
- 1CentOS7虚拟机中使用kolla-ansible部署all-in-one模式openstack详细步骤_openstack all in one
- 21.12 实例:猜数字小游戏_verilog猜数字游戏
- 3深度学习如何入门?_深度学习 入门
- 4python calendar模块常用方法_python calendar用法
- 5LeetCode:419. 甲板上的战舰————中等_甲板上的战舰 js
- 6python中的sorted怎么用_python sorted方法和列表使用解析
- 7MySQL知识总结一(MySQL常见术语)_mysql 术语解释
- 8FPGA 20个例程篇:20.USB2.0/RS232/LAN控制并行DAC输出任意频率正弦波、梯形波、三角波、方波(一)_用verilog控制dac产生波形
- 9新版onenet平台安全鉴权的确定与使用_新版onenet没有鉴权_onenet新版本的设备的鉴权信息是什么
- 10ARP解析_arp报文
第6讲:隐语PIR介绍及开发实践_pir 隐私信息检索
赞
踩
1.PIR定义
隐私信息检索(Private information retrieval, PIR)是对信息检索(information retrieval, IR)的一种扩展,最早在[CKGS95]中提出,用于保护用户查询信息,防止数据持有方得到用户的检索条件。
PIR协议目标可以定义为:Alice有共
N
N
N行的数据库D,每一行的数据大小为
L
L
L。Bob希望查询获得其中指定位置的某一行,但是不想告诉Alice自己查询的是哪一行。
隐私信息检索协议(PIR)需要满足正确性和安全性两方面的要求:
- 正确性:用户得到要查询的数据
- 安全性:服务端 无法知道 用户查询的是哪条数
PIR按服务器数量可以分类为单服务器(Single Server)和多服务器(Multi-Server)方案,按查询类型可以分为Index PIR和Keyword PIR。
2.隐语实现PIR情况
隐语目前支持的PIR有:
- Single Server Index PIR: SealPIR
- Single Server Keyword PIR: Labeled PSI
