
- 1*** Please tell me who you are.Run git config --global user.email “you@example.com“ git confi_*** please tell me who you are. run git config --g
- 2Kafka部署与SpringBoot集成_spring boot 集成kafka poll
- 3MySQL学习Day19——索引的数据结构
- 4Hadoop的三大核心组件_hadoop三大组件
- 5Mac 之 Nginx 安装_mac查看nginx安装目录
- 6Hadoop集群---方便的脚本_myhadoop.sh 命令
- 7代码设计的基础原则_设计原则:良好设计的基础
- 8学习《apache源代码全景分析》之模块化体系结构摘录_apache模块化体系结构
- 9MySQL从入门到入魔(01)_可同时备份mydb1数据库和mydb2数据库的语句是
- 10MambaOut: Do We Really Need Mamba for Vision?
基于Intel AI 工具实现深度学习的自然灾害遥感影像语义分割_fcn遥感影像分割
赞
踩
方案介绍
近年来极端天气事件频发,如干旱、洪涝和高温等,这些都会对农作物的生长产生不利影响。AI可以通过大数据分析和预测天气变化,帮助农民制定更加科学的种植计划,选择适应气候变化的农作物品种,预防病虫害以及优化灌溉和施肥策略。
借助此次黑客松大赛,我们计划使用intel one AI工具包,开发一个AI农业防灾预测系统。为农户提供科学、稳定的预测指导。实现将可能出现的灾情提前上报,防患于未然。
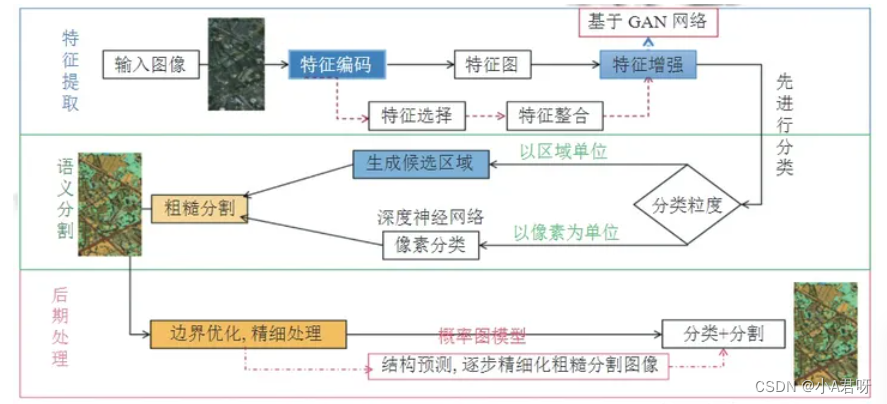
基于Intel 工具包生成对抗网络的3层遥感影像语义信息分割模型,通过改进PSPNet网络模型和PSPNet、DeepLab 等网络进行对比,在多层网络模型使用空洞卷积扩大感受野,通常采用编码-解码模型。
PSPNet(Pyramid Scene Parsing Network)简介
PSPNet(Pyramid Scene Parsing Network)是一种用于图像语义分割的深度卷积神经网络模型。
PSPNet的核心思想是利用金字塔池化模块来捕捉不同尺度上的上下文信息,以提高对图像语义的理解和分割准确性。
该模型的主要特点包括:
1.金字塔池化模块(Pyramid Pooling Module):该模块通过在不同尺度上进行池化操作,从不同层次上捕捉图像的全局和局部上下文信息。它能够有效地扩展感受野,使网络能够对不同尺度的对象和场景进行细粒度的分割。
2.ResNet作为主干网络:PSPNet通常使用ResNet作为主干网络,以提取图像特征。
3.融合和上采样:在池化模块之后,PSPNet通过级联融合和上采样操作,将来自不同尺度的特征图进行融合,并将其上采样到原始图像的尺寸。融合后的特征图可以更准确地表示图像中的不同语义区域。
全卷积神经网络(FCN)
现在大多数的语义分割都还是依赖CNN,但是 CNN 对局部接收的卷积会影响语境空间关系的建模;本文使用FCN的方法可以改善CNN对卷积的影响。
FCN 能够输入不同大小的图像。 通过反卷积方法对最后卷积的特征图进行上取样,得到各像素的预测,同时保持其原始图像的空间信息。 然后将上取样的特征图像素进行归类。 FCN 网络主要通过卷积神经网络对图像的强大能力,采用全卷积的方法,利用卷积层代替现有的语义分割深度网络模型。
空洞卷积
空洞卷积的感受野的大小可以用式(1) 表示:
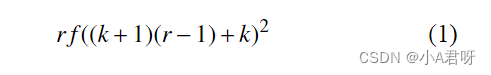
r 设置为"膨胀率", 即孔卷积的步长, 代表输入信号的采样间隔. 当 r = 1 时, 空卷积是标准卷积. 在孔 卷积中, 卷积核以"膨胀率"进行扩展, 在空间维度在相 邻的权系数之间插入 r−1 个零,创建稀疏滤波器
FCN遥感影像分类,数据解析
