.bfloat16,
- low_cpu_mem_usage=True,
- trust_remote_code=True
- ).to(device).eval()
-
- gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
- with torch.no_grad():
- outputs = model.generate(**inputs, **gen_kwargs)
- outputs = outputs[:, inputs['input_ids'].shape[1]:]
- print(tokenizer.decode(outputs[0]))
python glm-4v_test_demo.py
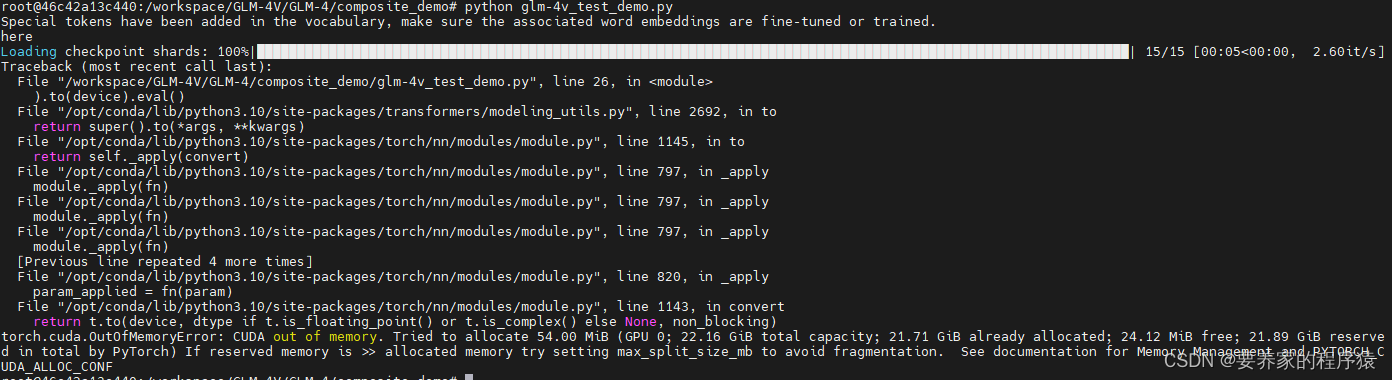 哦吼,显存爆了,据传说要32G显存,那老夫就无能为力了。
哦吼,显存爆了,据传说要32G显存,那老夫就无能为力了。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/774385
推荐阅读

相关标签

