
- 1单兵渗透工具-Yakit-Windows安装使用
- 2【k8s总结】
- 3大数据毕业设计hadoop+spark+hive招聘推荐系统 招聘分析可视化大屏 职位推荐系统 就业推荐系统 招聘爬虫 招聘大数据 计算机毕业设计 机器学习 深度学习 人工智能_spark招聘就业类大屏
- 4媒体邀约有啥要注意的
- 5【CVPR2021】LoFTR:基于Transformers的无探测器的局部特征匹配方法_loftr场景匹配
- 6人工智能的研究方向
- 7uniapp跨域解决_uniapp解决跨域问题
- 8稀疏编码在深度学习中的挑战
- 9【ubuntu-22.04】系统配置之 netplan 网络配置_netplan routes
- 10【深度学习】读取和存储训练好的模型参数(pyTorch)_训练结束后得到了一个pytorchmodel.bin文件,怎么去读取运用他
DIVE INTO DEEP LEARNING 50-55
赞
踩
文章目录
50. semantic segmentation
50.1 Basic concepts
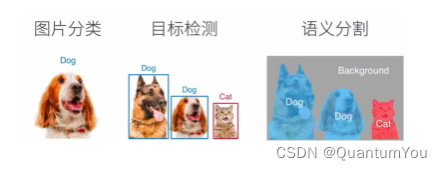
- 语义分割是计算机视觉领域中的一项重要任务,它的目标是为图像中的每个像素分配一个类别标签,从而实现对图像的细致理解。与图像分类任务不同,图像分类只关注整幅图像属于哪个类别,而语义分割则要求对每个像素进行类别预测,从而得到像素级的分类结果。
语义分割将图片中的每个像素分类到对应的类别。
-
像素级分类:语义分割的输出是一个与输入图像大小相同的矩阵,矩阵中的每个元素(即每个像素)都对应一个类别标签。
-
类别识别:语义分割需要识别图像中的不同物体或区域,并为它们分配相应的类别标签。这些类别可以是天空、道路、建筑、行人等。
-
精细分割:与图像分割 相比,语义分割更注重类别的识别,而不仅仅是将图像划分为不同的区域。因此,语义分割通常需要更精细的分割结果。
-
主要方法:语义分割的方法主要包括基于传统图像处理和基于深度学习的方法。传统方法通常利用颜色、纹理、形状等特征进行分割,而深度学习方法则通过训练神经网络模型来提取图像中的特征并实现像素级分类。目前,基于深度学习的语义分割方法已经取得了显著的效果,如全卷积网络(FCN)、U-Net、DeepLab等。
50.2 Major application
-
背景虚化:传统的背景替换往往采用绿幕。在没有绿幕的情况下传统相机可以通过光圈来实现背景虚化,对于手机等设备而言背景虚化通常使用的都是语义分割或结合图像景深信息。
-
路面分割:如无人驾驶时用于实时识别周围物体,实现找路的功能。
总结: 语义分割在自动驾驶、医学图像处理、卫星图像分析等领域有着广泛的应用。 在自动驾驶中,语义分割可以帮助车辆识别道路、行人、车辆等障碍物;在医学图像处理中,语义分割可以帮助医生识别病变区域。
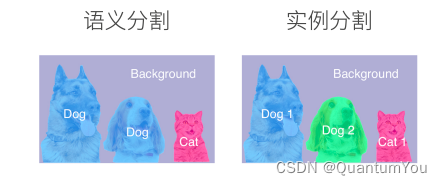
语义分割与实例分割的区别
- 语义分割只关心像素属于哪一类,而实例分割则更进一步,如图片里有两只狗,则需要得出哪个像素属于哪一只狗。可以将其理解为目标检测的进化版本。
51. Transposed convolution
51.1 Basic concepts
- 转置卷积 ,也被称为反卷积(Deconvolution),是深度学习中的一种重要操作,主要用于实现上采样或特征图的尺寸恢复。以下是关于转置卷积的详细介绍:
上采样是图像处理中用于增加图像分辨率或恢复特征图尺寸的技术。在深度学习中,特别是在图像分割和生成模型中,上采样是一个关键步骤。
- 转置卷积被视为卷积操作的一种逆向过程,但其并不真正恢复原始图像或特征图的数值,而是根据卷积核大小和输出大小,恢复特征图的尺寸。
