
Iceberg原理和项目使用技巧
赞
踩
目录
引言
Apache Iceberg作为一款新兴的数据湖解决方案在实现上高度抽象,在存储上能够对接当前主流的HDFS,S3文件系统并且支持多种文件存储格式,例如Parquet、ORC、AVRO。相较于Hudi、Delta与Spark的强耦合,Iceberg可以与多种计算引擎对接,目前社区已经支持Spark读写Iceberg、Impala/Hive查询Iceberg。目前社区版本已经到了1.1.0的版本,iceberg 已经升级只适配fink 1.14 版本及其以上高版本 ,本文讨论的的Iceberg为1.1.0的版本
Iceberg 的定义
Iceberg 是一种表格式的规范,以及实现了这种规范的代码库,通过提供了一组 API 供计算引擎或其它进程调用。Iceberg 通过元数据文件给数据文件加了一层索引。它可以适配Presto,Spark等引擎提供高性能的读写和元数据管理功能。
从Iceberg的定义中不难看出,这类技术它的定位是在计算引擎之下,又在存储之上。同时,它也是一种数据存储格式,Iceberg则称其为"table format"。因此,这类技术可以看作介于计算引擎和数据存储格式中间的数据组织格式,通过特定的方式将数据和元数据组织起来,所以称之为数据组织格式更为合理,而Iceberg将其定义为表格式也直观地反映出了它的定位和功能。
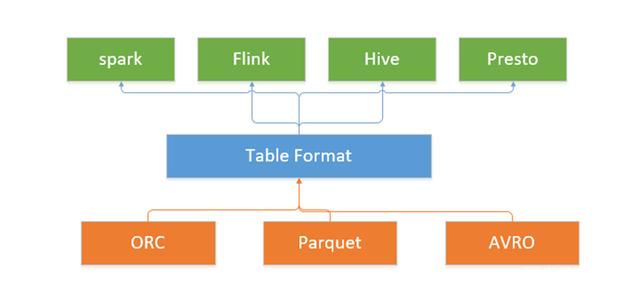
与其他数据湖产品对比
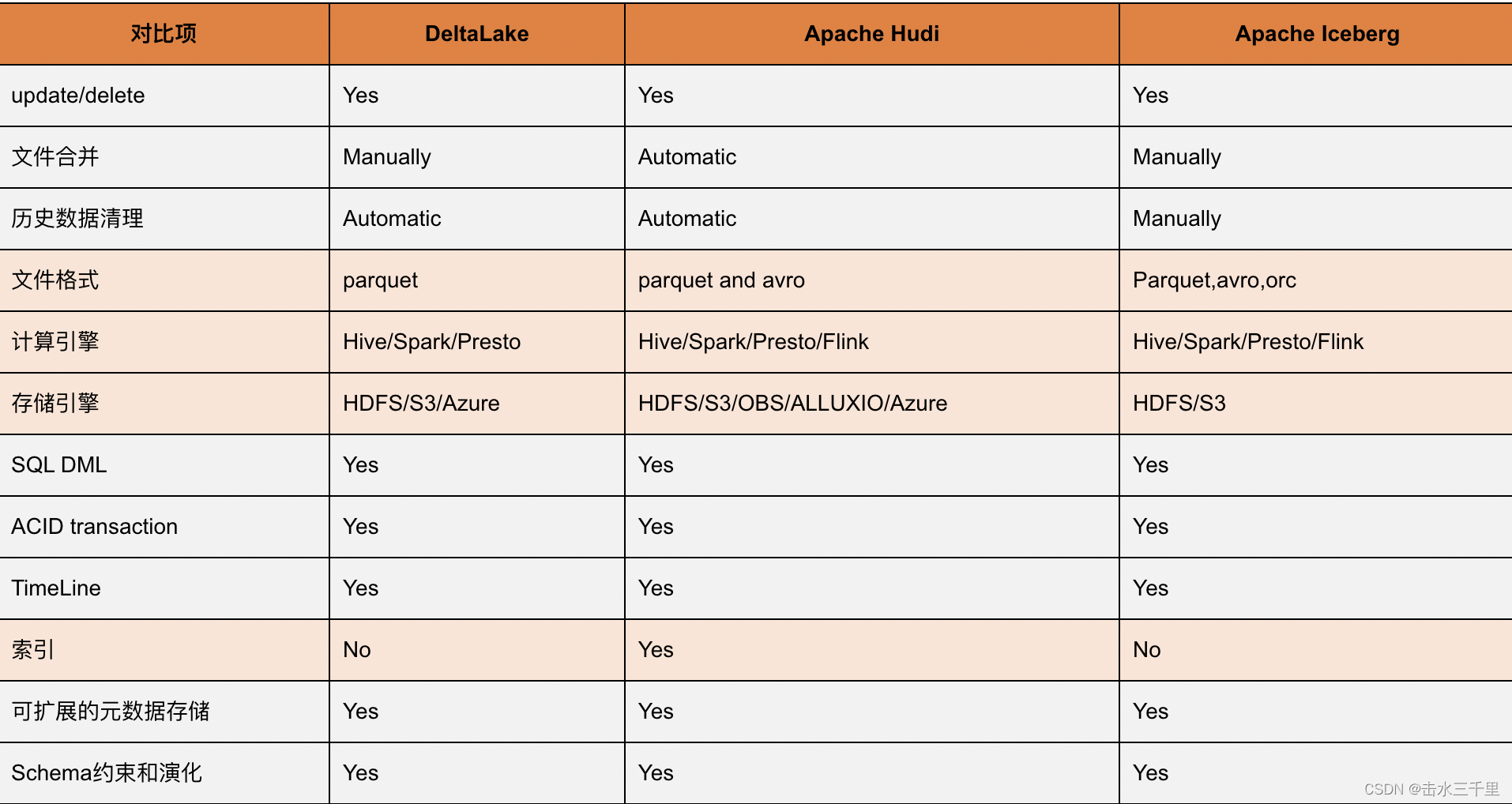
Hive 表存在的问题
1.现在的计算引擎(Presto Spark)都是分布式执行的,以 Spark 为例,假如某个表有 100 个数据文件,执行时一共有 10 个 Executor,在 Exector 执行前,Driver 会对数据文件进行切分,最终每个 Executor 可能分配 10 个数据文件。由于 Hive 表格式只保存了数据文件的目录,所以在文件切分前会使用文件系统的 list 操作,列出所有的数据文件。
list 操作存在以下问题:
- HDFS 文件系统下,如果频繁大量的调用 list 操作会给 NameNode 的 RPC 带来压力;如果文件数过多,list 会比较耗时,曾经就遇到一个这样的例子,由于一个表使用了二级分区,生成了大量的分区和文件,在执行全表扫描的时候,仅仅是文件切分就花了10 分钟。
- 对象存储下 list 操作非常慢
2. 由于 Hive 表格式只保存了数据文件的目录,所以在 Executor 执行时,先把计算结果写入临时目录,等待 Executor 全部执行完成后,Driver 端会把临时文件目录 rename 到正式的文件目录,此操作依赖文件系统的 rename 操作。在对象存储中 rename 操作非常慢。
小结一下,由于 list 和 rename 在对象存储上的性能问题,基本上无法直接使用成本更低的对象存储来替代 HDFS 存储。
3. Hive 表的 schema 集中存储在 metastore 中,metastore 很容易成为性能瓶颈,同时也会带来分库分表等运维成本。
4 Hive 表的统计信息(文件行数,文件大小,文件个数) 不是强制要求写入的,很多情况不存在统计信息或者是过时的,planner 层无法有效的做基于代价的优化。另外统计信息的粒度很粗是表级别的。
5. 不支持删除,更新表等操作,或者成本非常高,需要重刷数据
6. 如果同时存在 读-写,写-写 任务时,无法保证任务的一致性,会发生莫名其妙的错误,或刚写入的数据被其它任务覆盖了。
文件组织结构
在 Insert 执行完成后,最终生成的文件结构,如下图所示,主要可以分为三类文件:
- 数据文件,普通的 Parquet 文件,存放着写入的数据。
- 元数据文件,主要是 avro 和 json 类型,这正是 Iceberg 表和 Hive 表的本质区别。
- catalog(version-hint.txt 文件,只有使用 Hadoop catalog 才会存在此文件)
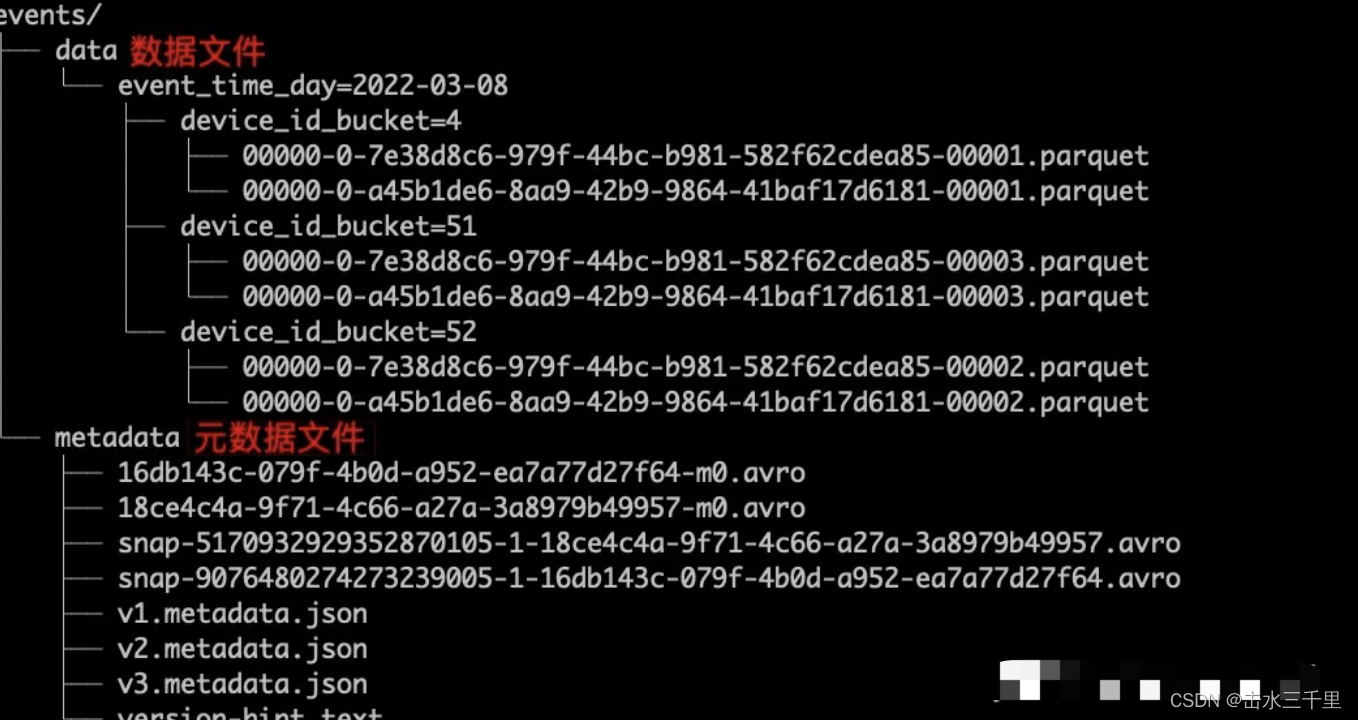
Iceberg数据结构

1、cataLog: HiveCatalog、HadoopCatalog、JDBCCatalog等,Catalog具体实现原子性能力
2、metadata:记录最新的快照信息历史快照信息以及最新的schema信息
3、Snapshot(ManifestList):每次提交都会生成一个Snapshot。记录了本次提交新增的清单文件和历史清单列表ManifestList
