
- 1计算机网络中23是什么端口号,什么是网络端口,端口有哪些分类-电脑自学网
- 2【话题】程序员应该有什么职业素养
- 3java的JVM学习总结第一章——JVM与java的体系结构
- 4【文献阅读】受山体阴影影响的冰湖制图方法研究(Li JunLi等人,2018.09,IJRS)_阴影损失文献
- 5【数据结构】线性表之《带头双向循环链表》超详细实现
- 6LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战_dashscope中的llm的api
- 7ue4 UMG添加到场景_unreal umg放到世界空间
- 8译文:dBA和dBC的不同_dba和dbc的区别
- 9网站高性能架构设计——web前端与池化_前端架构设计
- 10spring整合openAI大模型之Spring AI_spring ai maven
YOLOv9有效提点|加入SE、CBAM、ECA、SimAM等几十种注意力机制(一)_yolov9加注意力机制
赞
踩

专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,助力高效涨点!!!
一、本文介绍
本文将以SE注意力机制为例,演示如何在YOLOv9种添加注意力机制!
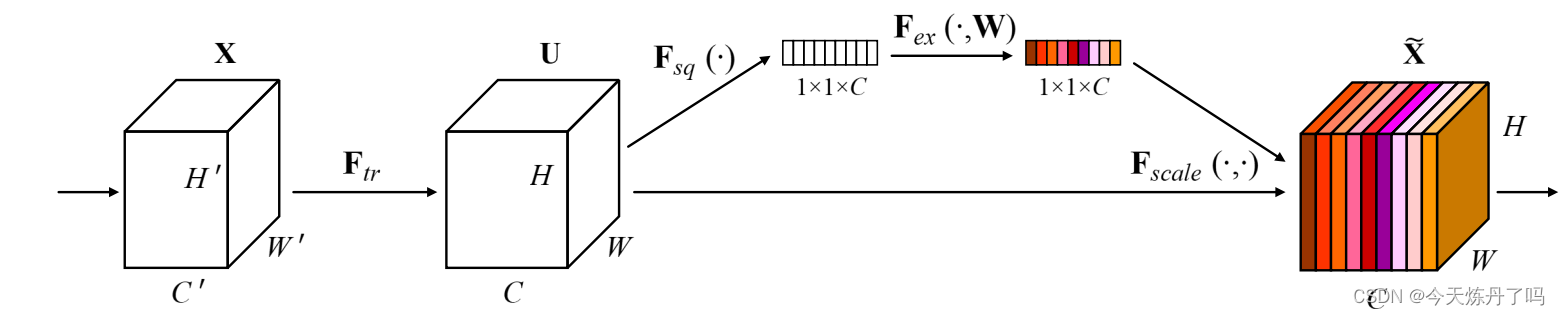
《Squeeze-and-Excitation Networks》
SENet提出了一种基于“挤压和激励”(SE)的注意力模块,用于改进卷积神经网络(CNN)的性能。SE块可以适应地重新校准通道特征响应,通过建模通道之间的相互依赖关系来增强CNN的表示能力。这些块可以堆叠在一起形成SENet架构,使其在多个数据集上具有非常有效的泛化能力。