- 与传统的上采样方法(如最近邻插值、双线性插值等)不同,转置卷积具有可学习的参数,能够通过网络学习获取最优的上采样方式。
51.2 Major role
- 上采样:转置卷积可将输入的尺寸扩大,增加图像的分辨率,使其更适合某些任务,如图像分割。
- 特征图还原:在某些情况下,由于卷积和池化等操作,输入特征图的尺寸会减小。通过转置卷积,可以恢复特征图的尺寸,使其保持原始输入的形状。
- 生成模型中的应用:在生成对抗网络(GAN)等生成模型中,转置卷积用于从随机噪声生成高分辨率的图像。
51.3 Implementation steps and application areas
- 定义卷积核:与正常卷积操作一样,需要定义一个卷积核,其尺寸决定了转置卷积的输出尺寸。
- 对输入进行填充:为了保持输出与原始输入相同的尺寸,通常需要在输入周围进行填充操作。
- 卷积操作:使用定义的卷积核对填充后的输入进行卷积操作。
- 选择步长(stride):步长的选择影响输出的尺寸,步长越大,输出尺寸越小。
- 去除填充:为了最终保持输出与原始输入相同的尺寸,需要去除填充部分。
- 生成对抗网络(GAN):在生成器中,通过转置卷积将随机噪声逐步放大,生成复杂的图像。
- 图像分割:在解码器中,使用转置卷积恢复编码器输出的特征图尺寸,得到与原始图像相同尺寸的分割图。
- 语义分割:如FCN和U-Net等经典方法,利用转置卷积在解码器中恢复特征图尺寸,从而对原图中的每个像素进行分类。
总结
转置卷积 有上采样和特征图尺寸恢复的能力。其独特的可学习参数使其在处理复杂的上采样任务时更加灵活和有效。在生成对抗网络、图像分割和语义分割等领域有着广泛的应用。
51.4 Transposed convolution
-
转置卷积和卷积的区别:
- 卷积不会增大输入的高宽,通常要么不变、要么减半
- 转置卷积则可以用来增大输入高宽
-
转置卷积的具体实现:
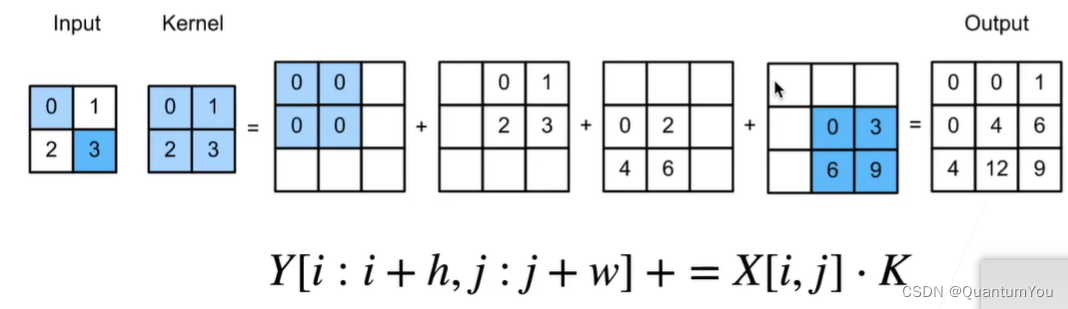
如图所示,input里的每个元素和kernel相乘,最后把对应位置相加,相当于卷积的逆变换
- 为什么称之为“转置:
- 对于卷积Y=X*W
- 可以对W构造一个V,使得卷积等价于矩阵乘法Y’=VX’
- 这里Y’,X’是Y,X对应的向量版本
- 转置卷积等价于Y’=VTX’
- 如果卷积将输入从(h,w)变成了(h‘,w’)
- 同样超参数的转置卷积则从(h‘,w’)变成为(h,w)
- 对于卷积Y=X*W
转置卷积X’=V^T Y’
51.5 Transposed convolution is a type of convolution

-
重新排列输入和核
- 当填充为0步幅为1时:
- 将输入填充k-1(k时核窗口)
- 将核矩阵上下、左右翻转
- 然后做正常卷积(填充0、步幅1)
- 当填充为0步幅为1时:
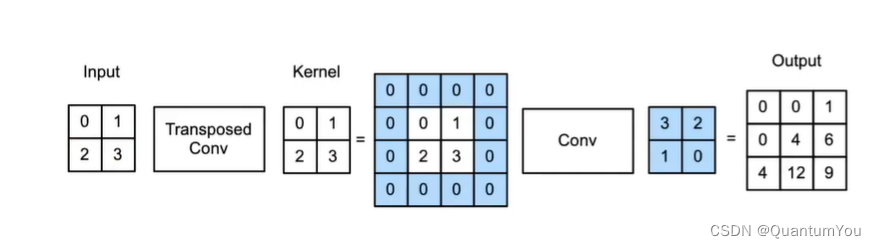
- 当填充为p步幅为1时:
- 将输如填充k-p-1(k是核窗口)
- 将核矩阵上下、左右翻转
- 然后做正常卷积(填充0、步幅1)
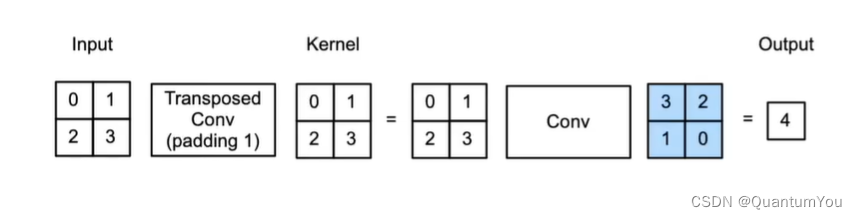
-
当填充为p步幅为s时:
-
在行和列之间插入s-1行或列
-
将输如填充k-p-1(k是核窗口)
-
将核矩阵上下、左右翻转
-
然后做正常卷积(填充0、步幅1)
-
-
形状换算
-
输入高(宽)为n,核k,填充p,步幅s:
-
转置卷积:n‘=sn+k-2p-s
-
卷积:n’=[(n-k-2p+s)/s]向下取整
-
-
如果让高宽成倍增加,那么k=2p+s
-
-
同反卷积的关系
- 数学上的反卷积是指卷积的逆运算
