
output怎么用_用BERT做情感分析
赞
踩
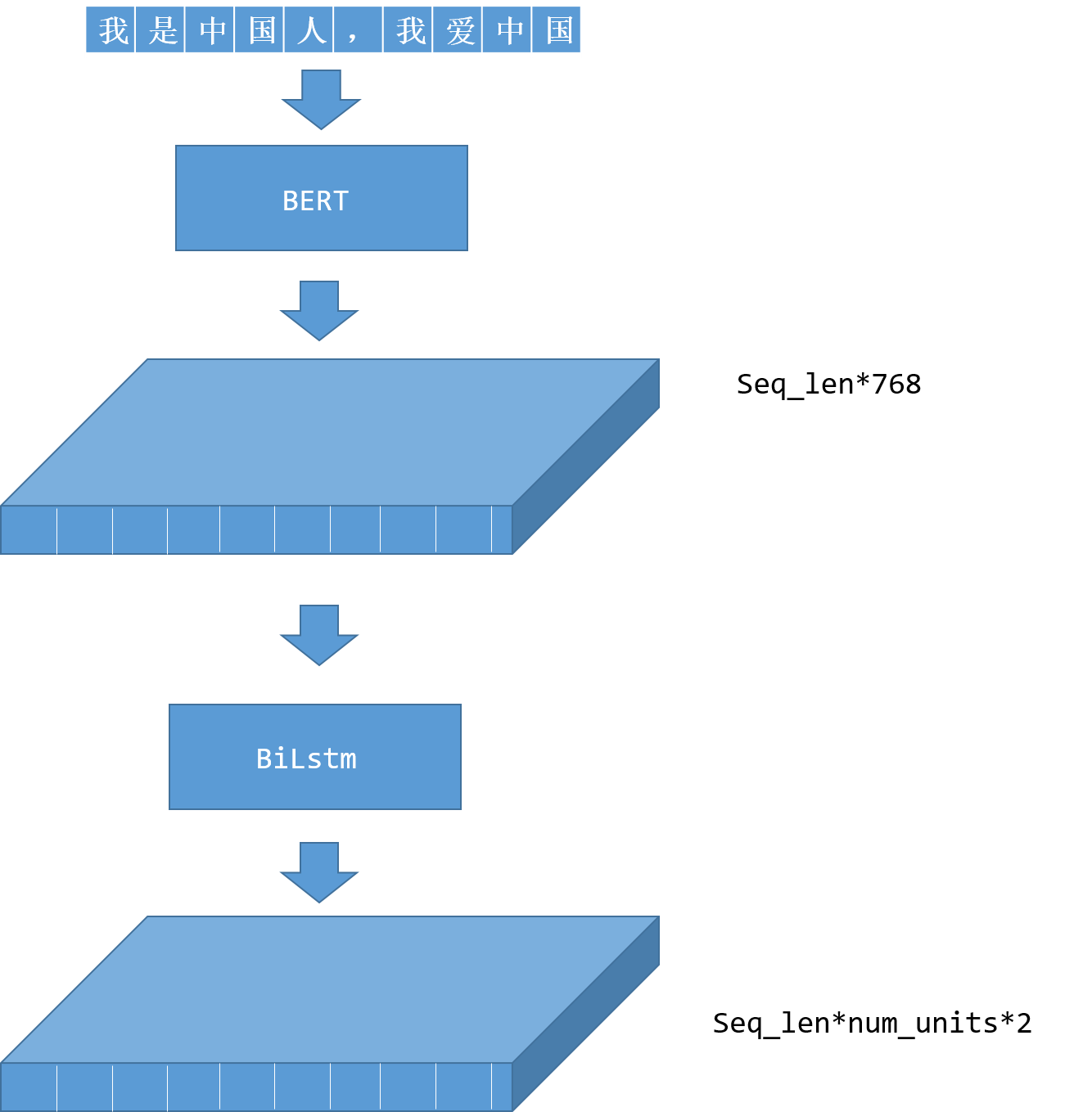
诸如情感分析一类的任务比如商品评价正负面分析,敏感内容分析,用户感兴趣内容分析、甚至安全领域的异常访问日志分析等等实际上都可以用文本分类的方式去做,本质上来讲就是一个文本输出一个多个对应的标签。
这一类任务BERT原文中用的是斯坦福的treebank,在这里我们还是用双向的LSTM网络来实现,因为前面的实体标注的内容中使用的是双向LSTM加CRF,稍加改造就可以很轻松的解决文本分类任务。
一、计算过程
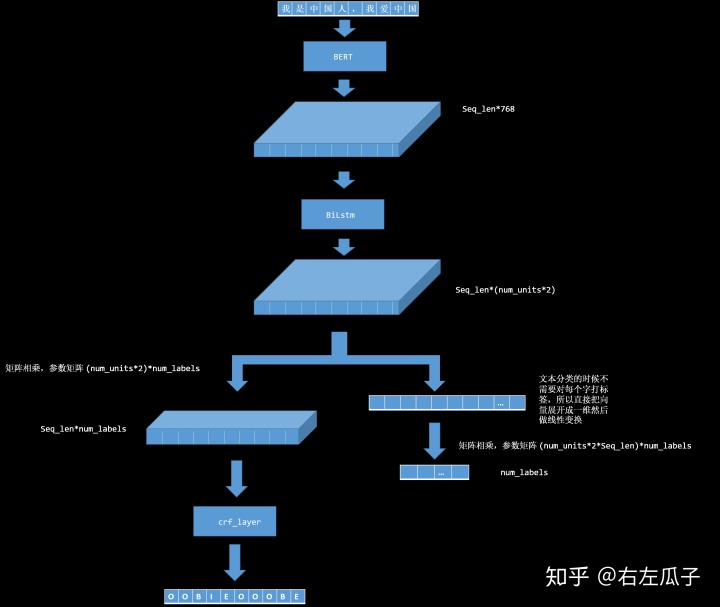
整个前向传播计算过程如上图所示,和实体识别的程序做了对比,方便看出来如何在实体识别程序的基础上做简单的修改让程序可以处理文本分类的问题。BERT部分和 biLstm部分都没有变化,关键的地方在于BiLstm的输出结果,因为文本分类只需要相对于整句的标签,所以直接把结果展开然后做线性变化,实际上也可以在线性变化上再加一层激活层但是只要你能保证前向传播和后向传播可以顺利进行,得到的结果是一个可以转化为标签的结果,而不是连你自己也不知道是什么东西的结果即可。不过实验证明并没有什么提升,前面的网络已经足够了。
二、代码
代码上在前面一节的代码的基础上做一些修改,主要是`Bilstm`网络输出的处理以及新的损失函数。
- output = tf.transpose(output, perm=[1, 0, 2])
- tf.logging.info(output.shape)
- output = tf.layers.dropout(output, rate=0.5, training=is_training)
- output = tf.reshape(output, [-1, 128*256])
- output_weights = tf.get_variable(
- "output_weights", [num_labels, 128*256],
- initializer=tf.truncated_normal_initializer(stddev=0.02))
-
- output_bias = tf.get_variable(
- "output_bias", [num_labels], initializer=tf.zeros_initializer())
- logits = tf.matmul(output, output_weights, transpose_b=True)
- logits = tf.nn.bias_add(logits, output_bias)
- tf.logging.info("*****shape of label_ids******")
- tf.logging.info(label_ids.shape)
- tf.logging.info(logits.shape)
-
- correctPred = tf.equal(tf.argmax(logits,1), tf.argmax(label_ids,1)) # tf.argmax: Returns the index with the largest value across axes of a tensor.
- accuracy = tf.reduce_mean(tf.cast(correctPred, tf.float32))
- tf.summary.scalar('Accuracy', accuracy)
- loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=label_ids))

有一点需要注意的是tf.argmax()函数,我们之前取标签使用的是tensorflow自带的crf的方法,它可以直接输出标签,但是在这里没有crf所以我们要自己把对应的标签取出来,也就是把最后输出的长度为num_len的向量中值最大的索引找出来,这个索引对应的就是标签的索引。当然,除了计算过程改变了之外,前面的输入数据格式整理也是必需的这里就不再赘述,主要是把一个句子对应的多标签改成单个标签,完整代码在这里

上一节提到了estimator但是发出来之后会看发现并没有介绍这一块,所以这里补一点。estimator主要是为了方便开发者之关系算法构建的核心部分,把其他的事情交给tensorflow来处理。使用estimator我们只需要写好前期输入数据整理的程序inpu_fn 和模型的计算过程model_fn,摘出上面代码中的片段看一看
- estimator = tf.contrib.tpu.TPUEstimator(
- use_tpu=False,