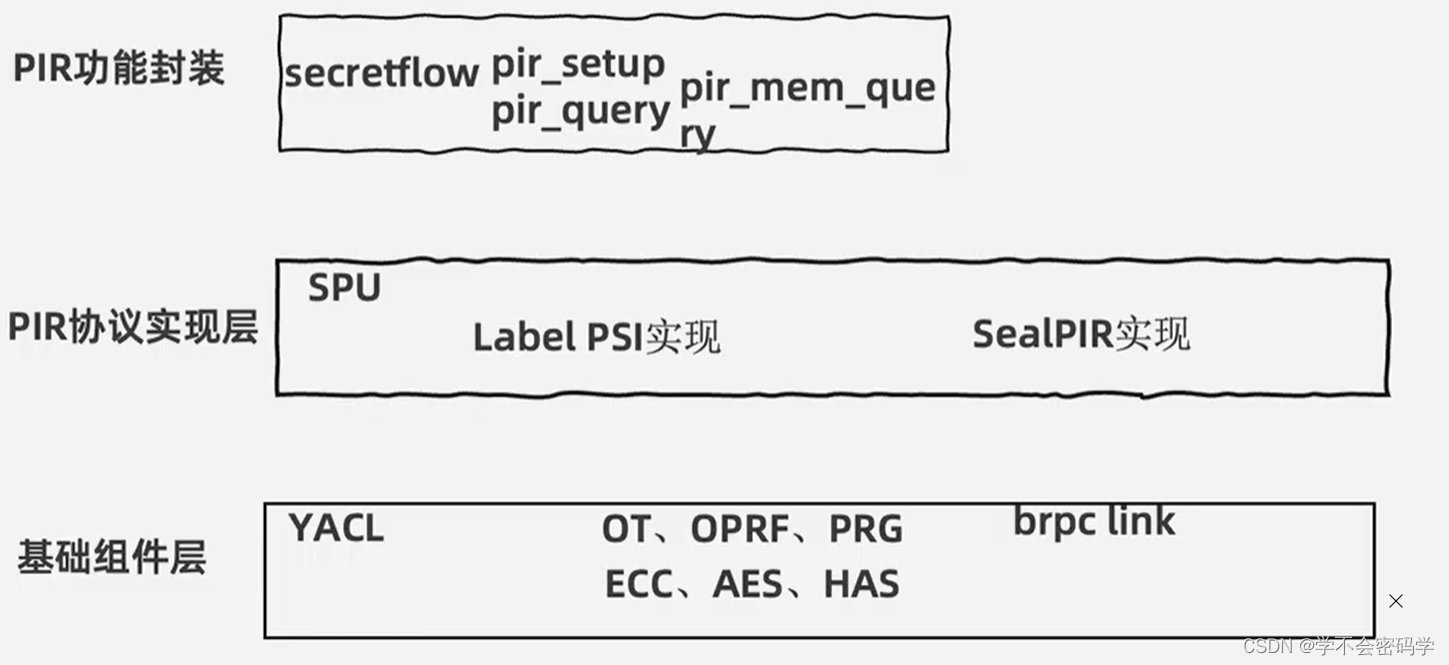
2.1 spu pir api
pir_setup(
key_columns (str, List[str]) – Column(s) used as pir key
label_columns (str, List[str]) – Column(s) used as pir label
oprf_key_path (str) – Ecc oprf secret key path, 32B binary format. Use an absolute path.
setup_path (str) – Offline/Setup phase output data dir. Use an absolute path.
num_per_query (int) – Items number per query.
label_max_len (int) – Max number bytes of label, padding data to label_max_len Max label bytes length add 4 bytes(len).
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
pir_query(server: str, config: Dict, protocol='KEYWORD_PIR_LABELED_PSI')
{
# client config
alice: {
'input_path': '/path/intput.csv',
'key_columns': 'id',
'output_path': '/path/output.csv',
},
# server config
bob: {
'oprf_key_path': '/path/oprf_key.bin',
'setup_path': '/path/setup_dir',
},
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