- 若Y=conv(X,K),那么X=deconv(Y,K)
- 反卷积很少用在深度学习中
- 我们说的反卷积神经网络指用了转置卷积的神经网络
- 数学上的反卷积是指卷积的逆运算
总结
- 转置卷积是一种变化了输入和核的卷积,来得到上采用的目的
- 不等同于数学上的反卷积操作
52. Sequence model
52.1 Sequence data
- 序列数据(Sequential Data)或时间序列数据(Time Series Data)是在时间顺序上收集的数据点序列。这些数据点通常是按照相等的间隔(例如,每天、每小时、每分钟等)收集的,但也可能是不规则间隔的。序列数据在许多领域都很常见,包括金融、气象、医疗、物理等。
52.1.1 Characteristics of sequence data
- 时间依赖性:序列数据中的每个数据点都与其在时间序列中的位置有关。因此,数据的顺序和它们之间的时间间隔是重要的。
- 趋势和周期性:序列数据可能包含长期趋势(例如,增长或下降)、季节性模式(例如,每年的周期性变化)或周期性波动(例如,每周的周期性变化)。
- 自相关性:序列数据中的连续观测值之间可能存在依赖关系。也就是说,一个观测值可能与它之前的观测值有关。
52.1.2 Analysis of sequence data
- 序列数据分析的目标是提取数据中隐藏的信息,例如趋势、季节性模式、周期性波动、异常值等。这可以通过多种方法来实现,包括:
- 可视化:通过图表(如折线图、柱状图、箱线图等)来直观地展示序列数据。
- 统计方法:使用统计测试(如相关性分析、回归分析、方差分析等)来量化数据中的关系。
- 时间序列分析:使用专门的时间序列模型(如ARIMA模型、SARIMA模型、指数平滑法等)来预测未来的值或解释过去的行为。
- 机器学习:使用机器学习算法(如循环神经网络RNN、长短时记忆网络LSTM等)来处理和分析复杂的序列数据。
52.1.3 Application of sequence data
序列数据在许多实际应用中都很重要,例如:
- 金融:股票价格、汇率、债券收益率等金融数据通常是序列数据,可以用于预测未来的市场走势或进行风险管理。
- 气象:温度、降雨量、风速等气象数据是序列数据,可以用于预测天气模式或气候变化。
- 医疗:患者的生命体征(如心率、血压、体温等)是序列数据,可以用于监测健康状况或预测疾病进程。
- 物理:地震活动、太阳辐射、海洋温度等物理现象产生的数据也是序列数据,可以用于理解自然规律和预测潜在风险。
实际中很多数据是有时序的
-
电影的评价随时间变化而变化
-
音乐、文本、语言和视频都是连续的
-
预测明天的股价要比填补昨天遗失的股价更困难
52.1.4 Statistical tools
- 统计工具在机器学习中扮演着至关重要的角色,它们帮助数据科学家和机器学习工程师处理、分析和解释数据,以构建和优化模型。
-
描述性统计工具:
- 这类工具用于描述数据集的基本特征,如集中趋势(平均值、中位数、众数)、离散程度(方差、标准差)、分布形状(偏度、峰度)等。
- 例如,在机器学习的数据预处理阶段,描述性统计工具可以帮助我们了解数据的整体情况,发现数据中的异常值或缺失值,并进行相应的处理。
-
假设检验工具:
- 假设检验是统计学中的一种重要方法,用于判断样本数据是否支持关于总体参数的某个假设。
- 在机器学习中,假设检验工具可以帮助我们评估模型的性能是否显著优于某个基准模型,或者判断某个特征是否对模型性能有显著影响。
-
相关性分析工具:
- 相关性分析用于研究两个或多个变量之间的关系强度和方向。
- 在机器学习中,相关性分析工具可以帮助我们理解特征之间的相关性,避免在模型中包含高度相关的特征,从而提高模型的泛化能力。