- model_fn=model_fn,
- config=run_config,
- train_batch_size=FLAGS.train_batch_size,
- eval_batch_size=FLAGS.eval_batch_size,
- predict_batch_size=FLAGS.predict_batch_size,
- params=params)
这是estimator的构造方法,因为谷歌给出的bert的例子中使用了TPU训练,所以这里构建了一个TPU的estimator实际计算的时候如果没有TPU会自动转化为一般的estimator,model_fn方法定义了计算过程 ,其他的参数比较好理解就不多说了,最后一个param参数比较特殊,当model_fn中需要的参数 estimator 的方法签名中没有的时候使用,estimator会把这个参数传递给model_fn,注意到这里没有input_fn,因为这里只是在构建计算过程,并没有真正开始训练,tensorflow在训练之前会先构建好计算图,整个计算图前向传播和后向传播能跑通才会输入数据进行计算。
- train_input_fn = file_based_input_fn_builder(
- input_file=train_file,
- seq_length=FLAGS.max_seq_length,
- is_training=True,
- drop_remainder=True)
- eval_input_fn = file_based_input_fn_builder(
- input_file=eval_file,
- seq_length=FLAGS.max_seq_length,
- is_training=True,
- drop_remainder=True)
- # estimator.train(input_fn=train_input_fn, max_steps=num_train_steps)
- hook = tf.contrib.estimator.stop_if_no_increase_hook(
- estimator, 'loss', 100000, min_steps=50000, run_every_secs=300)
- train_spec = tf.estimator.TrainSpec(input_fn=train_input_fn, hooks=[hook])
- eval_spec = tf.estimator.EvalSpec(input_fn=eval_input_fn, throttle_secs=300)
- tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
estimator构建好之后就可以跑起来训练了,这些方法看方法名基本上都能知道是干嘛的了,有一个要注意的是hook,hook可以看作一个管理训练过程的工具,比如说这里就是设置提前终止的条件,变量loss在100000步以内没有下降即终止,实际上更广泛的用法是用在对测试集的f1值上,有兴趣可以尝试一下。
我们花了一些功夫学习estimator除了自动化管理训练过程之外还有一点就是方便使用tensorflowserver部署接口,在使用estimator之前我们把训练好的算法部署到网络端口还是很麻烦的,有多麻烦呢?麻烦到我之前都懒得折腾他直接用flask写了个接口调用算法。我们看看怎么用estimator部署,首先导出模型。
- estimator = tf.contrib.tpu.TPUEstimator(
- use_tpu=False,
- model_fn=model_fn,
- config=run_config,
- train_batch_size=32,
- eval_batch_size=32,
- predict_batch_size=32,
- params=params)
- estimator._export_to_tpu = False
- estimator.export_savedmodel('senta', serving_input_receiver_fn)
把之前的estimator 再构造一遍,然后调用方法就可以了,因为在网络端的输入数据和训练时的数据输入方式不同,所以我们还要给他加一个定制的输入方程,定义了如何解析通过接口传入的数据,即serving_input_receiver_fn
- def serving_input_receiver_fn():
- """Serving input_fn that builds features from placeholders