pir_memory_query(server: str, config: Dict, protocol='KEYWORD_PIR_LABELED_PSI') { # client config alice: { 'input_path': '/path/intput.csv', 'key_columns': 'id', 'output_path': '/path/output.csv', }, # server config bob: { 'input_path': '/path/server.csv', 'key_columns': 'id', 'label_columns': 'label', 'num_per_query': '1', 'label_max_len': '20', }, }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.2 Index PIR-SealPIR 介绍
BFV SHE方案定义在固定多项式环 R = Z / ( x n + 1 ) R=\mathbb{Z}/(x^{n}+1) R=Z/(xn+1)上,明文是 R t = Z t / ( x n + 1 ) R_t=\mathbb{Z_t}/(x^n+1) Rt=Zt/(xn+1)中的多项式即: a 0 + a 1 x + ⋯ + a n − 1 x n − 1 + a n − 1 x n − 1 a_0+a_1x+\dots + a_{n-1}x^{n-1}+a_{n-1}x^{n-1} a0+a1x+⋯+an−1xn−1+an−1xn−1
- 多项式次数: n n n
- 明文系数模: t t t,素数
- 密文系数模: q q q,若干素数的乘积
在BFV SHE方案中,密钥
s
s
s是一个从二项多项式(系数为0或1)采样的多项式。密文包括两个来自环
R
q
=
Z
q
(
x
n
+
1
)
R_q=Z_q(x^n+1)
Rq=Zq(xn+1)的多项式,
(
c
0
,
c
1
)
=
(
a
,
b
+
e
+
m
)
(c_0,c_1)=(a,b+e+m)
(c0,c1)=(a,b+e+m),其中
a
a
a是从
R
q
R_q
