
热门标签
热门文章
- 1AI大模型引领金融创新变革与实践【文末送书】_金融加ai
- 2数据分析师学习路线与就业环境分析报告
- 3轻量级状态机框架 Sateless4j 实践_stateless4j permitdynamic
- 4STL复习-序列式容器和容器适配器部分
- 5#29 – User authentication failed问题总结_esm failure
- 6使用Github Actions自动同步到Gitee仓库_github gitee 自动同步github action
- 7vue的生命周期和父子组件渲染(需要结合react进行比较)_vue和react父子组件渲染周期对比
- 8go的爬虫工具教你如何去翻译(go调用js,colly的使用)_colly 执行js
- 9残差网络(ResNet)_residualblock
- 10pyqt5 QTimer使用_qtpy qtimer
当前位置: article > 正文
fofa资产收集-python爬虫_fofa token
作者:知新_RL | 2024-07-15 16:31:13
赞
踩
fofa token
在使用fofa进行搜索资产时,使用api接口调用进行提取时是有限制的,那提取上限怎么办?一个一个复制出来吗?当然不是,而是需要一个无限制爬取的脚本.
脚本
#coding:utf-8 import sys #reload(sys) #sys.setdefaultencoding('utf-8') import importlib,sys importlib.reload(sys) import base64 import requests from lxml import etree import time import threading threads=[] time_start = time.time() def fofa(): #其中search_data为搜索关键词 search_data='port="6379"' search_data_bs=base64.b64encode(search_data.encode('utf-8')) #print (search_data_bs) search_data_bs=str(search_data_bs,'UTF-8') url='https://fofa.info/result?qbase64=' headers={ 'cookie':'refresh_token=1;' 'fofa_token=你的fofa_token;' } for yeshu in range(1,5): urls=str(url)+search_data_bs+"&page="+str(yeshu) #print (urls) print("正在提取第"+str(yeshu)+"页数") try: result=requests.post(urls,headers=headers).content #print (result.decode('utf-8')) dayi=etree.HTML(result.decode('utf-8')) #print(dayi) ip_data=dayi.xpath('//span[@class="hsxa-copy-btn hsxa-copy-btn-no-link"]/@data-clipboard-text') #print (ip_data) ipdata='\n'.join(ip_data) #print (ipdata) with open(r'ip.txt', 'a+') as f: f.write(ipdata+'\n') f.close() except Exception: time.sleep(0.5) pass def ip(): for ip in open('ip.txt'): ip = ip.strip() ip = ip.strip('/') ip = ip.replace('https://','') ip = ip.replace('http://', '') data=":" if data in ip: ip = ip.split(":") del ip[-1] ip="".join(ip) with open(r'ipf.txt', 'a+') as f: f.write(ip + '\n') f.close() else: with open(r'ipf.txt', 'a+') as f: f.write(ip + '\n') f.close() def qc(): lines_seen = set() outfiile = open('result.txt', 'w', encoding='utf-8') f = open('ipf.txt', 'r', encoding='utf-8') for line in f: if line not in lines_seen: outfiile.write(line) lines_seen.add(line) if __name__ == '__main__': threads.append(threading.Thread(target=fofa)) for t in threads: t.start() t.join() ip() qc() time_end = time.time() time_sum = time_end - time_start print (" Program run time %s" %time_sum)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
脚本使用
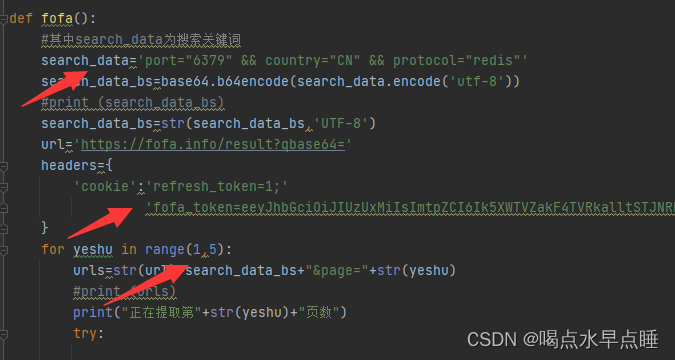
其中search_data填写搜索关键词

fofa_token在F12-cookie当中查找复制即可

后面的页数若是(1,5)那便是提取1页到5页.
结果输出
ip.txt提取的为原始内容结果如下
http://11.74.197.22:9090
http://11.74.197.22:9091
http://11.156.245.220:9090
- 1
- 2
- 3
ipf.txt提取的为原始内容的IP
11.74.197.22
11.74.197.22
11.156.245.220
- 1
- 2
- 3
result.txt是ipf.txt去重后的结果
11.74.197.22
11.156.245.220
- 1
- 2
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/830198
推荐阅读
相关标签