-
特征选择工具:
- 特征选择是机器学习中的一个重要步骤,旨在从原始特征集中选择出与目标变量最相关的特征子集。
- 统计工具如卡方检验、信息增益、互信息等可以帮助我们评估特征与目标变量之间的相关性,从而进行特征选择。
-
模型评估工具:
- 模型评估是机器学习中的一个关键步骤,用于评估模型的性能并选择合适的模型。
- 统计工具如混淆矩阵、准确率、召回率、F1分数、AUC-ROC曲线等可以帮助我们全面评估模型的性能。
-
机器学习库和框架:
- 许多机器学习库和框架都内置了丰富的统计工具,如Scikit-Learn、TensorFlow、PyTorch等。
- 这些库和框架提供了各种统计函数和算法,方便用户进行数据处理、特征工程、模型训练和评估等任务。
52.1.5 Sequence model introduce

- 对条件概率建模

52.2 Option A: Markov Hypothesis
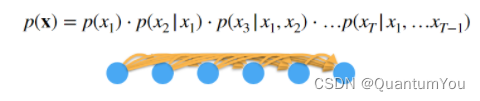
- 假设当前数据只跟τ个过去数据点相关

52.3 Option B: latent variable model
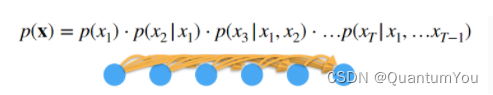
潜变量模型 是一种用于解释和预测观察变量(即可以直接测量的变量)之间关系的统计方法。它基于的假设是,存在一些不能直接观察但可以通过其他观察变量推断出来的变量(即潜变量)。
-
潜变量的定义:
- 潜变量是那些不能直接观测,但可以通过数学模型和观察到的其他变量进行推断的变量。
- 潜变量模型旨在通过潜在变量来解释观察变量之间的关系。
-
潜变量模型的结构:
- 潜变量模型通常包含两部分:潜变量(通常表示为h_t)和观察变量(通常表示为x_t)。
- 在模型中,潜变量h_t用于表示过去的信息,它是基于之前的观察变量x_1, …, x_{t-1}的函数,即h_t = f(x_1, …, x_{t-1})。
- 观察变量x_t则与潜变量h_t有关,即x_t = p(x_t | h_t),其中p表示条件概率。
-
潜变量模型的应用:
- 潜变量模型在多个领域都有应用,包括心理学、经济学和机器学习等。
- 在心理学中,潜变量可能代表某种心理状态或特质,如“五大人格特质”。
- 在经济学中,潜变量可能代表生活质量、商业信心等无法直接衡量的变量。
-
潜变量的类型:
- 潜变量可分为内生潜变量和外生潜变量。
- 外生潜变量是在模型中不受其他变量影响但影响其他变量的变量。
- 内生潜变量是在模型中总会受到一个其他变量影响的变量。
- 潜变量可分为内生潜变量和外生潜变量。
-
潜变量模型的推断方法:
- 推断潜变量的常用方法包括隐马尔可夫模型、因子分析、主成分分析、偏最小二乘回归等。
- 贝叶斯统计方法也常用于推断潜变量。
-
潜变量模型的分类:
- 根据潜变量的类型,潜变量模型可分为离散型潜变量模型和连续型潜变量模型。
潜变量模型是一种强大的统计工具,它允许我们通过不可直接观测的变量来理解和预测可观测变量之间的关系。这种模型在多个领域都有广泛的应用,并且有多种不同的推断和建模方法。
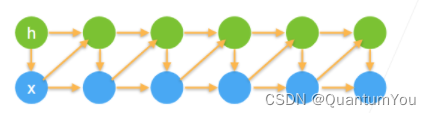
总结
- 时序模型中,当前数据跟之前观察到的数据相关
- 自回归模型使用自身过去数据来预测未来
- 马尔科夫模型假设当前只跟最近少数数据相关,从而简化模型
- 潜变量模型使用潜变量来概括历史信息
潜变量模型和隐马尔科夫模型有什么区别?
没有太多联系,两个不同的观点,但是潜变量模型可以使用隐马尔科夫假设。潜变量-怎么建模,隐马尔科夫-这个数据和之前多少个数据有关。
53. Fully convolutional neural network
