
- 1币区块结构解析
- 2性能工具之 JMeter 自定义 Java Sampler 支持国密 SM2 算法_jmeter 国密加密
- 32021年第五届集创赛Arm杯报名/提问/培训视频/历年获奖资料汇总_arm杯赛道
- 4BurpSuite工具的介绍、下载、安装和使用_burpsuite重放器
- 5AI作画算法详解:原理、应用与未来发展_ai 算法图像化说明
- 6ElasticSearch全文搜索引擎
- 7毕业设计:基于B站用户行为分析系统 哔哩哔哩 bilibili 数据可视化 Django框架(源码+文档)✅_哔哩哔哩用户数据分析
- 8LAMP集群分布式安全方案
- 9算法数据结构基础——图(Graph)_graph计算
- 10一文完成Jupyter Notebook的安装和初识(初学者进)_jupyter notebook 重装 navigater
计算机网络——网络传输优化实战_tcp syncookies
赞
踩
摘要
博文将详细的介绍网络传输优化的原理与实战。提供一些网络传输的优化的实例,给大家在工作中一些参考。
一、TCP的连接原理
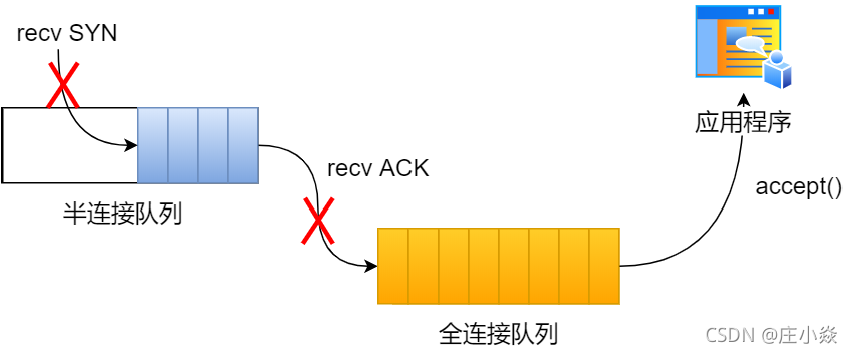
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
- 半连接队列,也称 SYN 队列;
- 全连接队列,也称 accepet 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
