
热门标签
热门文章
- 1Android monkey test 脚本的编写
- 2[职场] 数据架构师求职简历工作经历范文(精选5篇) #职场发展#学习方法_大数据 架构师 简历
- 3UI自动化和接口自动化该选谁?_接口自动化和ui自动化,哪个更复杂
- 4Unity自带Shader中Shandard中Rendering Mode区别_unity的create rendering 区别
- 5接口测试常见面试题(含答案)_软件测试接口测试面试题
- 6Git 分支合并时 Merge, Rebase, Squash 的使用场景_git wip merge
- 7OpenAI欲挑战Alexa与Siri?ChatGPT开发商申请“语音引擎”商标!|TodayAI_chatgpt语音引擎
- 8iosetup mysql_一键安装mysql主从环境(Docker)
- 9Elasticsearch - Elasticsearch核心概念(二)_elasticsearch type
- 1020240701 每日AI必读资讯_omniparse
当前位置: article > 正文
xml文件解析 (DOM4J解析XML) -java_dom4j 读取根节点签名
作者:知新_RL | 2024-07-13 04:39:52
赞
踩
dom4j 读取根节点签名
前言
今天,我们利用DOM4J 对xml文件进行解析。分别对本地的xml文件和网络上的xml文件进行解析。
提示:以下是本篇文章正文内容。
一、本地XML解析
1、导包并配置
1、在项目下新建lib文件夹,并把jar包导入。

2、更改项目配置



- 接下来

- 选中添加刚才创建的Libraries

- 应用之后如图所示:
2、编写一个简单的本地XML文件
- 里面保存了两本图书名字和简介
<?xml version="1.0" encoding="UTF-8" ?>
<Books>
<book id="1001">
<name>水浒传</name>
<info>《水浒传》是第一部描写农民起义的小说,全书围绕“官逼民反”这一线索展开情节,表现了一群不堪暴政欺压的“好汉”揭杆而起,聚义水泊梁山,直至接受招安致使起义失败的全过程。</info>
</book>
<book id="1002">
<name>西游记</name>
<info>《西游记》是中国古代第一部浪漫主义章回体长篇神魔小说。现存明刊百回本《西游记》均无作者署名。清代学者吴玉搢等首先提出《西游记》作者是明代吴承恩。</info>
</book>
</Books>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3、解析本地XML文件:
//获取输入流 FileInputStream fis = new FileInputStream("src/demo.xml"); //创建XML读取对象 SAXReader sr = new SAXReader(); //读取得到文档对象 Document doc = sr.read(fis); //通过文档获取根元素 Element root = doc.getRootElement(); //开始解析元素 System.out.println(root.getName()); //获取所有子元素 List<Element> es = root.elements(); for(int i=0; i<es.size(); i++) { Element book = es.get(i); System.out.println("《"+book.elementText("name")+"》"); System.out.println(book.elementText("info")); System.out.println("----------------------------"); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 输出结果如下:
Books为根元素。
- 1
Books
《水浒传》
《水浒传》是第一部描写农民起义的小说,全书围绕“官逼民反”这一线索展开情节,表现了一群不堪暴政欺压的“好汉”揭杆而起,聚义水泊梁山,直至接受招安致使起义失败的全过程。