- Returns
- -------
- tf.estimator.export.ServingInputReceiver
- """
- # feature = InputFeatures(
- # input_ids=input_ids,
- # input_mask=input_mask,
- # segment_ids=segment_ids,
- # label_ids=label_id,
- # seq_length = seq_length,
- # is_real_example=True)
-
- input_ids = tf.placeholder(dtype=tf.int32, shape=[None, None], name='input_ids')
- input_mask = tf.placeholder(dtype=tf.int32, shape=[None, None], name='input_mask')
- segment_ids = tf.placeholder(dtype=tf.int32, shape=[None, None], name='segment_ids')
- label_ids = tf.placeholder(dtype=tf.int32, shape=[None], name='label_ids')
- seq_length = tf.placeholder(dtype=tf.int32, shape=[None], name='seq_length')
- is_real_example = tf.placeholder(dtype=tf.string, shape=[None], name='is_real_example')
- receiver_tensors = {'input_ids': input_ids,
- 'input_mask': input_mask,
- 'segment_ids': segment_ids,
- 'label_ids':label_ids,
- 'seq_length':seq_length,
- 'is_real_example':is_real_example}
- features = {'input_ids': input_ids,
- 'input_mask': input_mask,
- 'segment_ids': segment_ids,
- 'label_ids':label_ids,
- 'seq_length':seq_length,
- 'is_real_example':is_real_example}
- return tf.estimator.export.ServingInputReceiver(features, receiver_tensors)
就这么多,然后调用脚本部署就可以了,github链接中有,都是死东西这里不再赘述。部署好之后有grpc的接口也有rest的接口,链接中的client.py展示了如何调用rest接口。源码中给的export.py依旧是实体识别的,如果要导出情感分析的可以自行修改,也比较简单。
三、文本分类处理的一些方法
文本分类的问题最大的难点应该还是样本的问题,分词和实体词识别一般都能找到公开的比较好的样本,二文本分类问题却不一样,文本分类问题往往是特定领域的针对特定问题的分类,如果是在有钱的大公司还好,出点儿钱,请点儿人标注一批,但是大部分情况都需要工程师和相关领域的专业人员去找样本。记得阿里巴巴在一篇文章提到协助法院处理法律文件的时候也是领域人员和工程师一起去通过各种方式找样本。废话不多说了,找样本一般有三个思路:1.关键词匹配,跟一些同行聊到这些的时候有种感觉就是大部分人都觉得关键词匹配很丢人,这不是做算法的人该干的事儿,实际上,丢人不?丢人!想不想要钱?想!那丢人也得干。通过强特征关键词匹配的样本应该是质量比较高的样本,我们用关键词匹配样本的关键在于算法不仅能学习到关键词信息,而且也能学到关键词以外的语法上的信息,来达到优于直接关键词提取的效果。2.规则匹配,这里的规则匹配不同于关键词匹配,泛指一切能把文本分类的规则,比如再twitter打击假新闻的任务中,所有已知机器人的twitter信息和账号信息都可以作为一个分类的样本,同样的,确认的真实人物或者机构发表的新闻和信息都可以作为另一个分类的样本。3.自然语言生成:一前这种方法只是一种理论上存在的方法,因为一前自然语言生成技术得出的结果比较辣眼睛,但是现在随着新技术一茬接一茬,上一个月BERT刚打败OPENAI-GPT还大红大紫,这个月OPENAI-GPT2就又重新找回了场子,有一个好的语言模型,自然语言生成的结果也应该会有很大提升,所以这一块也能起到一部分帮助。