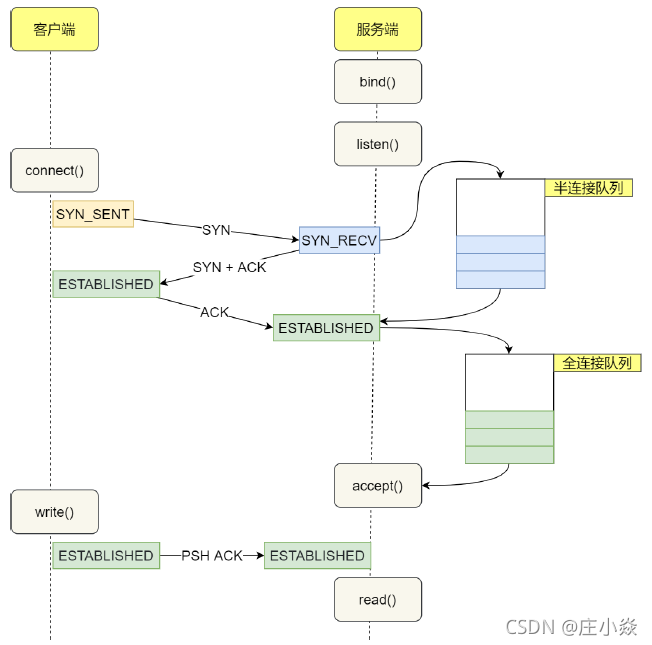
不管是半连接队列还是全连接队列,都有最大长度限制,超过限制时,内核会直接丢弃,或返回 RST包。
1.1 实战 - TCP全连接队列溢出
如何知道应用程序的 TCP 全连接队列大小?在服务端可以使用 ss 命令,来查看 TCP 全连接队列的情况:但需要注意的是 ss 命令获取的 Recv-Q/Send-Q 在「LISTEN 状态」和「非 LISTEN 状态」所表达的含义是不同的。从下面的内核代码可以看出区别:
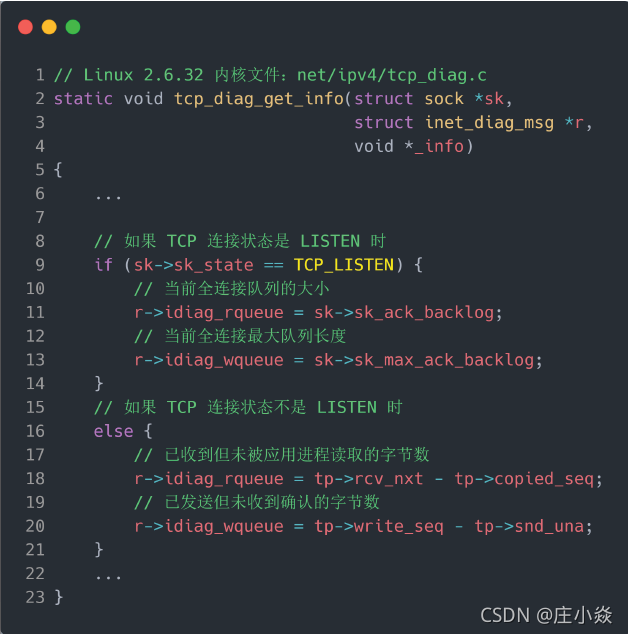
在「LISTEN 状态」时, Recv-Q/Send-Q 表示的含义如下:
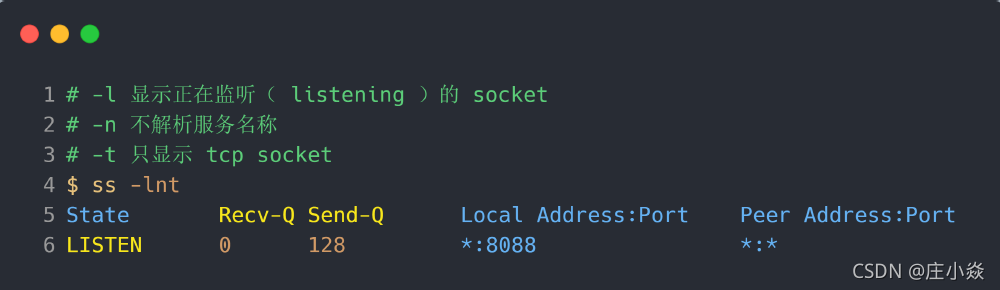
- Recv-Q:当前全连接队列的大小,也就是当前已完成三次握手并等待服务端 accept() 的 TCP 连接;
- Send-Q:当前全连接最大队列长度,上面的输出结果说明监听 8088 端口的 TCP 服务,最大全连接长度为 128;
在「非 LISTEN 状态」时, Recv-Q/Send-Q 表示的含义如下:
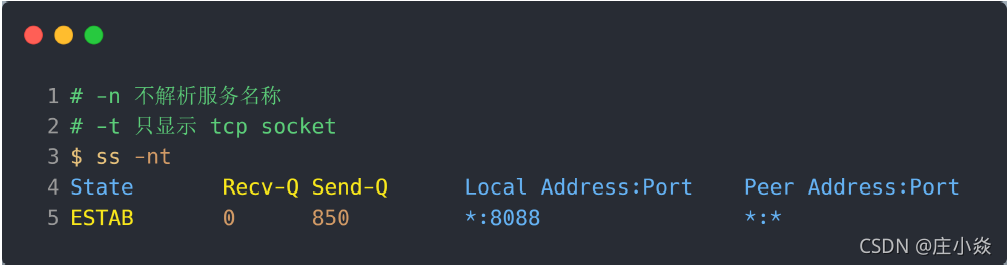
- Recv-Q:已收到但未被应用进程读取的字节数;
- Send-Q:已发送但未收到确认的字节数;
1.2 如何模拟 TCP 全连接队列溢出的场景?