----------------------------
《西游记》
《西游记》是中国古代第一部浪漫主义章回体长篇神魔小说。现存明刊百回本《西游记》均无作者署名。清代学者吴玉搢等首先提出《西游记》作者是明代吴承恩。
----------------------------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
二、解析网络上的XML文件
1.网址:
http://apis.juhe.cn/mobile/get?%20phone=xxxxxx&dtype=xml&key=9f3923e8f87f1ea50ed4ec8c39cc9253
(xxxxx填写电话号码即可)
本api是可以通过电话号码可以查询到此号码的归属地的xml文件
例如此号码:
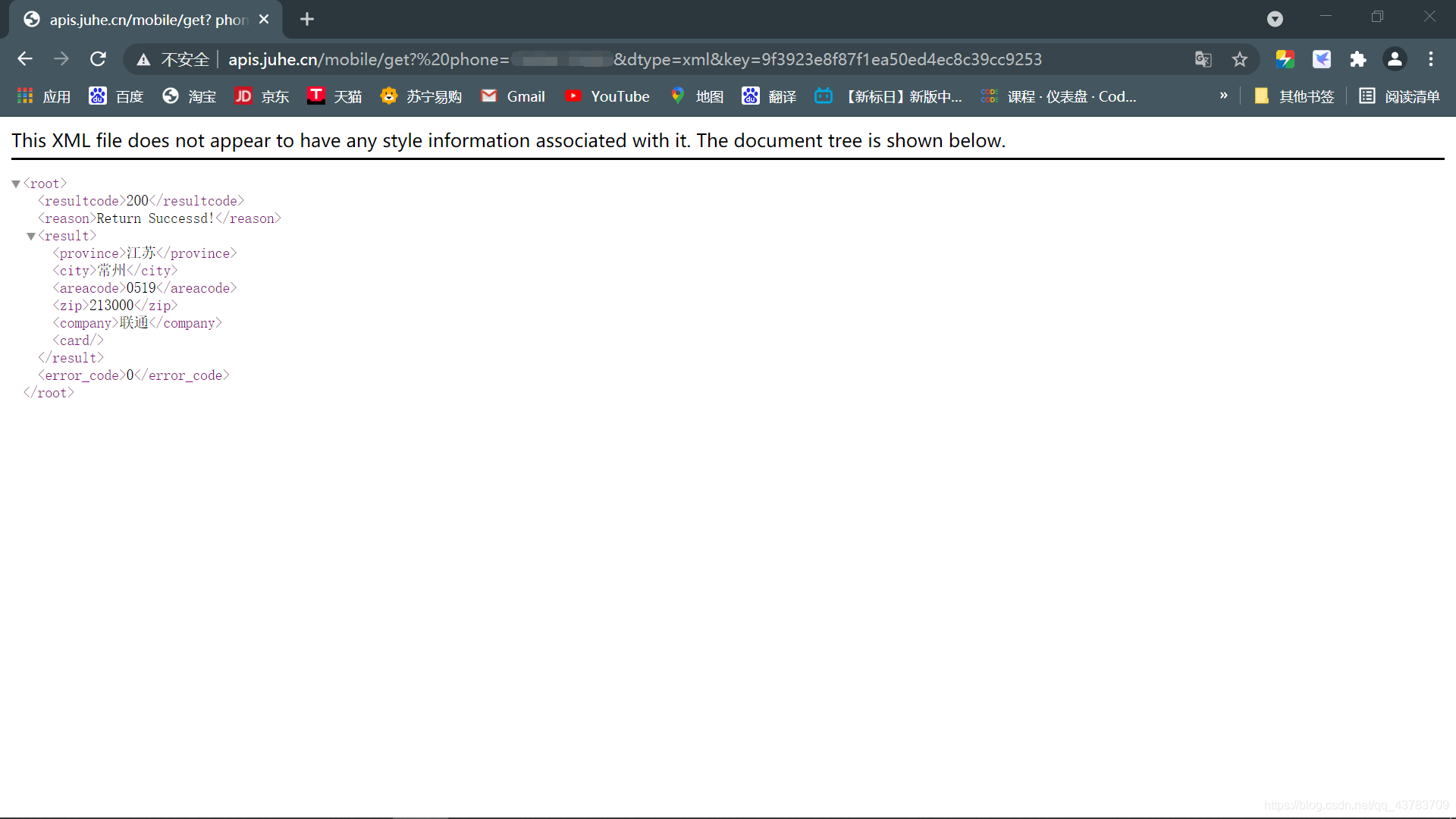
2、来解析此网络XML文件
//1. 获取到XML资源的输入流 String phone = "xxxxxx"; URL url = new URL("http://apis.juhe.cn/mobile/get? phone=" + phone + "&dtype=xml&key=9f3923e8f87f1ea50ed4ec8c39cc9253"); URLConnection conn = url.openConnection(); InputStream is = conn.getInputStream(); // 2. 创建一个XML读取对象 SAXReader sr = new SAXReader(); // 3. 通过读取对象 读取XML数据,并返回文档对象 Document doc = sr.read(is); // 4. 获取根节点 Element root = doc.getRootElement(); //5. 解析内容 String code = root.elementText("resultcode"); if ("200".equals(code)) { Element result = root.element("result"); String province = result.elementText("province"); String city = result.elementText("city"); if (province.equals(city)) { System.out.println("手机号码归属地为:" + city); } else { System.out.println("手机号码归属地为:" + province + " " + city); } } else { System.out.println("请输入正确的手机号码"); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
刚刚的xml文件读取结果为:
手机号码归属地为:江苏 常州
- 1
3、DOM4J - XPATH解析XML
1、路径表达式
通过路径快速的查找一个或一组元素
- / : 从根节点开始查找
- // : 从发起查找的节点位置 查找后代节点 ***
- . : 查找当前节点
- … :查找父节点
- @ : 选择属性. *
属性使用方式:
- [@属性名=‘值’]
- [@属性名>‘值’]
- [@属性名<‘值’]
- [@属性名!=‘值’]
2、使用步骤
通过Node类的两个方法,
来完成查找: (Node是 Document 与 Element 的父接口)
方法1.
//根据路径表达式, 查找匹配的单个节点
Element e = selectSingleNode("路径表达式");
- 1
- 2
方法2.
List<Element> es = selectNodes("路径表达式");
- 1
3、利用上述Book案例
代码如下:
//获取输入流 FileInputStream fis = new FileInputStream("src/demo.xml"); //创建XML读取对象 SAXReader sr = new SAXReader(); //读取得到文档对象 Document doc = sr.read(fis); /** * //通过文档获取根元素 * Element root = doc.getRootElement(); * //开始解析元素 * System.out.println(root.getName()); * //获取所有子元素 * List<Element> es = root.elements(); */ //通过文档对象+xpath,查找所有的name节点 List<Node> names = doc.selectNodes("//name"); for(int i=0; i<names.size(); i++) { Node book = names.get(i); //System.out.println("《"+book.elementText("name")+"》"); System.out.println(book.getText()); System.out.println("----------------------------"); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
水浒传
----------------------------
西游记
----------------------------
Process finished with exit code 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
还记得book的xml文件,每本书都有个id,加上属性条件后:
List<Node> names = doc.selectNodes("//book[@id='1001']//name");
- 1
此处因为只查找一个,所以可以使用:Node name = doc.selectSingleNode("//book[@id=‘1001’]//name");
输出结果:
水浒传
----------------------------
- 1
- 2
总结
以上就是xml文件的解析过程。是用DOM4J解析XML的方式。此外还有三种方法:SAX解析、DOM解析、JDOM解析。
DOM4J解析XML
步骤:
- 引入jar文件
dom4j.jar - 创建一个指向XML文件的输入流
FileInputStream fis = new FileInputStream(“xml文件的地址”); - 创建一个XML读取工具对象
SAXReader sr = new SAXReader(); - 使用读取工具对象, 读取XML文档的输入流 , 并得到文档对象
Document doc = sr.read(fis); - 通过文档对象, 获取XML文档中的根元素对象
Element root = doc.getRootElement();
文档对象 Document:指的是加载到内存的 整个XML文档.
常用方法:
- 通过文档对象, 获取XML文档中的根元素对象 Element root = doc.getRootElement();
- 添加根节点 Element root = doc.addElement(“根节点名称”);
元素对象 Element
指的是XML文档中的单个节点. 常用方法:
- 获取节点名称
String getName(); - 获取节点内容
String getText(); - 设置节点内容
String setText(); - 根据子节点的名称 , 获取匹配名称的第一个子节点对象.
Element element(String 子节点名称); - 获取所有的子节点对象
List elements(); - 获取节点的属性值
String attributeValue(String 属性名称); - 获取子节点的内容
String elementText(String 子节点名称); - 添加子节点
Element addElement(String 子节点名称); - 添加属性
void addAttribute(String 属性名,String 属性值);
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/817678
推荐阅读
相关标签