4、Manifest:DateFile的集合,记录了本次事务写入文件和分区的对应关系,以及字段的统计信息(min-max)用于文件过滤
5、DataFile:实际写入的数据文件,如Parquet、Avro等格式文件
Iceberg快的原因
因为iceberg 数据读写的过程中,在元数据上的优化,会在相同的算力下,更加快速的通过索引搜索到需要的数据块以及更少的数据参与数据的计算,这样会在计算效率上有很大的提升
Parquet Bloom Filter
Iceberg索引
优化Parquet Vectorized Read Decimal
多线程Plan Tasks,并发或者分布式的删除文件
建表的主要参数
- Ice 的SparkSQL 一定需要带上`hive_catalog` 为啥 默认不需要带 catalog,这个是因为sparkSQL自己默认实现了,用户不需要感知,有兴趣可以自行了解。可以看执行计划,执行计划里面,hive表会是 spark_catalog.db.table
- format-version 一般来说 ice会存在两个表结构,V1和V2
V1 适用于读多写少的场景,不支持主键upsert操作,写是合并 Copy On Write(COW)
V2 支持主键upsert操作,适用写多读少的场景,默认使用读时合并 Merge On Read(MOR),但是V2也支持 COW,在建表是可以指定
详细区别,感兴趣的可以深入研究。建议在按照各自的业务选择合适的format
- 'write.spark.fanout.enabled'='true'
该参数是在存在二级及多级分区的时候加上,可避免相对应地报错。大致原因就是ice在写表的时候会对数据进行排序,写完文件后会关闭分区文件。有兴趣可以自行了解原理
- 'write.metadata.delete-after-commit.enabled'='true', 'write.metadata.previous-versions-max'='10'
保存元数据的个数,不设置会一直保存,设置以后会自行删除对应的过期元数据文件
实战应用
根据参数指定数据流向目标地址 (如果使用添j加如图一的三个配置文件访问Iceberg这种访问速度比较慢),通过缓存加速gfs协议可以提高对Iceberg的访问速度

snapshot-count'='2')*/ flink 1.14在消费iceberg流的时候可以加上'max-planning-snapshot-count'的参数指定最多拉取的snapshot数。现在不指定会导致一次性拉取全部数据,然后checkpoint完全卡住。
获取运行环境StreamExecutionEnvironment.getExecutionEnvironment
- import com.xxx.ocha.infra.config.configLoaderImpl.ApolloConfigLoader
- import com.xxx.ocha.infra.flink.UDFs.{FormatUnixWithZone, ToJsonStringUdf}
- import org.apache.flink.api.common.restartstrategy.RestartStrategies
- import org.apache.flink.configuration.Configuration
- import org.apache.flink.streaming.api.CheckpointingMode
- import org.apache.flink.streaming.api.environment.{LocalStreamEnvironment, StreamExecutionEnvironment => JavaEnv}
- import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
- import org.apache.flink.table.api.bridge.scala._
- import org.slf4j.{Logger, LoggerFactory}
-
- object ExecEnvUtil {
- val log: Logger = LoggerFactory.getLogger(this.getClass)
-
- def getExecEnv(env: String): StreamExecutionEnvironment = {
- streamEnv match {
- case Some(env) => env