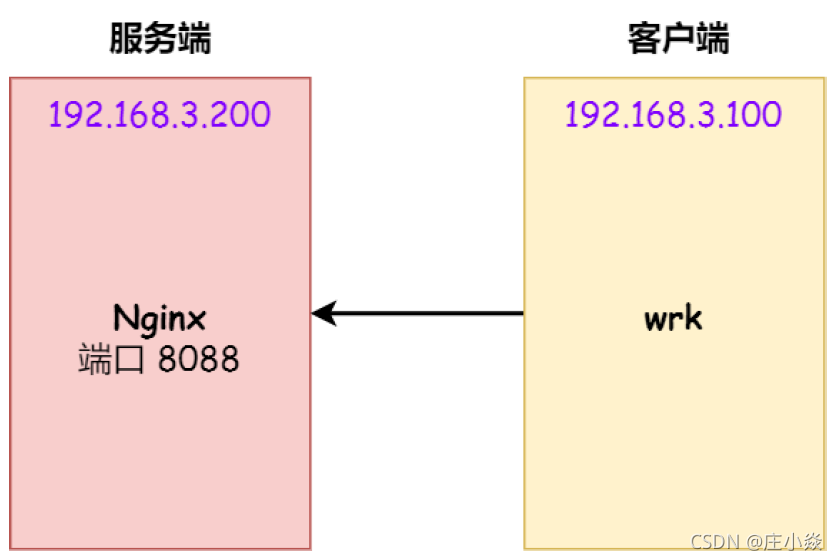
实验环境:
- 客户端和服务端都是 CentOs 6.5 ,Linux 内核版本 2.6.32
- 服务端 IP 192.168.3.200,客户端 IP 192.168.3.100
- 服务端是 Nginx 服务,端口为 8088
这里先介绍下 wrk 工具,它是一款简单的 HTTP 压测工具,它能够在单机多核 CPU 的条件下,使用系统自带的高性能 I/O 机制,通过多线程和事件模式,对目标机器产生大量的负载。
本次模拟实验就使用 wrk 工具来压力测试服务端,发起大量的请求,一起看看服务端 TCP 全连接队列满了会发生什么?有什么观察指标?
客户端执行 wrk 命令对服务端发起压力测试,并发 3 万个连接:

在服务端可以使用 ss 命令,来查看当前 TCP 全连接队列的情况:

其间共执行了两次 ss 命令,从上面的输出结果,可以发现当前 TCP 全连接队列上升到了 129 大小,超过了最大 TCP 全连接队列。
当超过了 TCP 最大全连接队列,服务端则会丢掉后续进来的 TCP 连接,丢掉的 TCP 连接的个数会被统计起来,我们可以使用 netstat -s 命令来查看:

上面看到的 41150 times ,表示全连接队列溢出的次数,注意这个是累计值。可以隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
从上面的模拟结果,可以得知,当服务端并发处理大量请求时,如果 TCP 全连接队列过小,就容易溢出。发生 TCP 全连接队溢出的时候,后续的请求就会被丢弃,这样就会出现服务端请求数量上不去的现象。
TCP 全连接队列满了会使用什么策略来回应客户端。
实际上,丢弃连接只是 Linux 的默认行为,我们还可以选择向客户端发送 RST 复位报文,告诉客户端连接已经建立失败。
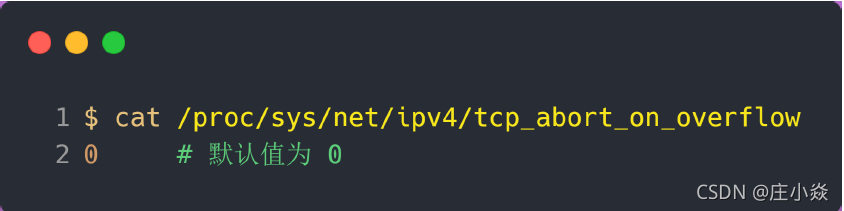
tcp_abort_on_overflow 共有两个值分别是 0 和 1,其分别表示:
- 0 :如果全连接队列满了,那么 server 扔掉 client 发过来的 ack ;
- 1 :如果全连接队列满了,server 发送一个 reset 包给 client,表示废掉这个握手过程和这个连接;
如果要想知道客户端连接不上服务端,是不是服务端 TCP 全连接队列满的原因,那么可以把tcp_abort_on_overflow 设置为 1,这时如果在客户端异常中可以看到很多 connection reset by peer 的错误,那么就可以证明是由于服务端 TCP 全连接队列溢出的问题。
通常情况下,应当把 tcp_abort_on_overflow 设置为 0,因为这样更有利于应对突发流量。
举个例子,当 TCP 全连接队列满导致服务器丢掉了 ACK,与此同时,客户端的连接状态却是ESTABLISHED,进程就在建立好的连接上发送请求。只要服务器没有为请求回复 ACK,请求就会被多次重发。如果服务器上的进程只是短暂的繁忙造成 accept 队列满,那么当 TCP 全连接队列有空位时,再次接收到的请求报文由于含有 ACK,仍然会触发服务器端成功建立连接。
所以,tcp_abort_on_overflow 设为 0 可以提高连接建立的成功率,只有你非常肯定 TCP 全连接队列会长期溢出时,才能设置为 1 以尽快通知客户端。
如何增大 TCP 全连接队列呢?