vgg预训练的网络结构
pretrained_net = models.vgg16_bn(pretrained=False)
pretrained_net.features[:7]
- 1
- 2
这里我们主要实现FCN 最后一层接softmax并预测 ,FCN 最后一层输出尺寸 eg: 1344 ===>即 1张 3通道的 44特征图
我们希望通过,FCN网格得到的预测分数图,变为一张可视化的图片,即网络的预测的最终结果。
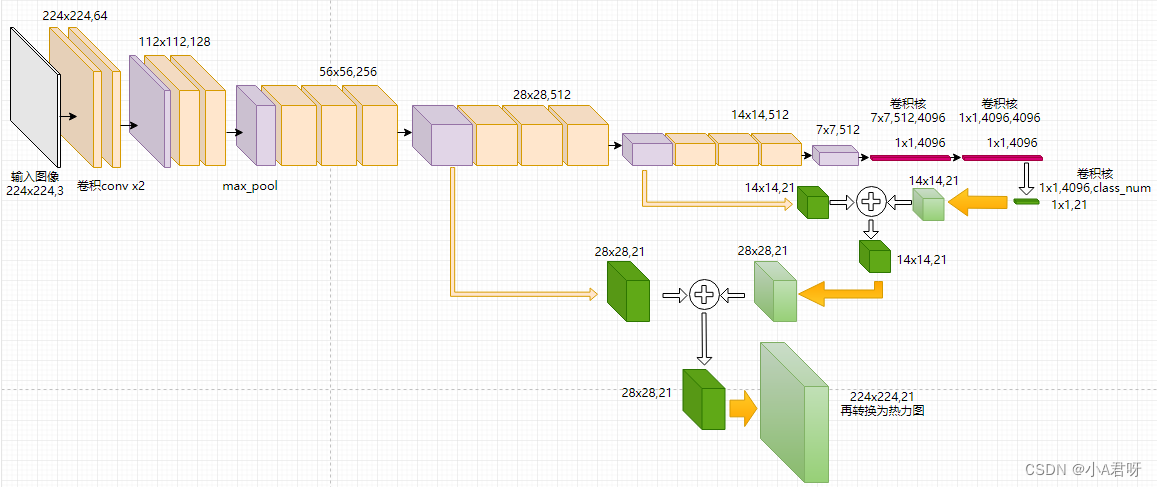
1.FCN8s 网络结构代码实现
CrossEntropyLoss和NLLLoss都是用于多分类问题的损失函数,它们都基于softmax函数。
CrossEntropyLoss:这个损失函数结合了softmax和NLLLoss。在计算CrossEntropyLoss之前,模型会先通过softmax函数将输入概率分布转化为输出概率分布。然后,CrossEntropyLoss按照这个概率分布计算损失。因此,CrossEntropyLoss能够自然地处理多分类问题,并且可以直接用于训练神经网络模型。
NLLLoss:负对数似然损失函数(Negative Log Likelihood Loss)。在计算NLLLoss之前,模型也需要通过softmax函数将输入概率分布转化为输出概率分布。然后,NLLLoss根据这个概率分布和真实标签计算损失。然而,由于NLLLoss没有直接考虑标签的类别分布,它不能直接用于训练神经网络模型,通常用于评估模型的性能。
因此,CrossEntropyLoss和NLLLoss都涉及到softmax函数,区别在于它们如何使用softmax函数计算损失。另外,由于它们的性质和用途不同,选择使用哪一个损失函数取决于具体的应用场景和需求。
# Import Extension import intel_pytorch_extension as ipex # Automatically mix precision ipex.enable_auto_optimization(mixed_dtype = torch.bfloat16) class FCN8s(nn.Module): # 定义双线性插值,作为转置卷积的初始化权重参数 def __init__(self,pretrained_net,num_classes): super(FCN8s,self).__init__() # (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) # (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) # (2): ReLU(inplace=True) # (3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) # (4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) # (5): ReLU(inplace=True) # (6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) # pool1 按照上述图片命名 self.pool1 = pretrained_net.features[:7] self.pool2 = pretrained_net.features[7:14] self.pool3 = pretrained_net.features[14:24] self.pool4 = pretrained_net.features[24:34] self.pool5 = pretrained_net.features[34:] self.relu = nn.ReLU(inplace=True) self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1) self.bn1 = nn.BatchNorm2d(512) self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1) self.bn2 = nn.BatchNorm2d(256) self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1) self.bn3 = nn.BatchNorm2d(128) self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1) self.bn4 = nn.BatchNorm2d(64) self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1) self.bn5 = nn.BatchNorm2d(32) self.classifier = nn.Conv2d(32, num_classes, kernel_size=1) def forward(self,x): # x = 352, 480,3 = height, width, channels # s1第一个下采样块的输出特征图 # x为输入图像 # layer1 为Vgg网络下,第一个下采样块和之前的结构 s1 = self.pool1(x) # >>> s1 = 176, 240,64 # 1/2 s2 = self.pool2(s1) # >>> s2 = 88, 120, 128 # 1/4 s3 = self.pool3(s2) # >>> s3 = 44, 60, 256 # 1/8 s4 = self.pool4(s3) # >>> s4 = 22, 30, 512 # 1/16 s5 = self.pool5(s4) # >>> s5 = 11, 15, 512 # 1/32 通道数增加到512,到700左右就行了,不闭增加过多 # relu 用来防止梯度消失 # bn 层用来,使数据保持高斯分布 # bn层 的里面是relu层,外面是转置卷积层, relu内部接转置卷积结果 scores = self.relu(self.deconv1(s5)) # h,w,n = 22, 30, 512 1/16 scores = self.bn1(scores + s4) # h,w,n = 22, 30, 512 1/16 scores = self.relu(self.deconv2(scores)) # h,w,n = 44 , 60, 256 1/8 scores = self.bn2(scores + s3) scores = self.bn3(self.relu(self.deconv3(scores))) # h,w,n = 88, 120, 128 1/4 scores = self.bn4(self.relu(self.deconv4(scores))) # h,w,n = 176, 240, 64 1/2 scores = self.bn5(self.relu(self.deconv5(scores))) # h,w,n = 352, 480, 32 1/1 return self.classifier(scores) # h,w,n= 352, 480, 5 1/1

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
2. 数据集导入
def __init__(self, img_path : str, label_path : str, labelUtils : LabelUtil):
super(UserDataset,self).__init__()
# 初始化图片和标签全路径,数组
self.imgslist = [os.path.join(img_path,item) for item in os.listdir(img_path)]
