
- 1【深度学习基础】反向传播BP算法原理详解及实战演示(附源码)_反向传播算法
- 2Navicat Premium 最新版本12.1..12-64bit 完美破解,亲测可用!_navicat version 12.1
- 3Cloud Native安全揭秘
- 4在Proxmox VE同一局域网设备安装内网穿透实现异地远程访问本地平台_pve 内网穿透
- 5Java线程上下文-ThreadLocal的那些事_java中的上下文是不是就是线程变量
- 6基于人眼感知质量的端云结合画质及带宽优化实践
- 7GPU驱动工作流程的学习_gpu驱动开发者指南
- 8android 需要常量表达式_android中错误显示常量需要表达式怎么解决
- 9Neo4j CTO:RAG的下半场GraphRAG!_neo4j可以点周围按钮
- 10获取token
分布式SQL引擎-----------Inceptor(学习使用)
赞
踩
一、 使用场景
1. 批处理; 2.统计分析;3. 图计算和图检索;4.交互式统计分析
二、Inceptor架构
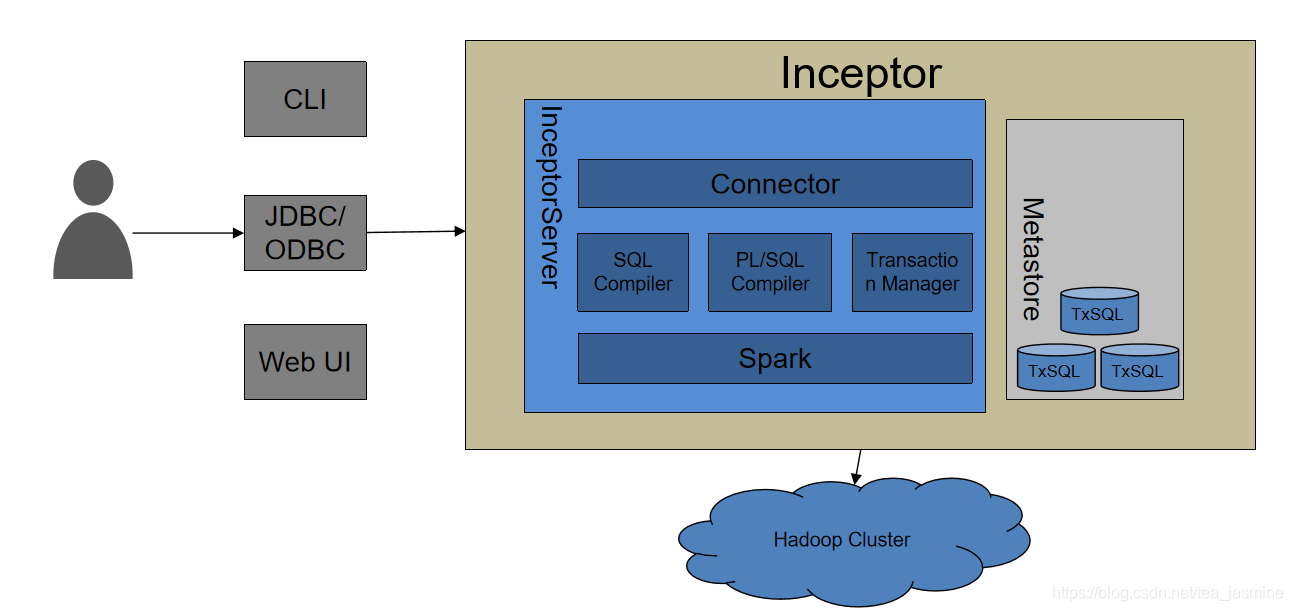
- InceptorServer
其中,connector是对BI/ETL工具提供标准JDBC\ODBC接口;
SQL Compiler是语法解析器、优化器、代码生成;
PL/SQL Compiler是存储过程解析器、控制流优化器、并行优化器;
Transaction Manager是分布式增删改、事务并发控制器;
Spark---更高计算效率、大数据量下的高稳定;
整体以Executor(一组用于分布式计算的计算资源)形式存在,可在界面上进行配置。
- Metastore
存储Inceptor元数据,后台数据存储在TxSQL(MySQL集群),
主要元数据包括 数据库信息、表信息以及字段属性、分区分桶信息。
三、Inceptor SQL
$ beeline -u "jdbc:hive2://<server_ip/hostname>:10000/default" -n <username> -p <password>
四、数据类型(大体的,不是指Inceptor中的数据类型)
- 基本数据类型
TINYINT(1字节)、SMALLINT(2字节)、INT(4字节)、BIGINT(8字节)
FLOAT、DOUBLE、DECIMAL(不可变的、任意精度的,有符号的十进制数)、BOOLEAN、
STRING、VARCHAR(可变长度字符)、
DATA(日期)、TIMESTAMP(表示日期和时间)、INTERVAL DAY/MONTH/YEAR(用于存储一段以年,月火日为单位的时间)
- 复杂数据类型
ARRAY、 MAP(无序键值对,键类型必须是原生数据类型,值的类型可以是原生或者复杂)、STRUCT(一组命名的字段)
五、Inceptor中的数据类型
所有的CHAR\NCHAR\VARCHAR\NVACHAR 在Inceptor中都是 STRING 类型;
Numeric、decimal对应decimal(a,b),参数a是共几位有效数,b是小数点后有几位。
六、一些常见命令
创建新数据库
>CREATE DATABASE test_db;
查看数据库信息
> DESCRIBE DATABASE test_db;
要查看指定数据库下所有的表
> SHOW TABLES;
表的分区:PARTITIONED BY子句 (PARTITIONED 分段的意思)
表的分桶:CLUSTERED BY子句 (CLUSTERED 群集的; 成群的)
基础建表语句:
> CREATE TABLE table_name (col1 col_type1, col2 col_type2, ...);
创建一个表存放一次查询的结果
> CREATE TABLE table_name AS SELECT select_statement;
重命名
> ALTER TABLE table_name RENAME TO new_table_name;
改动表的注释
> ALTER TABLE table_name SET TBLPROPERTIES ('comment' = new_comment);