是的,当发现 TCP 全连接队列发生溢出的时候,我们就需要增大该队列的大小,以便可以应对客户端大量的请求。
TCP 全连接队列的最大值取决于 somaxconn 和 backlog 之间的最小值,也就是 min(somaxconn,backlog)。从下面的 Linux 内核代码可以得知:
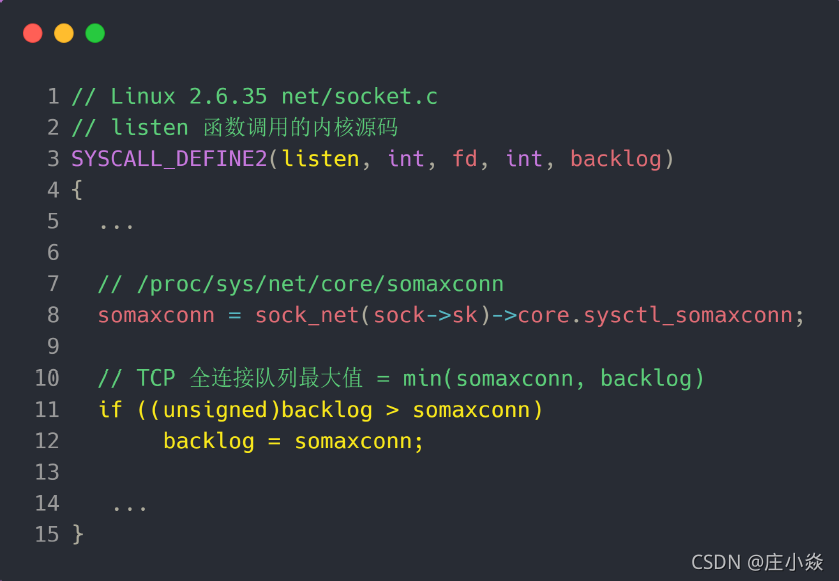
- somaxconn 是 Linux 内核的参数,默认值是 128,可以通过 /proc/sys/net/core/somaxconn 来设置其值;
- backlog 是 listen(int sockfd, int backlog) 函数中的 backlog 大小,Nginx 默认值是 511,可以通过修改配置文件设置其长度;
前面模拟测试中,我的测试环境:
- somaxconn 是默认值 128;
- Nginx 的 backlog 是默认值 511
所以测试环境的 TCP 全连接队列最大值为 min(128, 511),也就是 128 ,可以执行 ss 命令查看:
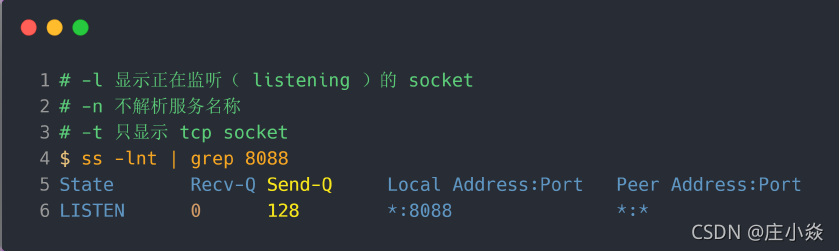
现在我们重新压测,把 TCP 全连接队列搞大,把 somaxconn 设置成 5000:

接着把 Nginx 的 backlog 也同样设置成 5000:
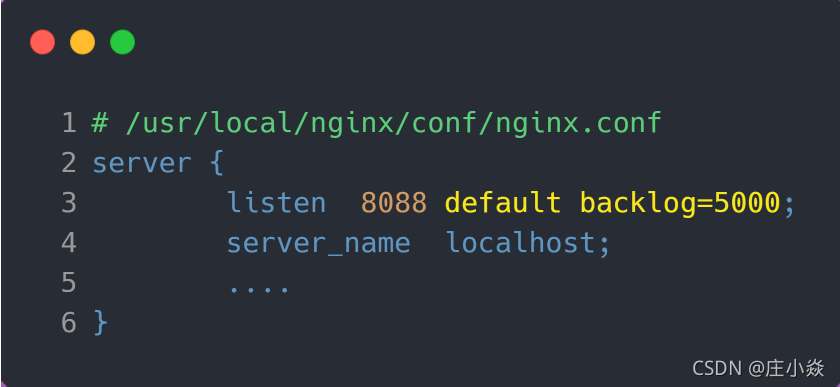