- case _ =>
- val someEnv = env.toLowerCase match {
- case "dev" =>
- val conf = new Configuration()
- // dev环境配置metrics打印版本
- conf.setString("metrics.reporters", "my_slf4j_reporter")
- conf.setString("metrics.reporter.my_slf4j_reporter.factory.class", "org.apache.flink.metrics.slf4j.Slf4jReporterFactory")
- conf.setString("metrics.reporter.my_slf4j_reporter.interval", "60 SECONDS")
- conf.setString("pipeline.operator-chaining", "false")
-
- new StreamExecutionEnvironment(JavaEnv.getExecutionEnvironment(conf))
- case _ =>
- StreamExecutionEnvironment.getExecutionEnvironment
- }
- streamEnv = Some(someEnv)
- configEnv(someEnv)
- someEnv
- }
- }
-
- private def configEnv(env: StreamExecutionEnvironment): Unit = {
- configRestartStrategy(env)
- configCheckpoint(env)
- }
-
- private def configRestartStrategy(env: StreamExecutionEnvironment): Unit = {
- env.getJavaEnv match {
- case _: LocalStreamEnvironment =>
- log.info("检测到本地环境,使用0容忍重启策略")
- env.setRestartStrategy(RestartStrategies.noRestart)
- case _ => // do nothing
- }
- }
-
- private def configCheckpoint(env: StreamExecutionEnvironment): Unit = {
- val checkpointConfig = env.getCheckpointConfig
- val conf = ApolloConfigLoader.getConfigLoader
- val CHECKPOINT_TIMEOUT = conf.getConfig("job.checkpoint.timeout", String.valueOf(60 * 60000L)).toLong
- val CHECKPOINT_INTERVAL = conf.getConfig("job.checkpoint.interval", String.valueOf(60000L)).toLong
- // 每 interval ms 开始一次 checkpoint
- checkpointConfig.setCheckpointInterval(CHECKPOINT_INTERVAL)
- // enable Unaligned checkpoint
- checkpointConfig.enableUnalignedCheckpoints()
- // 确认 checkpoints 之间的时间
- checkpointConfig.setMinPauseBetweenCheckpoints(CHECKPOINT_INTERVAL)
- // Checkpoint 超时时间
- checkpointConfig.setCheckpointTimeout(CHECKPOINT_TIMEOUT)
- // 同一时间只允许一个 checkpoint 进行
- checkpointConfig.setMaxConcurrentCheckpoints(1)
- // 允许1次失败
- checkpointConfig.setTolerableCheckpointFailureNumber(1)
- // at least once
- checkpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE)