Rq中均匀采样的,
b
=
a
⋅
s
+
e
b=a\cdot s+e
b=a⋅s+e,
e
e
e是一个表示噪声的多项式,它的系数是从有界高斯分布里采样出来的。可以通过计算
u
=
c
1
−
c
0
⋅
s
=
e
+
m
u=c_1-c_0\cdot s=e+m
u=c1−c0⋅s=e+m来解密,
e
e
e是很小的噪声,这样就可以恢复出原文
m
m
m。
密文扩展因子
F
F
F:密文大小与明文大小之间的比率:
F
=
2
l
o
g
q
l
o
g
t
F=\frac{2logq}{logt}
F=logt2logq
SHE的同态运算会引起噪声的增长,当噪声超过一定限制时,无法解密得到明文,所以要适当选择SHE算法的参数,及控制同态运算的噪声增长。
密文是一对模
q
q
q的多项式,而明文是模
t
t
t的多项式。密文扩展因子直接影响PIR的响应大小。PIR的主要任务之一就是减少
F
F
F。
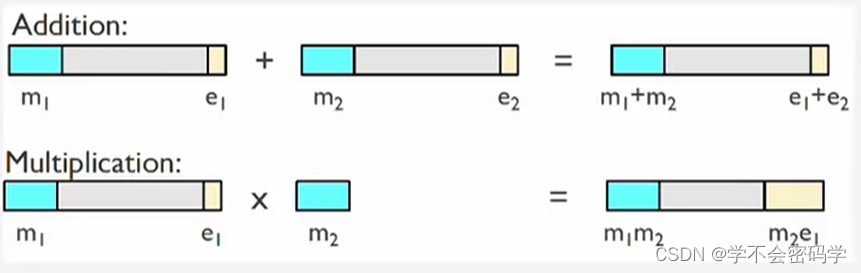

BFV方案中,执行密文乘法运算时噪声增长很快,因此要避免使用密文乘法操作。
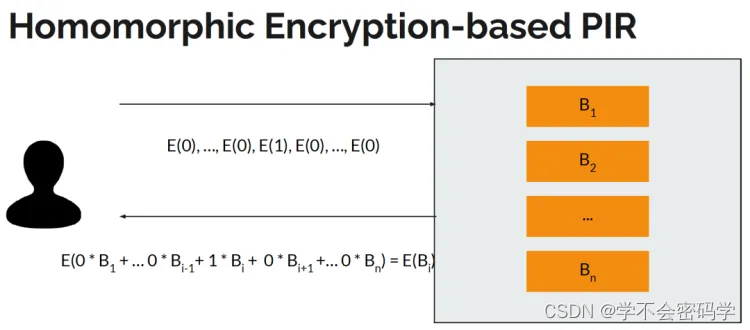
HE-Based PIR的原理就是将查询向量使用HE加密后发送给服务端,服务端使用该加密向量与服务器数据做内积运算并返回带查询数据的加密结果给客户端,最后由客户端解密返回结果获取PIR结果。
请求消息报文太大,包含n个密文向量。
2.2.1 SealPIR的主要贡献

将多个数据pack到一个HE明文
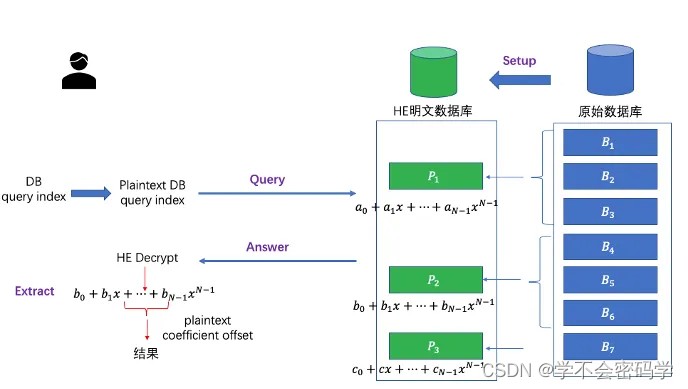
假设数据库中数据长度为
288
288
288字节(SealPIR论文中给出的长度),BFV参数选择:多项式次数
8192
8192
8192,明文模
16
16
16bit,举例说明一下packing的效果:
- 数据库中每条数据,需要HE明文多项式中 C e i l ( 288 × 8 / 16 ) = 144 Ceil(288 \times 8 / 16) = 144 Ceil(288×8/16)=144个系数来表示。