最后要重启 Nginx 服务,因为只有重新调用 listen() 函数 TCP 全连接队列才会重新初始化。重启完后 Nginx 服务后,服务端执行 ss 命令,查看 TCP 全连接队列大小:
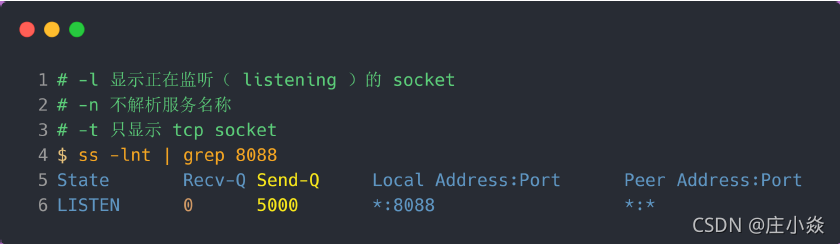
从执行结果,可以发现 TCP 全连接最大值为 5000。
增大 TCP 全连接队列后,继续压测
客户端同样以 3 万个连接并发发送请求给服务端:

服务端执行 ss 命令,查看 TCP 全连接队列使用情况

从上面的执行结果,可以发现全连接队列使用增长的很快,但是一直都没有超过最大值,所以就不会溢出,那么 netstat -s 就不会有 TCP 全连接队列溢出个数的显示:

说明 TCP 全连接队列最大值从 128 增大到 5000 后,服务端抗住了 3 万连接并发请求,也没有发生全连接队列溢出的现象了。
如果持续不断地有连接因为 TCP 全连接队列溢出被丢弃,就应该调大 backlog 以及 somaxconn 参数。
实战 - TCP 半连接队列溢出
如何查看 TCP 半连接队列长度?
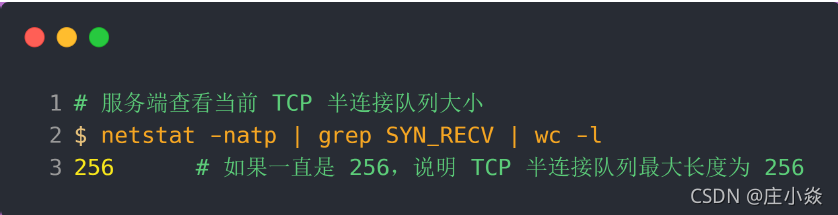
TCP 半连接队列长度的长度,没有像全连接队列那样可以用 ss 命令查看。但是我们可以抓住 TCP 半连接的特点,就是服务端处于 SYN_RECV 状态的 TCP 连接,就是 TCP 半连接队列。于是,我们可以使用如下命令计算当前 TCP 半连接队列长度:
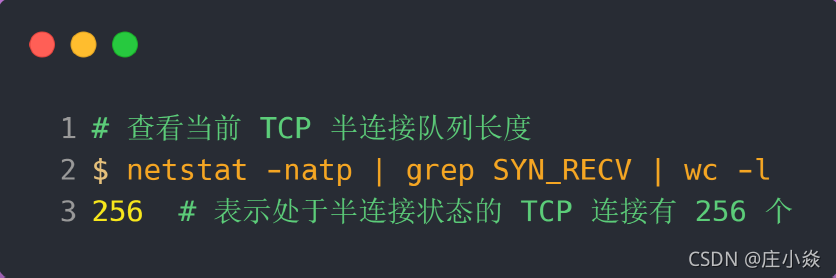
如何模拟 TCP 半连接队列溢出场景?