- }
-
- private def assignCommonUdf(tEnv: StreamTableEnvironment): Unit = {
- tEnv.createTemporarySystemFunction("format_unix_with_zone", classOf[FormatUnixWithZone])
- tEnv.createTemporarySystemFunction("fastjson_to_json", classOf[ToJsonStringUdf])
- }
-
- private lazy val tableEnv: StreamTableEnvironment = {
- val tEnv = streamEnv match {
- case Some(env) => StreamTableEnvironment.create(env)
- case _ => throw new RuntimeException("请先调用getExecEnv方法获取StreamExecutionEnvironment")
- }
- assignCommonUdf(tEnv)
- tEnv
- }
- private var streamEnv: Option[StreamExecutionEnvironment] = None
-
- object Implicits {
- implicit class StreamExecutionEnvironmentExt(execEnv: StreamExecutionEnvironment) {
- // 保证包装类由单例模式创建
- streamEnv match {
- case Some(env) =>
- assert(env == execEnv, "请勿重复创建StreamExecutionEnvironment")
- case _ => throw new RuntimeException("请先调用getExecEnv方法获取StreamExecutionEnvironment")
- }
-
- def tblEnv(): StreamTableEnvironment = tableEnv
-
- def enableIceberg(env: String = null): Unit = {
- execEnv.getJavaEnv match {
- case _: LocalStreamEnvironment =>
- log.info(s"检测到本地环境,本地路径创建iceberg: 'file://${System.getProperty("user.home")}/test-iceberg'")
- tableEnv.executeSql(
- s"""
- |CREATE Catalog iceberg_catalog WITH (
- | 'type'='iceberg',
- | 'catalog-type'='hadoop',
- | 'property-version'='1',
- | 'warehouse'='file://${System.getProperty("user.home")}/test-iceberg'
- |)
- |""".stripMargin
- )
- return
- case _ => // do nothing
- }
-
- env.toLowerCase match {
- case "prod" =>
- tableEnv.executeSql(
- s"""
- |CREATE Catalog iceberg_catalog WITH (
- | 'type'='iceberg',
- | 'catalog-type'='hive',
- | 'uri'='thrift://xx.xx.xx.xx:7004,thrift://xx.xx.xx.xx:7004',
- | 'property-version'='1',
- | 'warehouse'='gfs://xx.xx.xx.xx:9200,xx.xx.xx.xx:9200,xx.xx.xx.xx:9200/cosn'
- |)
- |""".stripMargin
- )
- case "stg" =>
- tableEnv.executeSql(
- s"""
- |CREATE Catalog iceberg_catalog WITH (
- | 'type'='iceberg',
- | 'catalog-type'='hive',