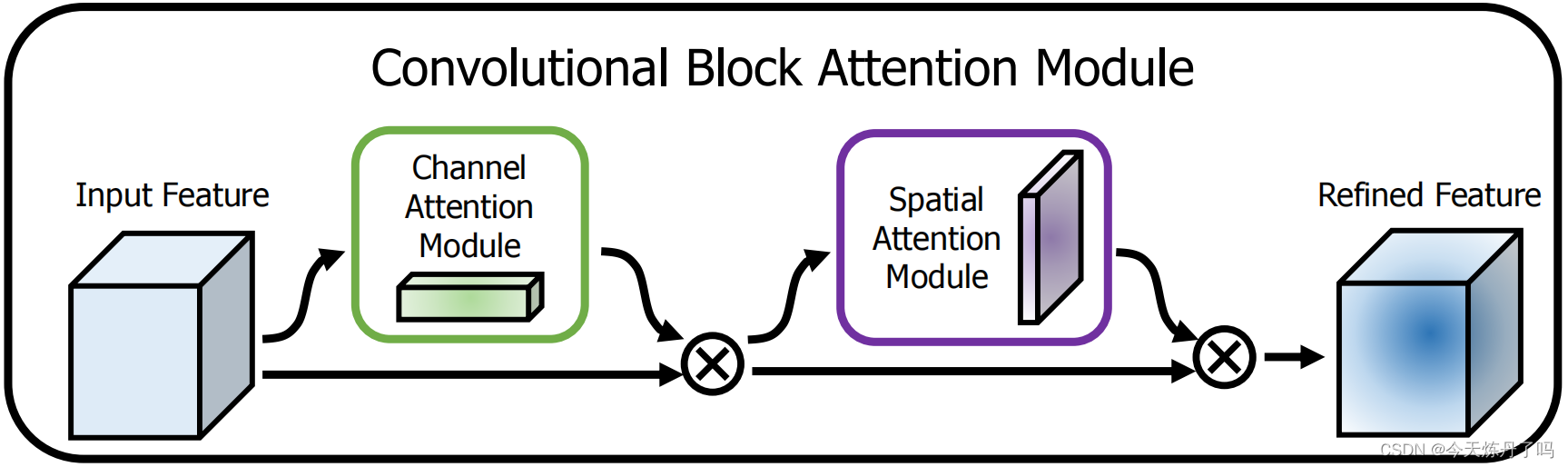
《CBAM:Convolutional Block Attention Module》
CBAM模块能够同时关注CNN的通道和空间两个维度,对输入特征图进行自适应细化。这个模块轻量级且通用,可以无缝集成到任何CNN架构中,并可以进行端到端训练。实验表明,使用CBAM可以显著提高各种模型的分类和检测性能。
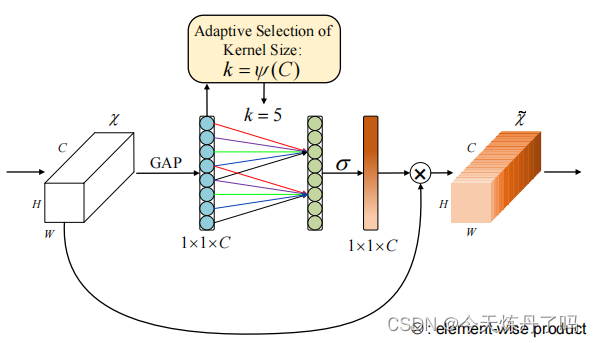
《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》
通道注意力模块ECA,可以提升深度卷积神经网络的性能,同时不增加模型复杂性。通过改进现有的通道注意力模块,作者提出了一种无需降维的局部交互策略,并自适应选择卷积核大小。ECA模块在保持性能的同时更高效,实验表明其在多个任务上具有优势。
《SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks》
SimAM一种概念简单且非常有效的注意力模块。不同于现有的通道/空域注意力模块,该模块无需额外参数为特征图推导出3D注意力权值。具体来说,SimAM的作者基于著名的神经科学理论提出优化能量函数以挖掘神经元的重要性。该模块的另一个优势在于:大部分操作均基于所定义的能量函数选择,避免了过多的结构调整。

适用检测目标: YOLOv9模块通用改进
二、改进步骤
以下以SE注意力机制为例在YOLOv9中加入注意力代码,其他注意力机制同理!