模拟 TCP 半连接溢出场景不难,实际上就是对服务端一直发送 TCP SYN 包,但是不回第三次握手ACK,这样就会使得服务端有大量的处于 SYN_RECV 状态的 TCP 连接。这其实也就是所谓的 SYN 洪泛、SYN 攻击、DDos 攻击。
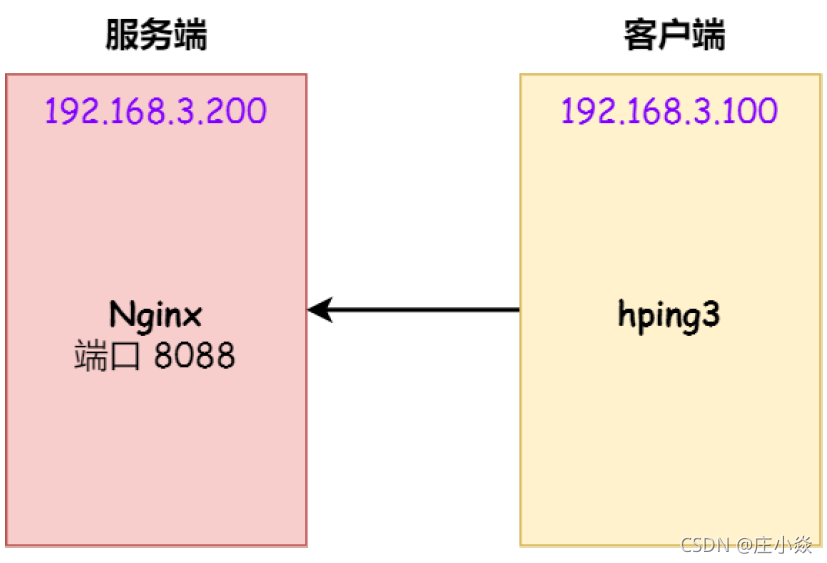
实验环境:
- 客户端和服务端都是 CentOs 6.5 ,Linux 内核版本 2.6.32
- 服务端 IP 192.168.3.200,客户端 IP 192.168.3.100
- 服务端是 Nginx 服务,端口为 8088
注意:本次模拟实验是没有开启 tcp_syncookies,关于 tcp_syncookies 的作用,后续会说明。
本次实验使用 hping3 工具模拟 SYN 攻击:

当服务端受到 SYN 攻击后,连接服务端 ssh 就会断开了,无法再连上。只能在服务端主机上执行查看当前 TCP 半连接队列大小:
同时,还可以通过 netstat -s 观察半连接队列溢出的情况:
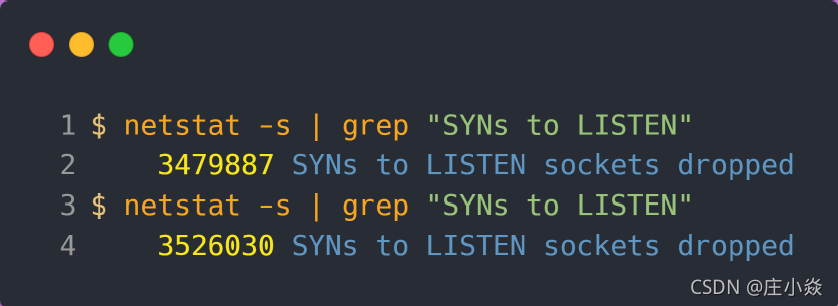
上面输出的数值是累计值,表示共有多少个 TCP 连接因为半连接队列溢出而被丢弃。隔几秒执行几次,如果有上升的趋势,说明当前存在半连接队列溢出的现象。
tcp_max_syn_backlog 是指定半连接队列的大小?