- HE一个明文多项式可以包含 F l o o r ( 8192 / 144 ) = 56 Floor(8192 / 144) = 56 Floor(8192/144)=56条数据库数据。
- 对数据库的查询 d b i d x db_{idx} dbidx,需要转换为明文的查询 p l a i n i n d e x = d b i d x / 56 plain_{index} = db_{idx} / 56 plainindex=dbidx/56。
- 用户得到查询响应密文,通过私钥进行解密,得到HE明文,将HE明文对应的系数进行组合,得到真正查询的数据。
将查询向量压缩为一个密文
为了显著减少通信量,SealPIR方案在服务端添加一个额外的Expand操作得到查询密文向量。查询向量
(
0
,
…
,
0
,
1
,
0
,
…
,
0
)
(0, \ldots, 0, 1, 0, \ldots, 0)
(0,…,0,1,0,…,0) 压缩到一个HE明文多项式为例,查询向量中的每个分量对应为HE明文多项式中的系数。
a
0
+
a
1
x
+
⋯
+
a
N
−
2
x
N
−
2
+
a
N
−
1
x
N
−
1
=
E
(
x
query
index
)
a_0 + a_{1^x} + \cdots + a_{{N-2}^{x^{N-2}}} + a_{{N-1}^{x^{N-1}}} = E(x^{\text{query}_{\text{index}}})
a0+a1x+⋯+aN−2xN−2+aN−1xN−1=E(xqueryindex)其中:
a
i
=
0
,
if
i
≠
q
u
e
r
y
i
n
d
e
x
,
a_i = 0, \quad \text{if } i \neq query_{index},
ai=0,if i=queryindex,
a
i
=
1
,
if
i
=
q
u
e
r
y
i
n
d
e
x
a_i = 1, \quad \text{if } i = query_{index}
ai=1,if i=queryindex
对查询明文进行加密,得到
E
(
a
0
+
a
1
x
+
…
+
a
N
−
2
x
N
−
2
+
a
N
−
1
x
N