53.1 Basic concepts
- FCN,全称为Fully Convolutional Network(全卷积网络),是一种深度学习模型,主要用于图像语义分割。与传统的卷积神经网络(CNN)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测,同时保留了原始输入图像中的空间信息,最后在上采样的特征图上进行逐像素分类。这种方法使得FCN能够输出与输入图像同样大小的分割图像,为每个像素都分配一个类别标签,从而实现图像的精确分割。
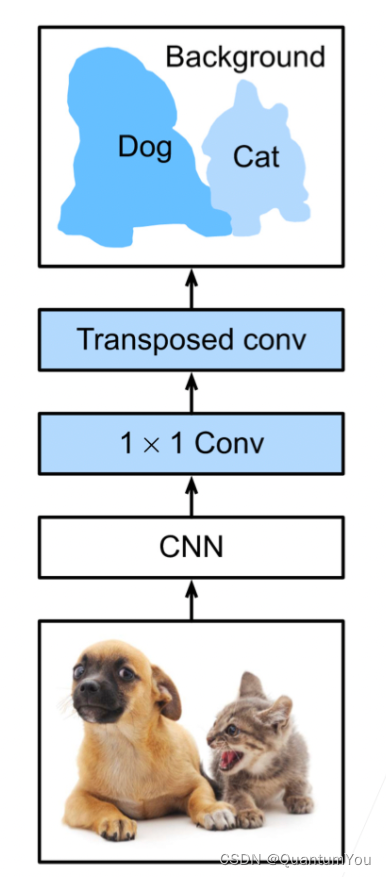
53.2 Characteristics and advantages
- 可以接受任意大小的输入图像,这使得它在处理不同尺寸的图像时具有很大的灵活性。
- 通过上采样操作,能够恢复到与原始输入图像相同的尺寸,从而实现对每个像素的精确分类。
- 保留了原始输入图像中的空间信息,这对于图像分割任务非常重要,因为空间信息对于准确判断像素类别至关重要。
- FCN是深度神经网络来做语义分割的奠定性工作,现在用的不多了
- 他用转置卷积层来替换CNN最后的全连接层(还有池化层),从而实现每个像素的预测。(如果输入的图片是224 x 224,经过CNN变成 7 x 7,经过 transposed conv,可以还原到 224 x 224 x k,k为通道数)
54. Language model
-
语言模型的目标:
假设长度为T的文本序列中的词元依次为x1,x2,…,xT。 于是,xt(1≤t≤T) 可以被认为是文本序列在时间步t处的观测或标签。 在给定这样的文本序列时目标是估计序列的联合概率P(x1,x2,…,xT)
54.1 Basic concepts
-
基本想法:
P(x1,x2,…,xT) = P(xt∣x1,…,xt−1). (1 <= t <= T) 共T个结果相乘
例如,包含了四个单词的一个文本序列的概率是:
*P*(deep,learning,is,fun)=*P*(deep)*P*(learning∣deep)*P*(is∣deep,learning)*P*(fun∣deep,learning,is)
- 1
为了训练语言模型,我们需要计算单词的概率, 以及给定前面几个单词后出现某个单词的条件概率。 这些概率本质上就是语言模型的参数。训练数据集中词的概率可以根据给定词的相对词频来计算。 例如,可以将估计值P^(deep) 计算为任何以单词“deep”开头的句子的概率。 一种(稍稍不太精确的)方法是统计单词“deep”在数据集中的出现次数, 然后将其除以整个语料库中的单词总数。 这种方法效果不错,特别是对于频繁出现的单词。
-
基本想法的问题:
由于连续单词对“deep learning”的出现频率要低得多, 所以估计这类单词正确的概率要困难得多。 特别是对于一些不常见的单词组合,要想找到足够的出现次数来获得准确的估计可能都不容易。 而对于三个或者更多的单词组合,情况会变得更糟。 许多合理的三个单词组合可能是存在的,但是在数据集中却找不到。 除非我们提供某种解决方案,来将这些单词组合指定为非零计数, 否则将无法在语言模型中使用它们。 如果数据集很小,或者单词非常罕见,那么这类单词出现一次的机会可能都找不到。
54.2 Markov Model and N-ary Grammar
- 如果P(xt+1∣xt,…,x1)=P(xt+1∣xt), 则序列上的分布满足一阶马尔可夫性质。
阶数越高,对应的依赖关系就越长。 这种性质推导出了许多可以应用于序列建模的近似公式:- P(x1,x2,x3,x4) = P(x1)P(x2)P(x3)P(x4)