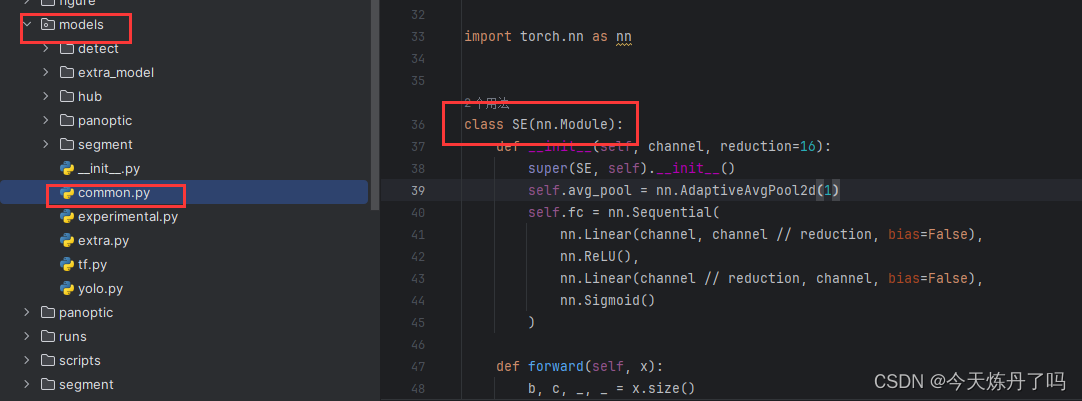
2.1 复制代码
将SE的代码辅助到models包下common.py文件中。
2.2 修改yolo.py文件
在yolo.py脚本的第700行(可能因YOLOv9版本变化而变化)增加下方代码。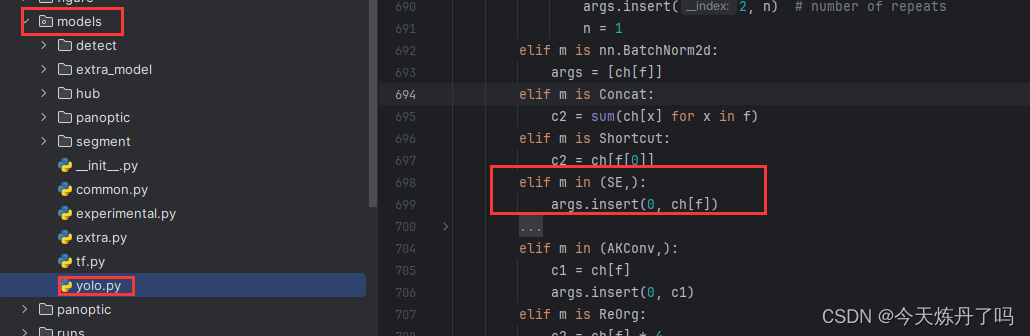
- elif m in (SE,):
- args.insert(0, ch[f])
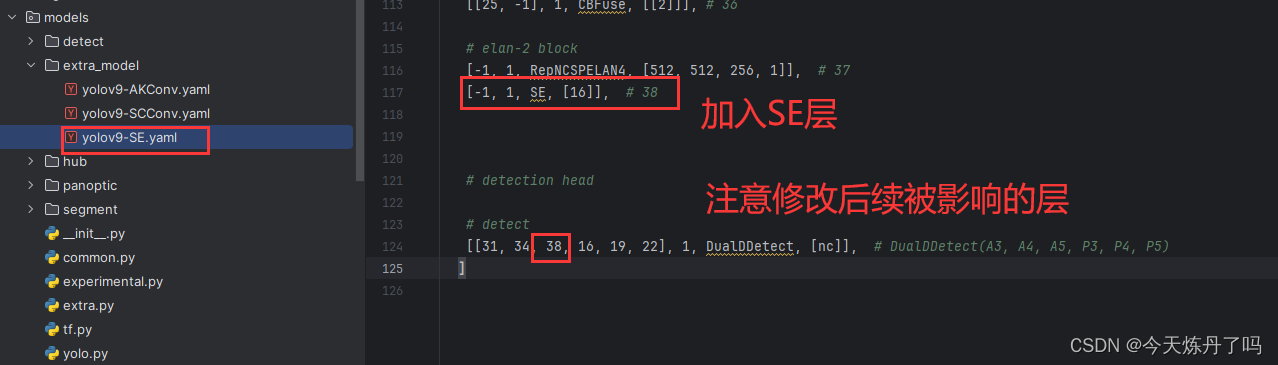
2.3 创建配置文件
创建模型配置文件(yaml文件),将我们所作改进加入到配置文件中(这一步的配置文件可以复制models - > detect 下的yaml修改。)。对YOLO系列yaml文件不熟悉的同学可以看我往期的yaml详解教学!