Inceptor支持对表的单值分区和范围分区
在逻辑上,将表中的数据按分区放在表目录下的对应子目录中,一个分区对应一个子目录
在物理上,分区表和未分区表没有区别
添加分区
> ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'];
注意,该目录必须是HDFS目录,不可以是文件。
添加range partition
> ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION VALUES LESS THAN (values)
删除分区
> ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec; 动态分区: ALTER TABLE table name DROP PARTITION partition_name;
分桶是通过改变数据的存储分布让某些任务(比如取样,join等)运行得更快,对查询起到一定的优化作用,表的分桶在建表时完成,不允许修改。
- CREATE TABLE table_name (col_name data_type, col_name data_type, ...)
- CLUSTERED BY (col_name,)
- [SORTED BY (col_name, col_name,...)[ASC|DESC]]
- INTO n BUCKETS
-
- INTO n BUCKETS指定桶的数量
- SORTED BY根据指定的键排序。ASC表示升序,DESC表示降序。默认顺序是升序。
- 和分区键不同,分桶键必须是表中的列。
向分桶表写入数据只能通过INSERT,而不能LOAD。
- 正确的给分桶表写入数据
- set hive.enforce.bucketing = true;
-
- INSERT OVERWRITE TABLE table_name SELECT * FROM table_name;
导入数据:LOAD
插入数据:INSERT
数据导入要预处理,看编码格式和以什么为换行符
file$filename
需要转码:
- iconv -f gbk -t utf-8 $sourceFile > $targetFile
- iconv是转码工具,-f源编码格式,-t目标编码格式。转码后再上传。
WHERE和HAVING
WHERE子句和HAVING子句的区别在于,一次查询中如果有WHERE子句,Inceptor会先执行WHERE子句的过滤条件再执行SELECT语句,而查询中如果用到了HAVING子句,Inceptor会先执行SELECT语句,再执行HAVING子句。
换句话说,WHERE在SELECT之前过滤,而HAVING在SELECT之后过滤。
HAVING语句在GROUPBY语句之后;SQL会在分组之后计算HAVING语句。
HAVING后可跟聚合函数,WHERE后不能有聚合函数。
PL/SQL
是一种具有流程控制的数据库程序设计语言。
PL/SQL块由四个基本部分组成:声明、执行体开始、异常处理、执行体结束
- DECLARE --声明(可选部分)
- transid STRING
- BEGIN --执行体开始(必要部分)
- SELECT trans_id into transid from transactions where acc_num=6513065
- DBMS_OUTPUT.put_line(transid)
- EXCEPTION --异常处理(可选部分)
- WHEN too_many_rows
- THEN
- DBMS_OUTPUT.put_line ('too many rows')
- END; --执行体结束(必要部分)
存储过程
- 创建存储过程
- CREATE OR REPLACE PROCEDURE hello_world()
- IS
- DECLARE
- l_message STRING := 'Hello World!'
- BEGIN
- DBMS_OUTPUT.put_line (l_message)
- END;
-
- 调用存储过程
- BEGIN
- hello_world()
- END;
持续更新!

