
- 1Target-aware Transformer 知识蒸馏代码复现_crcd蒸馏代码复现
- 2《网络是怎样连接的》笔记整理
- 3LeetCode_Array_126. Word Ladder II单词接龙II(C++)【双向BFS构图+DFS寻找路径】_c++单词接龙dfs
- 4Spring Boot 邮件发送的 5 种姿势!
- 52024年Python最新万字博文教你python爬虫Beautiful Soup库【详解篇】(1),阿里巴巴面试算法题
- 6【MySQL】我必须得告诉大家的MySQL优化原理3(下)INNODB配置_unknown suffix 'i' used for variable 'innodb-log-f
- 7【web渗透思路】敏感信息泄露(网站+用户+服务器)_渗透测试,敏感信息泄露
- 8Python+VS Code+Selenium+EdgeDriver实现网页自动化_selenium edgedriver
- 9数字办公新纪元 :ONLYOFFICE 2.5重磅来袭_ficitx5 onlyoffice
- 10wordpress 通过域名无法访问_教你搭建Wordpress网站
【Python机器学习系列】一文彻底搞懂机器学习中的归一化与反归一化问题_python归一化和反归一化
赞
踩
1、什么是归一化和反归一化
话不多说,先上一段代码,自己体会:
- import numpy as np
- from sklearn.preprocessing import MinMaxScaler #导入库
-
- data = np.random.randint(0,5,size=5) #随机生成长度为5的数据
- data = np.array(data).reshape((len(data), 1))
- print('原始数据:', data, sep='\n')
- m = MinMaxScaler() #建立一个归一化器
- data_1 = m.fit_transform(data) #利用m对data进行归一化,并储存data的归一化参数
- print('归一化数据:', data_1, sep='\n')
- data_2 = m.inverse_transform(data_1) #利用m对data_1进行反归一化
- print('反归一化数据:', data_2, sep='\n')
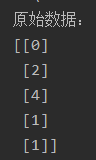
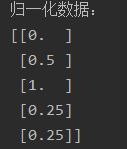
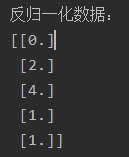
归一化和反归一化是机器学习中常用的数据预处理技术,用于将原始数据转换为特定范围或分布,并在需要时将其还原回原始数据。在实际应用中,归一化通常在训练数据上进行,然后使用同样的归一化参数对测试数据进行归一化,以保持一致性。反归一化则是在模型预测或评估阶段使用,将归一化后的结果转换回原始数据范围,以便进行后续分析和解释。
注:狭义的归一化指的是最大最小值归一化,广义的归一化包括很多方法,最常见的有最大最小值归一化和标准化。本文的案例使用的归一化方法指的是最大最小值归一化,其思路同样可以用到其他归一化的方法。
2、为什么需要归一化/标准化处理?
-
做训练时,需先将特征值与标签归一化或标准化,可以防止梯度防炸和过拟合。
-
若将标签标准化后,网络预测出的数据是符合标准正态分布的—StandarScaler(),与真实值有很大差别。因为StandarScaler()对数据的处理是(真实值-平均值)/标准差。同时在做预测时需要将输出数据逆标准化。
-
-
提升模型精度:归一化使不同维度的特征在数值上更具比较性,提高分类器的准确性。
-
提升收敛速度:对于线性模型,数据归一化使梯度下降过程更加平缓,更易正确的收敛到最优解。
3、哪些机器学习模型需要数据归一化/标准化处理?
-
关心变量值、基于距离读量的模型,使用梯度下降的算法,需要归一化:如SVM, 逻辑回归,神经网络,KNN, 线性回归,Adaboost、KMeans、LSTM
-
树模型是阶越的,不可导,因此树模型是不能进行梯度下降的。树模型是通过寻找特征的最优分裂点来完成优化的,由于归一化不会改变分裂点的位置树形结构的不需要归一化,如xgboost、lightGBM、GBDT
-
概率模型不关心变量值,而关心变量的分布、变量之间的条件概率,不需要归一化。这类模型如决策树、随机森林、朴素贝叶斯
4、特征和标签是否都需要归一化/标准化处理?