−
1
)
=
E
(
x
query
index
)
E\left(a_0 + a_{1^x} + \ldots + a_{{N-2}^{x^{N-2}}} + a_{{N-1}^{x^{N-1}}}\right) = E(x^{\text{query}_{\text{index}}})
E(a0+a1x+…+aN−2xN−2+aN−1xN−1)=E(xqueryindex)
服务端接收到查询密文后,执行Expand算法,得到查询密文向量:
(
E
(
0
)
,
…
,
E
(
0
)
,
E
(
1
)
,
E
(
0
)
,
…
,
E
(
0
)
)
(E(0), \ldots, E(0), E(1), E(0), \ldots, E(0))
(E(0),…,E(0),E(1),E(0),…,E(0))
还是以上面packing的参数举例,每个HE明文可以pack
56
56
56条数据库数据,客户端查询时,将
d
b
i
d
x
db_{idx}
dbidx转换为
p
l
a
i
n
i
n
d
e
x
plain_{index}
plainindex,即对HE明文数据库进行查询,最多可以查询
8192
8192
8192个HE明文,转换成数据库数据,最多可以查询
8192
×
56
=
458
,
752
8192 \times 56 = 458,752
8192×56=458,752条数据,不能满足实际业务中的需求。
为了满足实际将查询向量压缩到多个HE明文来表示查询向量,对于百万数据来讲,需要
c
e
i
l
(
1000000
/
8192
)
=
123
ceil(1000000/8192)=123
ceil(1000000/8192)=123个HE明文,对应
123
123
123个HE密文,才能表示百万数据的查询向量。为了进一步压缩查询密文的数量,可以使用下面的多维表示方法。
Expand算法的详细描述和证明可以参考[SealPIR]论文中的内容。
将数据库一维向量转换为多维向量
查询时将数据库表示为
n
∗
n
\sqrt{n}\ast \sqrt{n}
n
∗n
的二维矩阵,减少查询向量的长度。
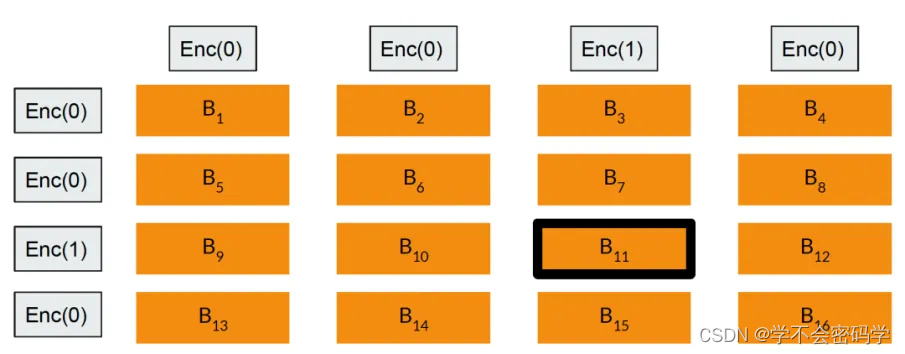