- | 'uri'='thrift://xx.xx.xx.xx:7004,thrift://xx.xx.xx.xx:7004',
- | 'property-version'='1',
- | 'warehouse'='gfs://1xx.xx.xx.xx:9200/cosn_hive'
- |)
- |""".stripMargin
- )
- case _ => throw new RuntimeException("env must be prod or dev")
- }
- }
- }
- }
- }

写数据的逻辑
- def sink2Iceberg(dataStream: DataStream[LogMsg], stmtSet: Option[StreamStatementSet])(implicit env: StreamExecutionEnvironment): Option[StreamStatementSet] = {
- // 基本参数
- val (logIceTable, ptTimezone) = getLogSink2IcebergConf()
- val tblEnv = env.tblEnv()
- val thisStmtSet = stmtSet match {
- case Some(x) => x
- case None => tblEnv.createStatementSet()
- }
-
- // 建表语句
- tblEnv.executeSql(
- s"""
- |CREATE TABLE IF NOT EXISTS `iceberg_catalog`.$logIceTable (
- | `deal_time` BIGINT,
- | `file_key` STRING,
- | `trigger_time` BIGINT,
- | `kafka_produce_time` BIGINT,
- | `vehicle_id` STRING,
- | `uuid` STRING,
- | `vehicle_uuid` STRING,
- | `vehicle_type` STRING,
- | `soc_index` STRING,
- | `boot_count` STRING,
- | `part_number` STRING,
- | `commit` STRING,
- | `source` STRING,
- | `time_zone` STRING,
- | `timestamp` STRING,
- | `process` STRING,
- | `pid` STRING,
- | `level` STRING,
- | `text` STRING,
- | `adc_version` STRING,
- | `baseline` STRING,
- | `model_type` STRING,
- | `create_time` BIGINT,
- | `utc_timestamp` BIGINT,
- | `line_number` BIGINT,
- | `country` STRING,
- | `local_timezone` STRING,
- | `update_time` BIGINT,
- | `category` STRING,
- | `pt` STRING
- |) PARTITIONED BY (`pt`)
- |""".stripMargin)
-
- // 处理数据
- val tableRaw = tblEnv.fromDataStream(dataStream)
- val table2Sink = tblEnv.sqlQuery(
- s"""
- |SELECT
- | *,
- | SPLIT_INDEX(source, '.', 0) as category,
- | format_unix_with_zone(update_time, 'yyyyMMddHH', '$ptTimezone') as pt
- |FROM $tableRaw
- |""".stripMargin)
-
- Some(thisStmtSet.addInsertSql(
- s"""
- |INSERT INTO `iceberg_catalog`.$syslogIceTable
- |SELECT
- | `deal_time`,
- | `file_key`,
- | `trigger_time`,
- | `kafka_produce_time`,
- | `vehicle_id`,
