
热门标签
热门文章
- 1【Caddy】Caddy实践1——此网站无法提供安全连接_安装caddy出错
- 2Git Cherry-Pick命令详解:轻松选取与移植提交_cherrypick 多个提交
- 3手把手教NLP小白如何用PyTorch构建和训练一个简单的情感分类神经网络_训练一种词向量,利用pytorch,搭建情感分析的深度模型运行截图
- 4Nginx 配置特定IP访问_nginx只允许指定ip访问
- 5NLP案例——命名实体识别(Named Entity Recongition)_nlp命名实体识别
- 6uibotrga初级/中级认证选择题答案_uibot初级认证选择题答案
- 7自定义view的简单实现(一)_简单实现自定义view
- 8cadence从原理图到pcb_cadence原理图转pcb
- 9LabelMe和x-anyLabeling标注工具的合二为一版_anylabelme
- 10brew常见命令 自用 实践笔记_慎用 brew upgrade
当前位置: article > 正文
项目实训:python whisper安装运行 实现语音识别技术_whisper运行教程
作者:神奇cpp | 2024-06-25 01:20:29
赞
踩
whisper运行教程
1.最好用python3.9以上的版本
2.安装whisper库
pip install -U openai-whisper
 输入whisper查看是否安装成功
输入whisper查看是否安装成功
 3.下载ffmpeg并添加环境变量
3.下载ffmpeg并添加环境变量
Releases · BtbN/FFmpeg-Builds (github.com)
 下载成功后,配置环境变量,右键我的电脑->属性->高级系统设置->环境变量->系统变量->Path
下载成功后,配置环境变量,右键我的电脑->属性->高级系统设置->环境变量->系统变量->Path

将bin目录的地址添加进来
然后检查是否成功 win+R cmd,输入ffmpeg,显示如下,则安装成功

3.Whisper主要是基于Pytorch实现,所以需要在安装有pytorch的环境中使用。
安装pytorch
pip3 install torch torchvision torchaudio
4.安装zhconv,将繁体字转换为简体字
pip install zhconv5.测试
写一段代码
- import whisper
- import zhconv
-
- model = whisper.load_model("base", "cpu")
- mps_path = r"1.mp3"
- result = model.transcribe(mps_path, fp16=False, language='Chinese')
- s = result["text"]
- s1 = zhconv.convert(s, 'zh-cn')
- print(s1)
运行,报错,错误信息:
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
参考https://blog.csdn.net/zdm_0301/article/details/133854913?spm=1001.2014.3001.5506
感谢这位博主,成功解决这个给问题,把参数改为true后,重启电脑,运行成功
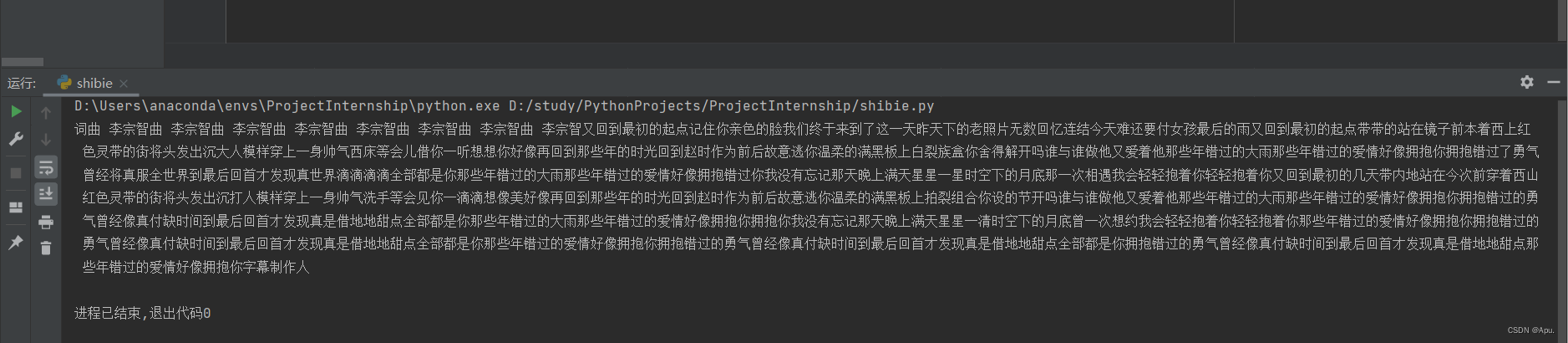 没有做分词操作,后续继续处理,总体识别还是不错的。
没有做分词操作,后续继续处理,总体识别还是不错的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/754536
推荐阅读
相关标签