以上面packing的参数为例,将数据库表示为
2
2
2维数据时,通过两个查询密文可以查询的数据量是
8192
×
8192
×
56
≈
37
8192 \times 8192 \times 56 \approx 37
8192×8192×56≈37亿,已经能满足绝大多数的数据库查询任务。数据库数据量为
n
n
n,通过packing后得到HE明文数量为
n
′
n'
n′,
F
F
F是密文扩张因子,二维查询流程如下:
服务端:
- 将HE明文表示为 n ′ × n ′ \sqrt{n'} \times \sqrt{n'} n′ ×n′ 的矩阵 M M M,其中 n ′ < 8192 \sqrt{n'} < 8192 n′ <8192。
- V c V_c Vc是密文查询列向量, A c = M ⋅ V c A_c = M \cdot V_c Ac=M⋅Vc,其中 A c A_c Ac是 n ′ × 1 \sqrt{n'} \times 1 n′ ×1的密文列向量。
- 将 A c A_c Ac中每个密文拆分为 F F F份明文多项式,得到 n ′ × F \sqrt{n'} \times F n′ ×F矩阵 A S c A_{S_c} ASc。
- V r V_r Vr是密文查询行向量, A S c T ⋅ V r A_{S_c}^T \cdot V_r AScT⋅Vr,得到维度为 F × 1 F \times 1 F×1的密文向量。
客户端:
- 客户端收到
F
F
F个密文向量,使用私钥
s
k
sk
sk解密,将其组合成密文
E
n
c
(
M
[
r
,
c
]
)
Enc(M[r,c])
Enc(M[r,c]),使用私钥
s
k
sk
sk解密
E
n
c
(
M
[
r
,
c
]
)
Enc(M[r,c])
Enc(M[r,c])得到真正的查询HE明文
M
[
r
,
c
]
M[r,c]
M[r,c],对HE明文
M
[
r
,
c
]
M[r,c]
M[r,c]中对应的系数进行组合,得到真正查询的数据。