- # YOLOv9
- # Powered bu https://blog.csdn.net/StopAndGoyyy
- # parameters
- nc: 80 # number of classes
- depth_multiple: 1 # model depth multiple
- width_multiple: 1 # layer channel multiple
- #activation: nn.LeakyReLU(0.1)
- #activation: nn.ReLU()
-
- # anchors
- anchors: 3
-
- # YOLOv9 backbone
- backbone:
- [
- [-1, 1, Silence, []],
-
- # conv down
- [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
-
- # conv down
- [-1, 1, Conv, [128, 3, 2]], # 2-P2/4
-
- # elan-1 block
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
-
- # avg-conv down
- [-1, 1, ADown, [256]], # 4-P3/8
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
-
- # avg-conv down
- [-1, 1, ADown, [512]], # 6-P4/16
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
-
- # avg-conv down
- [-1, 1, ADown, [512]], # 8-P5/32
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
- ]
-
- # YOLOv9 head
- head:
- [
- # elan-spp block
- [-1, 1, SPPELAN, [512, 256]], # 10
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 7], 1, Concat, [1]], # cat backbone P4
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 5], 1, Concat, [1]], # cat backbone P3
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)
-
- # avg-conv-down merge
- [-1, 1, ADown, [256]],
- [[-1, 13], 1, Concat, [1]], # cat head P4
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)
-
- # avg-conv-down merge
- [-1, 1, ADown, [512]],
- [[-1, 10], 1, Concat, [1]], # cat head P5
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)
-
-
- # multi-level reversible auxiliary branch
-
- # routing
- [5, 1, CBLinear, [[256]]], # 23
- [7, 1, CBLinear, [[256, 512]]], # 24
- [9, 1, CBLinear, [[256, 512, 512]]], # 25
-
- # conv down
- [0, 1, Conv, [64, 3, 2]], # 26-P1/2
-
- # conv down
- [-1, 1, Conv, [128, 3, 2]], # 27-P2/4
-
- # elan-1 block
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28
-
- # avg-conv down fuse
- [-1, 1, ADown, [256]], # 29-P3/8
- [[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31
-
- # avg-conv down fuse
- [-1, 1, ADown, [512]], # 32-P4/16
- [[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34
-
- # avg-conv down fuse
- [-1, 1, ADown, [512]], # 35-P5/32
- [[25, -1], 1, CBFuse, [[2]]], # 36
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37
- [-1, 1, SE, [16]], # 38
-
-
-
- # detection head
-
- # detect
- [[31, 34, 38, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
- ]
3.1 训练过程
最后,复制我们创建的模型配置,填入训练脚本(train_dual)中(不会训练的同学可以参考我之前的文章。),运行即可。

SE代码
- class SE(nn.Module):
- def __init__(self, channel, reduction=16):
- super(SE, self).__init__()
- self.avg_pool = nn.AdaptiveAvgPool2d(1)
- self.fc = nn.Sequential(
- nn.Linear(channel, channel // reduction, bias=False),
- nn.ReLU(),
- nn.Linear(channel // reduction, channel, bias=False),
- nn.Sigmoid()
- )
-
- def forward(self, x):
- b, c, _, _ = x.size()
- y = self.avg_pool(x).view(b, c)
- y = self.fc(y).view(b, c, 1, 1)
- return x * y.expand_as(x)
CBAM代码
- import numpy as np
- import torch
- from torch import nn
- from torch.nn import init
-
-
- class ChannelAttention(nn.Module):
- def __init__(self, channel, reduction=16):
- super().__init__()