- P(x1,x2,x3,x4) = P(x1)P(x2 |x1)P(x3|x2)P(x4|x3)
- P(x1,x2,x3,x4) = P(x1)P(x2 |x1)P(x3|x1,x2)P(x4|x2,x3)
54.3 Natural language statistics
- 在真实数据上如果进行自然语言统计:
根据时光机器数据集构建词表,并打印前10个最常用的单词
import random
import torch
from d2l import torch as d2l
tokens = d2l.tokenize(d2l.read_time_machine())
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
vocab.token_freqs[:10]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 正如我们所看到的,最流行的词看起来很无聊, 这些词通常被称为停用词(stop words),因此可以被过滤掉。 尽管如此,它们本身仍然是有意义的,我们仍然会在模型中使用它们。 此外,还有个明显的问题是词频衰减的速度相当地快。 例如,最常用单词的词频对比,第10个还不到第1个的1/5。 为了更好地理解,我们可以画出的词频图:
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
- 1
- 2
- 3
我们可以发现:词频以一种明确的方式迅速衰减。 将前几个单词作为例外消除后,剩余的所有单词大致遵循双对数坐标图上的一条直线。
- 我们来看看二元语法的频率是否与一元语法的频率表现出相同的行为方式。
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
bigram_vocab.token_freqs[:10]
- 1
- 2
- 3
[(('of', 'the'), 309),
(('in', 'the'), 169),
(('i', 'had'), 130),
(('i', 'was'), 112),
(('and', 'the'), 109),
(('the', 'time'), 102),
(('it', 'was'), 99),
(('to', 'the'), 85),
(('as', 'i'), 78),
(('of', 'a'), 73)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里值得注意:在十个最频繁的词对中,有九个是由两个停用词组成的, 只有一个与“the time”有关。 我们再进一步看看三元语法的频率是否表现出相同的行为方式。
trigram_tokens = [triple for triple in zip(
corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
trigram_vocab.token_freqs[:10]
- 1
- 2
- 3
- 4
[(('the', 'time', 'traveller'), 59),
(('the', 'time', 'machine'), 30),
(('the', 'medical', 'man'), 24),
(('it', 'seemed', 'to'), 16),
(('it', 'was', 'a'), 15),
(('here', 'and', 'there'), 15),
(('seemed', 'to', 'me'), 14),
(('i', 'did', 'not'), 14),
(('i', 'saw', 'the'), 13),