服务端为了避免进行密文乘以密文的同态运算,第3步中将密文拆解成 F F F个明文进行操作,最后服务端发给客户端的查询响应是 F F F个密文,在多项式次数 8192 8192 8192时, F ≈ 26 F \approx 26 F≈26,因此,服务端发给客户端的查询响应消息太大,这也是SealPIR主要的问题,后续的文章,主要目标是减少查询响应消息。
支持多查询

2.2.2 Keyword PIR-Label PSI介绍
基本原理:点值表示得到插值多项式系数表示。
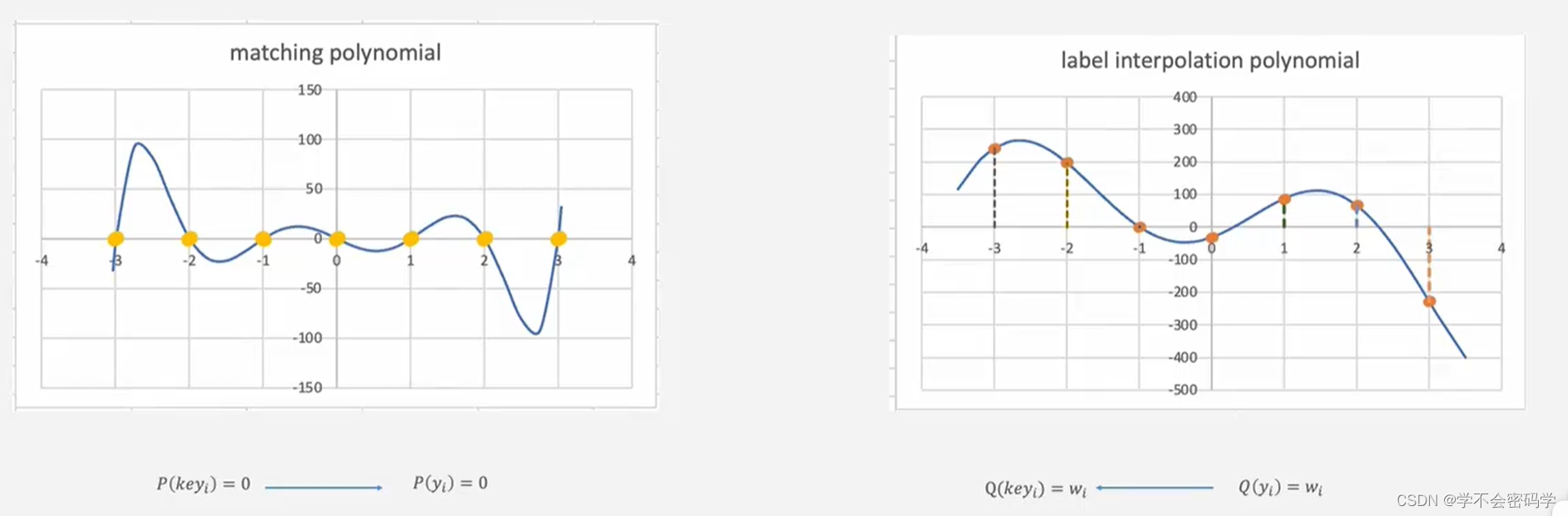
客户端可以通过窗口技术,服务端采用分区技术减少乘法计算次数。

使用extremak postage stamp bass 减少通信开销
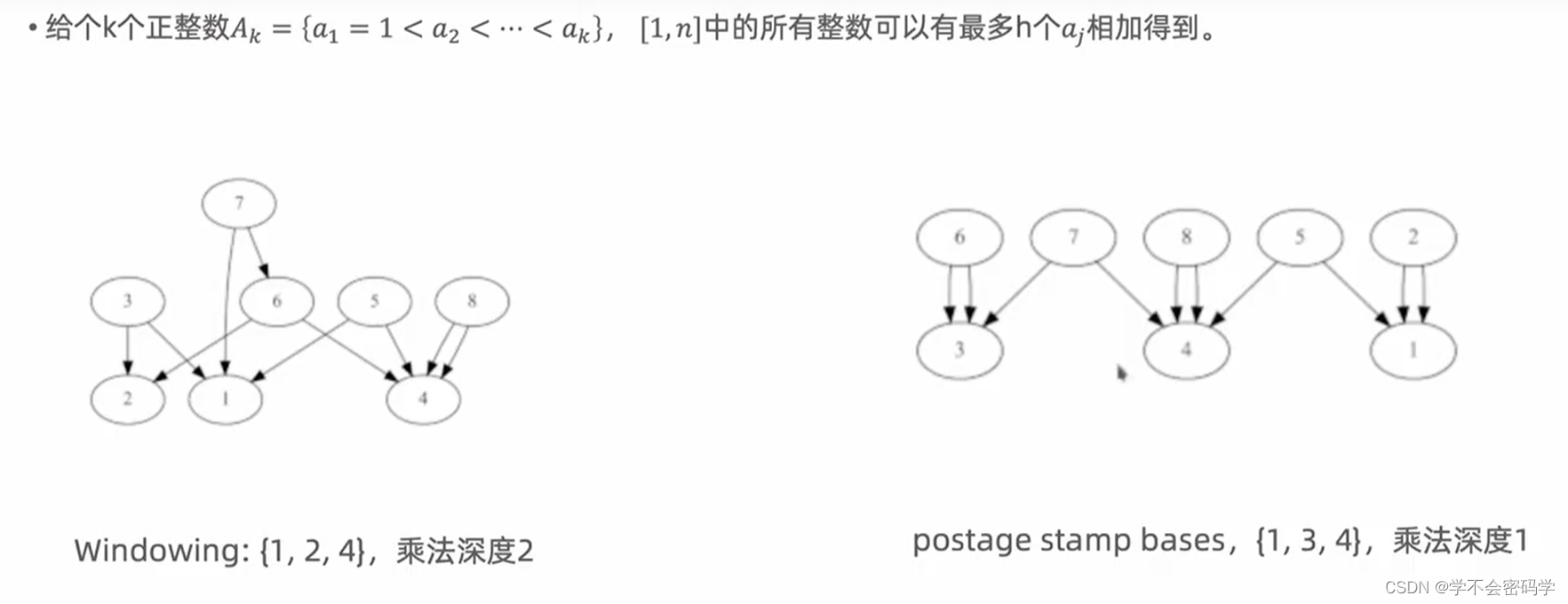
Paterson-Stockmeyer 算法减少密文乘法
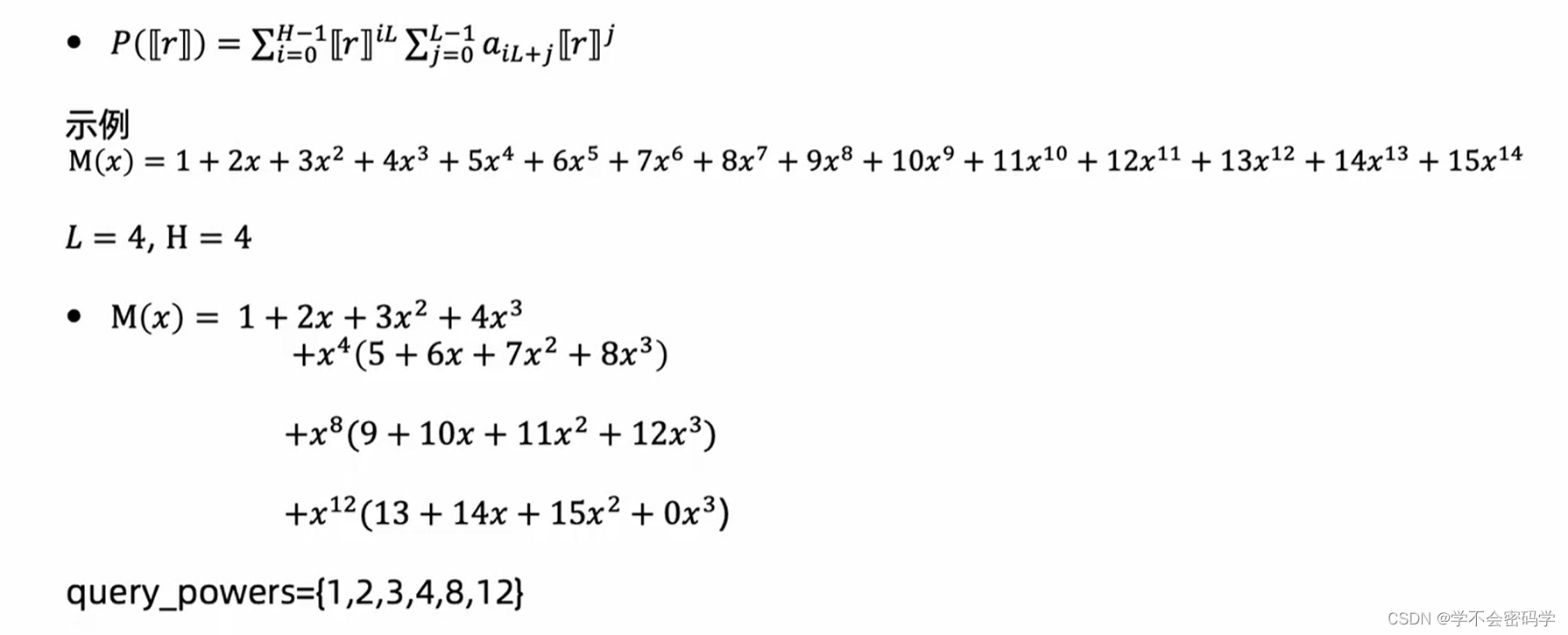
隐语Label PSI 主要工作
- 以微软开源代码功能为核心
- OPRF采用隐语的实现
- 支持的ecc曲线包括:FourQ、Secp256k1、SM2
- Label的自动填充
- 增加了服务的预处理结果保存功能
- 可以至此离线和查询(多次)两个阶段
setup阶段
- 选择参数。
- 对id数据进行PRF计算,前128bit根据截取用于匹配,后128bit作为对称算法密钥加密label。
- 根据PRF前128bit将数据插入Simple Hash。
- 对Simple Hash 每一行分别划分bin bundle,并计算matching polynomial 和label polynomial。
- 将插值多项式系数packing到同态算法明文。
Query 阶段
- 请求参数。
- 执行OPRF。
- 计算查询值得同态密文幂集合。
- 使用同态私钥解密服务端返回的同态密文。
- 满足匹配条件时,使用OPRF的后128bit解密得到label。

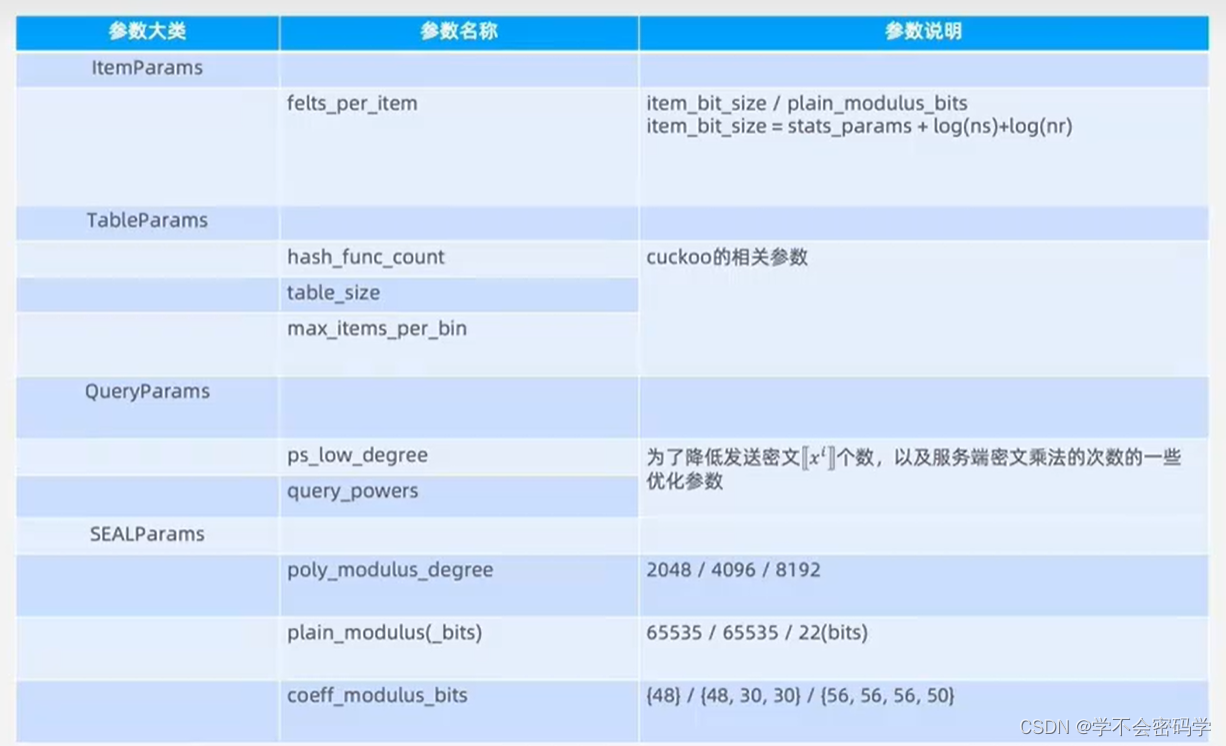
隐语Label PSI的主要参数
3.隐语PIR后续计划

- 1.JDBC连接Mysql5
mysql [详细] 赞
踩