- self.maxpool = nn.AdaptiveMaxPool2d(1)
- self.avgpool = nn.AdaptiveAvgPool2d(1)
- self.se = nn.Sequential(
- nn.Conv2d(channel, channel // reduction, 1, bias=False),
- nn.ReLU(),
- nn.Conv2d(channel // reduction, channel, 1, bias=False)
- )
- self.sigmoid = nn.Sigmoid()
-
- def forward(self, x):
- max_result = self.maxpool(x)
- avg_result = self.avgpool(x)
- max_out = self.se(max_result)
- avg_out = self.se(avg_result)
- output = self.sigmoid(max_out + avg_out)
- return output
-
-
- class SpatialAttention(nn.Module):
- def __init__(self, kernel_size=7):
- super().__init__()
- self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2)
- self.sigmoid = nn.Sigmoid()
-
- def forward(self, x):
- max_result, _ = torch.max(x, dim=1, keepdim=True)
- avg_result = torch.mean(x, dim=1, keepdim=True)
- result = torch.cat([max_result, avg_result], 1)
- output = self.conv(result)
- output = self.sigmoid(output)
- return output
-
-
- class CBAMBlock(nn.Module):
-
- def __init__(self, channel=512, reduction=16, kernel_size=7):
- super().__init__()
- self.ca = ChannelAttention(channel=channel, reduction=reduction)
- self.sa = SpatialAttention(kernel_size=kernel_size)
-
- def init_weights(self):
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- init.kaiming_normal_(m.weight, mode='fan_out')
- if m.bias is not None:
- init.constant_(m.bias, 0)
- elif isinstance(m, nn.BatchNorm2d):
- init.constant_(m.weight, 1)
- init.constant_(m.bias, 0)
- elif isinstance(m, nn.Linear):
- init.normal_(m.weight, std=0.001)
- if m.bias is not None:
- init.constant_(m.bias, 0)
-
- def forward(self, x):
- b, c, _, _ = x.size()
- out = x * self.ca(x)
- out = out * self.sa(out)
- return out
ECA代码
- class ECAAttention(nn.Module):
-
- def __init__(self, kernel_size=3):
- super().__init__()
- self.gap = nn.AdaptiveAvgPool2d(1)
- self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2)
- self.sigmoid = nn.Sigmoid()
-
- def init_weights(self):
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- init.kaiming_normal_(m.weight, mode='fan_out')
- if m.bias is not None:
- init.constant_(m.bias, 0)
- elif isinstance(m, nn.BatchNorm2d):
- init.constant_(m.weight, 1)
- init.constant_(m.bias, 0)
- elif isinstance(m, nn.Linear):
- init.normal_(m.weight, std=0.001)
- if m.bias is not None:
- init.constant_(m.bias, 0)
-
- def forward(self, x):
- y = self.gap(x) # bs,c,1,1
- y = y.squeeze(-1).permute(0, 2, 1) # bs,1,c
- y = self.conv(y) # bs,1,c
- y = self.sigmoid(y) # bs,1,c
- y = y.permute(0, 2, 1).unsqueeze(-1) # bs,c,1,1
- return x * y.expand_as(x)
SimAM代码
- class SimAM(torch.nn.Module):
- def __init__(self, e_lambda=1e-4):
- super(SimAM, self).__init__()
-
- self.activaton = nn.Sigmoid()
- self.e_lambda = e_lambda
-
- def __repr__(self):
- s = self.__class__.__name__ + '('
- s += ('lambda=%f)' % self.e_lambda)
- return s
-
- @staticmethod
- def get_module_name():
- return "simam"
-
- def forward(self, x):
- b, c, h, w = x.size()
-
- n = w * h - 1
-
- x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
- y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
-
- return x * self.activaton(y)
如果觉得本文章有用的话给博主点个关注吧!