(('i', 'began', 'to'), 13)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 最后,我们直观地对比三种模型中的词元频率:一元语法、二元语法和三元语法。
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
- 1
- 2
- 3
- 4
- 5
54.4 Reading Long Sequence Data
-
由于序列数据本质上是连续的,因此我们在处理数据时需要解决这个问题。在前几节中我们以一种相当特别的方式做到了这一点: 当序列变得太长而不能被模型一次性全部处理时, 我们可能希望拆分这样的序列方便模型读取。

54.5 Randomize Samples
- 在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列。 在迭代过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻。 对于语言建模,目标是基于到目前为止我们看到的词元来预测下一个词元, 因此标签是移位了一个词元的原始序列。下面的代码每次可以从数据中随机生成一个小批量。 在这里,参数
batch_size指定了每个小批量中子序列样本的数目, 参数num_steps是每个子序列中预定义的时间步数。
def seq_data_iter_random(corpus, batch_size, num_steps): #@save """使用随机抽样生成一个小批量子序列""" # 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1 corpus = corpus[random.randint(0, num_steps - 1):] # 减去1,是因为我们需要考虑标签 num_subseqs = (len(corpus) - 1) // num_steps # 长度为num_steps的子序列的起始索引 initial_indices = list(range(0, num_subseqs * num_steps, num_steps)) # 在随机抽样的迭代过程中, # 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻 random.shuffle(initial_indices) def data(pos): # 返回从pos位置开始的长度为num_steps的序列 return corpus[pos: pos + num_steps] num_batches = num_subseqs // batch_size for i in range(0, batch_size * num_batches, batch_size): # 在这里,initial_indices包含子序列的随机起始索引 initial_indices_per_batch = initial_indices[i: i + batch_size] X = [data(j) for j in initial_indices_per_batch] Y = [data(j + 1) for j in initial_indices_per_batch] yield torch.tensor(X), torch.tensor(Y)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 下面我们生成一个从0到34的序列。 假设批量大小为2,时间步数为5,这意味着可以生成 ⌊(35−1)/5⌋=6个“特征-标签”子序列对。 如果设置小批量大小为2,我们只能得到3个小批量。