- | `uuid`,
- | `vehicle_uuid`,
- | `vehicle_type`,
- | `soc_index`,
- | `boot_count`,
- | `part_number`,
- | `commit`,
- | `source`,
- | `time_zone`,
- | `timestamp`,
- | `process`,
- | `pid`,
- | `level`,
- | `text`,
- | `adc_version`,
- | `baseline`,
- | `model_type`,
- | `create_time`,
- | `utc_timestamp`,
- | `line_number`,
- | `country`,
- | `local_timezone`,
- | `update_time`,
- | `category`,
- | `pt`
- |FROM $table2Sink
- |""".stripMargin))
- }
测试类
- import com.xxx.ocha.infra.config.configLoaderImpl.ApolloConfigLoader
- import com.xxx.ocha.infra.flink.ExecEnvUtil.Implicits._
- import org.apache.flink.api.scala.createTypeInformation
- import org.junit.Test
-
- import java.util.Properties
-
- class ExecEnvUtilTest {
-
- {
- val prop = new Properties()
- prop.setProperty("env", "dev")
- prop.setProperty("cluster", "test")
- ApolloConfigLoader.getWithInit(prop)
- }
- @Test def testTableEnv(): Unit = {
- val env = ExecEnvUtil.getExecEnv("dev")
- val tableEnv1 = env.tblEnv()
- val tableEnv2 = env.tblEnv()
- println(tableEnv1 == tableEnv2)
- }
-
- @Test def testGetExecEnv(): Unit = {
- val env = ExecEnvUtil.getExecEnv("dev")
- val env2 = ExecEnvUtil.getExecEnv("dev")
- assert(env == env2)
- val tblEnv = env.tblEnv()
- val tblEnv2 = env.tblEnv()
- assert(tblEnv == tblEnv2)
- env.enableIceberg("dev")
- tblEnv.executeSql("drop table if exists `iceberg_catalog`.`unit_test_db`.`unit_test_tbl`")
- tblEnv.executeSql("create table if not exists `iceberg_catalog`.`unit_test_db`.`unit_test_tbl` (a BIGINT)")
- val stream1 = env.fromCollection(Seq(ARow(1), ARow(2), ARow(3)))
- val table1 = tblEnv.fromDataStream(stream1)
- table1.executeInsert("`iceberg_catalog`.`unit_test_db`.`unit_test_tbl`")
- val table2 = tblEnv.sqlQuery("select * from `iceberg_catalog`.`unit_test_db`.`unit_test_tbl`")
- table2.execute().print()
- }
- }
-
-
- case class ARow(a: Long)
参考文章
大数据时代,数据湖技术Apache Iceberg的前世今生
数据湖09:开源框架DeltaLake、Hudi、Iceberg深度对比_YoungerChina的博客-CSDN博客_开源数据湖

