
- 1数说CS | 入营不筛人,通过机试才能参加面试?天津大学智能与计算学部保研情况如何?_天津大学智能计算学部夏令营怎样考核
- 2php 区块链算法_PHP区块链(完整可运行,入门级)
- 3华为OD机试真题 Java 实现【最长子字符串的长度】【2022Q4 100分】,附详细解题思路_字符成环找偶数o
- 4RFID门禁系统(物联网关键技术应用)_测试rfid门禁系统
- 5Python GUI编程—Tkinter的常用控件_tkinter 控件
- 6Linux 运维工具之1Panel_修改1panel的密码
- 7集成学习-详细总结
- 8Unable to start the daemon process. This problem might be caused by incorrect configuration of the d
- 9探索与生存:Unreal Engine 4的C++示例项目——Survival Game
- 10JMU 数科 数据库与数据仓库期末总结(2)选择题_下列哪个选项描述的不是关系数据库的特点
mapreduce的cleanUp和setUp的特殊用法(TopN问题)和常规用法_setup cleanup
赞
踩
扫一扫加入大数据公众号和技术交流群,了解更多大数据技术,还有免费资料等你哦

特殊用法
我们上来不讲普通用法,普通用法放到最后。我们来谈一谈特殊用法,了解这一用法,让你的mapreduce编程能力提高一个档次,毫不夸张!!!扯淡了,让我们进入正题:
我们知道reduce和map都有一个局限性就是map是读一行执行一次,reduce是每一组执行一次,但是当我们想全部得到数据之后,按照需求删选然后再输出怎么办? 这时候只使用map和reduce显然是达不到目的的?那该怎么呢?这时候我们想到了 setUp和cleanUp的特性,只执行一次。这样我们对于最终数据的过滤,然后输出要放在cleanUp中。这样就能实现对数据,不一组一组输出,而是全部拿到,最后过滤输出。经典运用常见,mapreduce分析数据然后再求数据的topN 问题。
以求出单词出现次数前三名为例
MAPREDUCE求topn问题
以wordcount为例,求出单词出现数量前三名
数据:
- love you do
- you like me
- me like you do
- love you do
- you like me
- me like you do
- love you do
- you like me
- me like you do
- love you do
- you like me
分析:
我们知道mapreduce有分许聚合的功能,所以第一步就是:把每个单词读出来,然后在reduce中聚合,求出每个单词出现的次数但是怎么控制只输出前三名呢?我们知道,map是读一行执行一次,reduce是每一组执行一次所以只用map,和reduce是无法控制输出的次数的但是我们又知道,无论map或者reduce都有 setUp 和cleanUp而且这两个执行一次所以我们可以在reduce阶段把每一个单词当做key,单词出现的次数当做value,每一组存放到一个map里面,此时只存,不写出。在reduce的cleanUp阶,map排序,然后输出前三名
代码:
maper代码
- public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
-
- @Override
- protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
- throws IOException, InterruptedException {
- String[] split = value.toString().split(" ");
- for (String word : split) {
- context.write(new Text(word), new IntWritable(1));
-
- }}
- }
reduce代码
- public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
- Map<String,Integer> map=new HashMap<String, Integer>();
- protected void reduce(Text key, Iterable<IntWritable> iter,
- Reducer<Text, IntWritable, Text, IntWritable>.Context conext) throws IOException, InterruptedException {
- int count=0;
- for (IntWritable wordCount : iter) {
- count+=wordCount.get();
- }
- String name=key.toString();
- map.put(name, count);
- }
- @Override
- protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
- throws IOException, InterruptedException {
- //这里将map.entrySet()转换成list
- List<Map.Entry<String,Integer>> list=new LinkedList<Map.Entry<String,Integer>>(map.entrySet());
- //通过比较器来实现排序
- Collections.sort(list,new Comparator<Map.Entry<String,Integer>>() {
- //降序排序
- @Override
- public int compare(Entry<String, Integer> arg0,Entry<String, Integer> arg1) {
- return (int) (arg1.getValue() - arg0.getValue());
- }
- });
-
- for(int i=0;i<3;i++){
-
- context.write(new Text(list.get(i).getKey()), new IntWritable(list.get(i).getValue()));
-
- }
-
- }}
-
job客户端代码
- public class JobClient{
- public static void main(String[] args) throws Exception {
- Configuration conf = new Configuration();
- //conf.set("fs.defaultFS", "hdfs://wangzhihua1:9000/");
- conf.set("mapreduce.framework", "local");
- Job job = Job.getInstance(conf);
- // 封装本mr程序相关到信息到job对象中
- //job.setJar("d:/wc.jar");
- job.setJarByClass(JobClient.class);
- // 指定mapreduce程序用jar包中的哪个类作为Mapper逻辑类
- job.setMapperClass(WcMapper.class);
- // 指定mapreduce程序用jar包中的哪个类作为Reducer逻辑类
- job.setReducerClass(WcReducer.class);
- // 告诉mapreduce程序,我们的map逻辑输出的KEY.VALUE的类型
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- // 告诉mapreduce程序,我们的reduce逻辑输出的KEY.VALUE的类型
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- // 告诉mapreduce程序,我们的原始文件在哪里
- FileInputFormat.setInputPaths(job, new Path("d:/wc/input/"));
- // 告诉mapreduce程序,结果数据往哪里写
- FileOutputFormat.setOutputPath(job, new Path("d:/wc/output/"));
- // 设置reduce task的运行实例数
- job.setNumReduceTasks(1); // 默认是1
- // 调用job对象的方法来提交任务
- job.submit();
- }
-
- }
-
常规用法
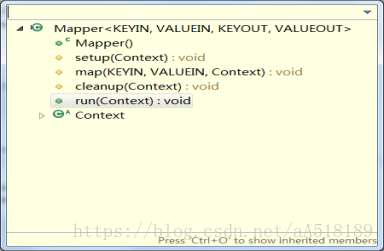
在hadoop的源码中,基类Mapper类和Reducer类中都是只包含四个方法:setup方法,cleanup方法,run方法,map方法。如下所示:
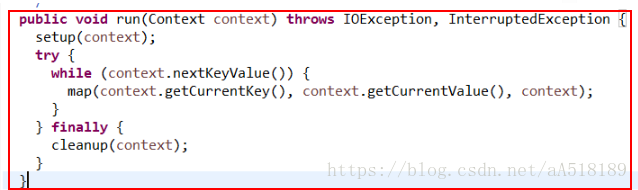
其方法的调用方式是在run方法中,如下所示:
可以看出,在run方法中调用了上面的三个方法:setup方法,map方法,cleanup方法。其中setup方法和cleanup方法默认是不做任何操作,且它们只被执行一次。但是setup方法一般会在map函数之前执行一些准备工作,如作业的一些配置信息等;cleanup方法则是在map方法运行完之后最后执行 的,该方法是完成一些结尾清理的工作,如:资源释放等。如果需要做一些配置和清理的工作,需要在Mapper/Reducer的子类中进行重写来实现相应的功能。map方法会在对应的子类中重新实现,就是我们自定义的map方法。该方法在一个while循环里面,表明该方法是执行很多次的。run方法就是每个maptask调用的方
hadoop中的MapReduce框架里已经预定义了相关的接口,其中如Mapper类下的方法setup()和cleanup()。
setup(),此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
cleanup(),此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。若是将释放资源工作放入方法map()中,也会导致Mapper任务在解析、处理每一行文本后释放资源,而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高!
所以,建议资源初始化及释放工作,分别放入方法setup()和cleanup()中进行。