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
- 1
- 2
- 3
顺序分区
- 在迭代过程中,除了对原始序列可以随机抽样外, 我们还可以保证两个相邻的小批量中的子序列在原始序列上也是相邻的。 这种策略在基于小批量的迭代过程中保留了拆分的子序列的顺序,因此称为顺序分区。
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 基于相同的设置,通过顺序分区读取每个小批量的子序列的特征
X和标签Y。 通过将它们打印出来可以发现: 迭代期间来自两个相邻的小批量中的子序列在原始序列中确实是相邻的。
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
- 1
- 2
- 现在,我们将上面的两个采样函数包装到一个类中, 以便稍后可以将其用作数据迭代器。
class SeqDataLoader: #@save
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.data_iter_fn = d2l.seq_data_iter_sequential
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 最后, 定义了一个函数
load_data_time_machine, 它同时返回数据迭代器和词表, 因此可以与其他带有load_data前缀的函数类似地使用。
def load_data_time_machine(batch_size, num_steps, #@save
use_random_iter=False, max_tokens=10000):
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab
- 1
- 2
- 3
- 4
- 5
- 6
55. Kaggle CowBoy achieve
55.1 Project URL
https://www.kaggle.com/competitions/cowboyoutfits
55.2 Download yolov5 and dependencies
!git clone https://github.com/ultralytics/yolov5 # clone repo
%cd yolov5
# Install dependencies
%pip install -qr requirements.txt # install dependencies
%cd ../
%pip install --upgrade torch
%pip install --upgrade torchvision
import torch
print(f"Setup complete. Using torch {torch.__version__} ({torch.cuda.get_device_properties(0).name if torch.cuda.is_available() else 'CPU'})")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
55.3 Data structure
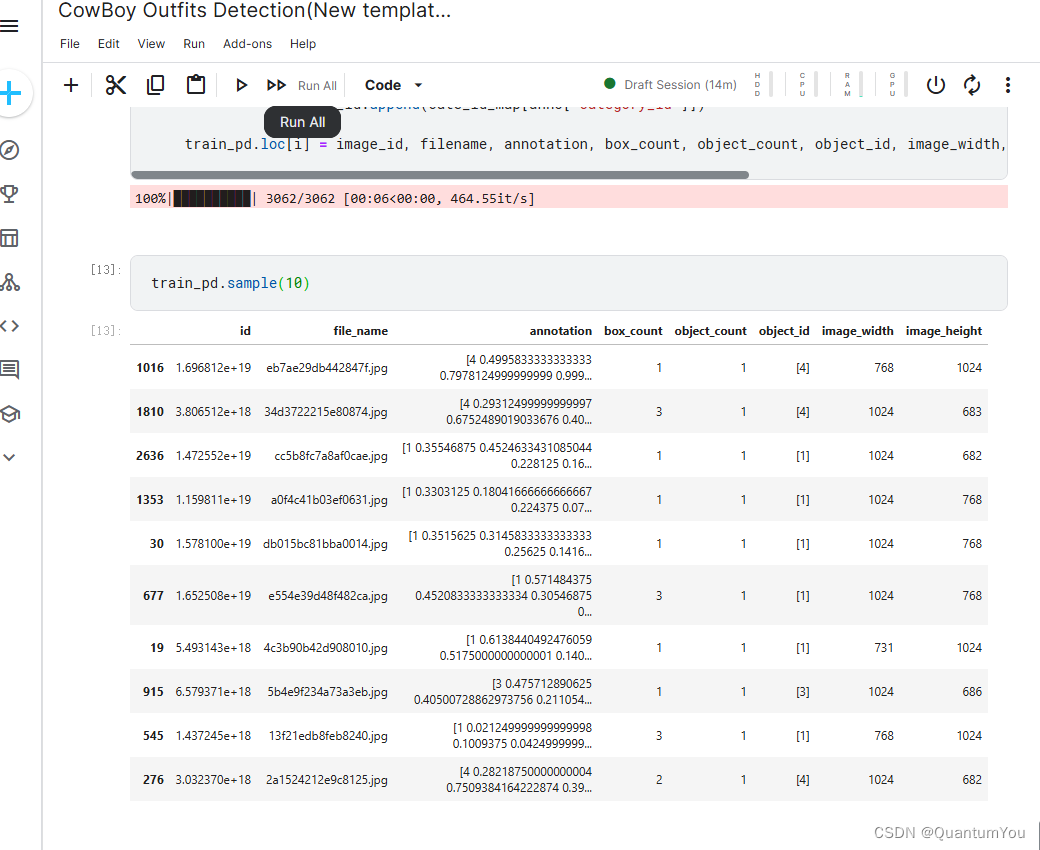
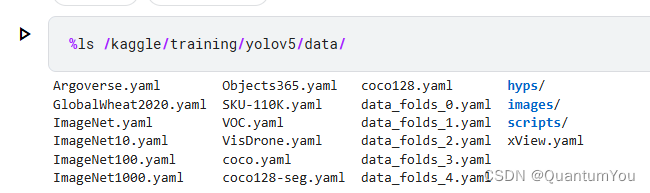
55.4 Run Start 声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