self.labelslist = [os.path.join(label_path,item) for item in os.listdir(label_path)]
self.transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
self.labelUtils = labelUtils
# 路径按名字,排个序
self.imgslist.sort()
self.labelslist.sort()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.训练
def trainNet(self): for epoch in range(30): print('epoch = '+str(epoch)+', loss = '+str(self.loss)) if epoch % 10 == 0 and epoch != 0: for group in self.optimizer.param_groups: group['lr'] *= 0.5 self.fcn.train() # 设置为训练过程。此时网络 的 参数能够进行参数学习 for i, sample in tqdm(enumerate(self.dataLoader)): # Variable为tensor数据构建计算图,便于网络的运算 https://www.cnblogs.com/czz0508/p/10333359.html imgdata, imglabel = Variable(sample['img']).to(ipex.DEVICE), Variable(sample['label'].long()).to(ipex.DEVICE) self.optimizer.zero_grad() # 梯度清0 netOutput = self.fcn(imgdata) # 将训练图片 送入网络 loss = self.calLoss(netOutput , imglabel) # 计算损失, label 和 网络输出的预测的结果进行对比,计算loss loss.backward() # 误差反向传播 self.optimizer.step() # 用优化器去更新权重参数 self.loss += loss.item() # 训练损失 记录 t.save(self.fcn.state_dict(), self.modelsavepath) print('*'*10,'train end')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
完成单张图预测并将预测图覆盖到原图上。
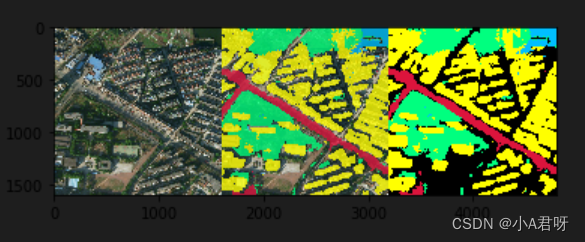
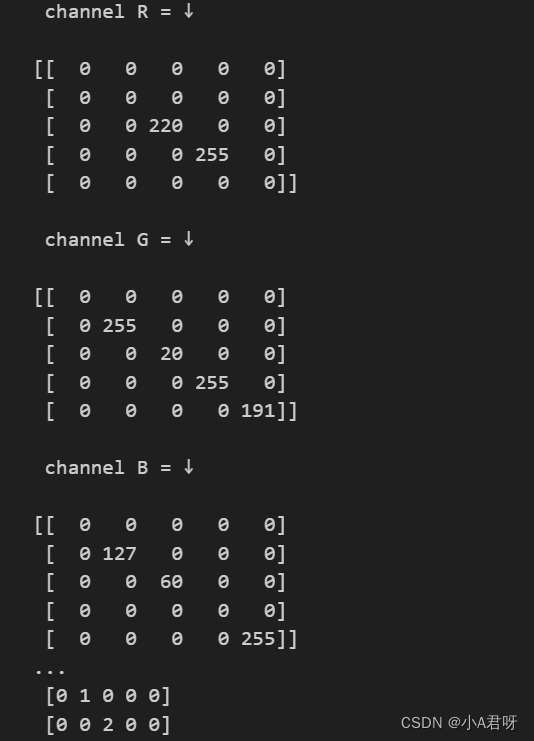
彩色三通道输出结果
intel 推理加速对比
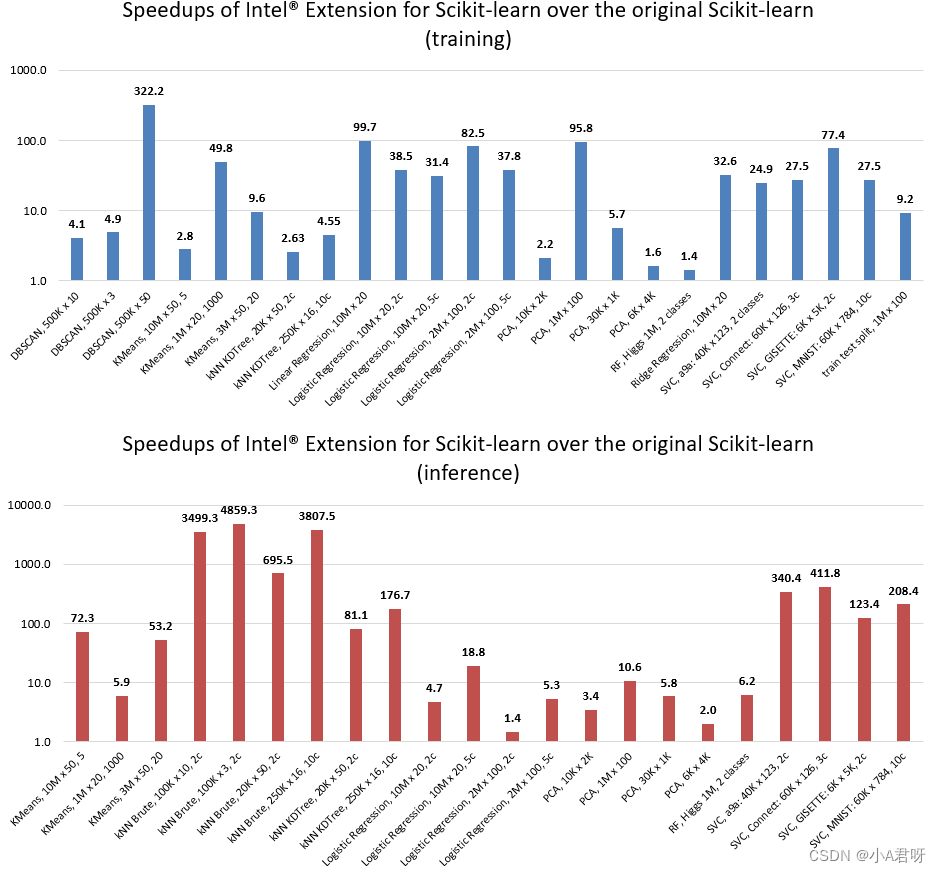
我们只是简单的开启了加速,推理速度有极大提升。
| 平均推理时间(ms) | 推理加速技术 |
|---|---|
| 13.1 | 原始PSPNet |
| 10.5 | 原始FCN |
| 8.3 | FCN8S实现 |
| 6.1 | FCN8S+ intel Scikit-learn |
总结
我们使用了Intel® Extension for Scikit-learn 实现了一个农作物指导的简易模型,并测试了Scikit-learn与Intel® Extension for Scikit-learn的训练速度,平均回归测试,提高了22%的性能。同时使用intel_pytorch_extension实现了一个遥感影像数据解析功能。通过这次比赛,也是学习了解了intel 的oneAPi库。收获很多。