对于需要归一化/标准化的模型而言:
-
X必须归一化,否则无法训练
-
训练出的结果W和B,在推理时有两种使用方式:
-
a. 直接使用,此时必须把预测时输入的X也做相同规则的归一化
-
b. 反归一化为W,B的本来值Wreal和Breal,推理时输入的X不需要改动
-
-
Y可以归一化,好处是迭代次数少。如果结果收敛,也可以不归一化,如果不收敛(数值过大),就必须归一化。
-
如果Y归一化,对得出来的结果做关于Y的反归一化
5、机器学习模型归一化/标准化处理的流程?
做归一化/标准化只是为了更好的训练,归一化/标准化一定是在数据集划分之后做,分别对训练集和验证集做。归一化/标准化处理得出的模型,对于验证集肯定也得按照训练集的标准去做归一化/标准化处理输入到模型中。
一个完整的机器学习应用归一化的案例
-
- import pandas as pd
- import numpy as np
- from sklearn.preprocessing import MinMaxScaler
- from sklearn.linear_model import LinearRegression
-
- # 建立数据集:假设训练集有10个样本,测试集有5个样本;两个输入特征,一个输出
- train_data = np.array([[0,1,3],[3,2,0],[0,2,3],[4,3,4],[3,0,1],[4,3,2],[2,3,3],[1,4,3],[0,4,4],[3,1,0]])
- train_data = pd.DataFrame(train_data, columns = ['output','input1','input2'])
- x_train = train_data[['input1','input2']].values
- y_train = train_data[['output']].values
-
- test_data = np.random.randint(5,size=(5,3))
- test_data = pd.DataFrame(test_data ,columns = ['output','input1','input2'])
- x_test = test_data[['input1','input2']].values
- y_test = test_data[['output']].values
-
- # 对训练集进行归一化,特征和标签可以分开归一化处理,也可以一起,效果都是一样的,如果一起后面反归一化预测值会麻烦些
- # mm = MinMaxScaler() # 特征和标签一起归一化处理
- # train_data_m = mm.fit_transform(train_data)
- mm1 = MinMaxScaler() # 特征进行归一化
- x_train_m = mm1.fit_transform(x_train)
- mm2 = MinMaxScaler() # 标签进行归一化
- y_train_m = mm2.fit_transform(y_train)
-
- # 将归一化的训练数据输入模型,经过模型训练,得到了模型model
- Model = LinearRegression()
- Model.fit(x_train_m, y_train_m)
-
- # 对测试集特征进行相同规则mm1的归一化处理,然后输入到模型进行预测
- x_test_m = mm1.transform(x_test) #注意fit_transform() 和 transform()的区别
- predicted_y_m = Model.predict(x_test_m) #利用输入特征input1和input2测试模型
-
- # 预测结果进行相同规则mm2反归一化
- predicted_y = mm2.inverse_transform(predicted_y_m)
- print(predicted_y)

这里重点需要关注的有两点:
-
第一点:fit_transform() 和 transform()的区别。两者都是归一化函数,但是fit_transform() 会储存归一化函数是的相关参数,因此对训练集使用fit_transform() ,储存了训练集归一化的相关参数,然后利用这些参数对测试集进行统一的归一化transform()【切记不能再使用fit_transform() ,第二次使用fit_transform() 会刷新mm里储存的参数!!】 。
-
第二点:反归一化时任然要使用归一化时储存的参数和格式。归一化时使用的是mm1 = MinMaxScaler(),因此后面仍然要使用mm1进行反归一化;归一化时fit_transform(x_train) 中的x_train是2维度(这里10个样本,即为10*2)的数组,因此反归一化时的数据也必须是2列,即5*2。
本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,对Python有一定认知和理解,会结合自身科研实践经历不定期分享关于python、机器学习、深度学习等基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注底部公众号联系作者获取数据源码。