半连接队列的大小并不单单只跟 tcp_max_syn_backlog 有关系。上面模拟 SYN 攻击场景时,服务端的 tcp_max_syn_backlog 的默认值如下:
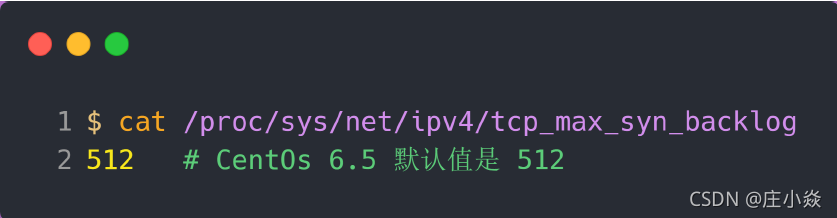
但是在测试的时候发现,服务端最多只有 256 个半连接队列,而不是 512,所以半连接队列的最大长度不一定由 tcp_max_syn_backlog 值决定的。
TCP 半连接队列的最大值是如何决定的。
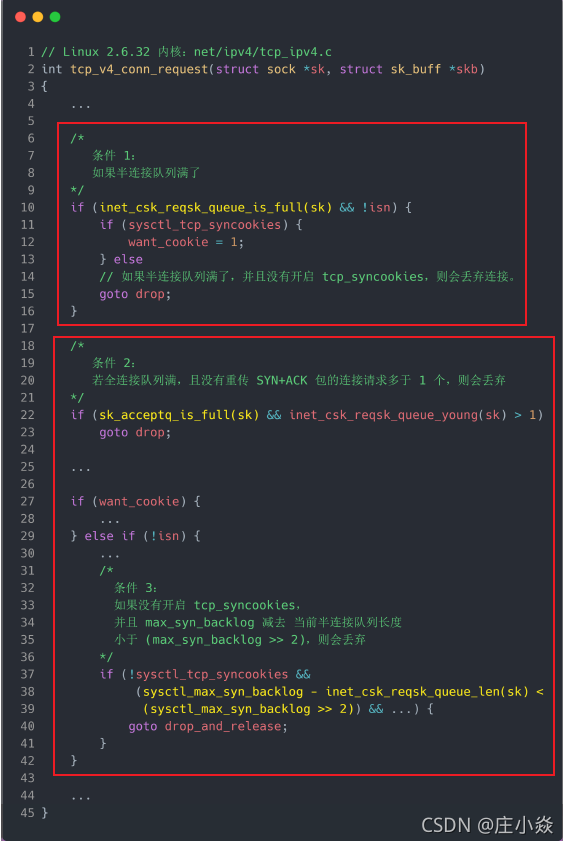
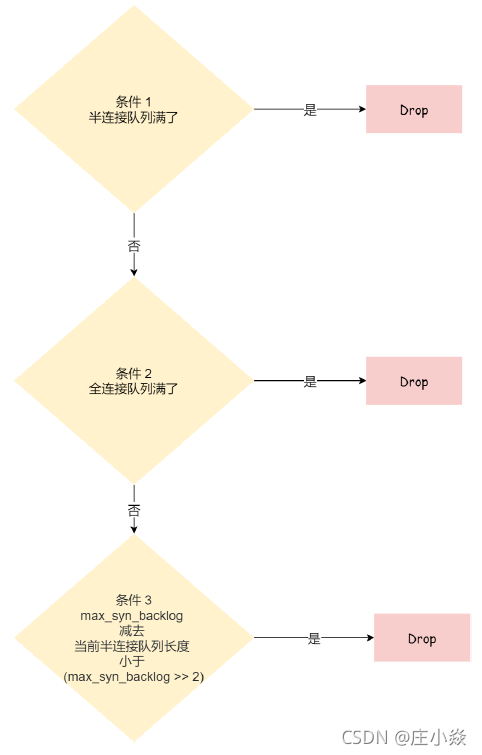
- 1. 如果半连接队列满了,并且没有开启 tcp_syncookies,则会丢弃;
- 2. 若全连接队列满了,且没有重传 SYN+ACK 包的连接请求多于 1 个,则会丢弃;
- 3. 如果没有开启 tcp_syncookies,并且 max_syn_backlog 减去 当前半连接队列长度小于(max_syn_backlog >> 2),则会丢弃;
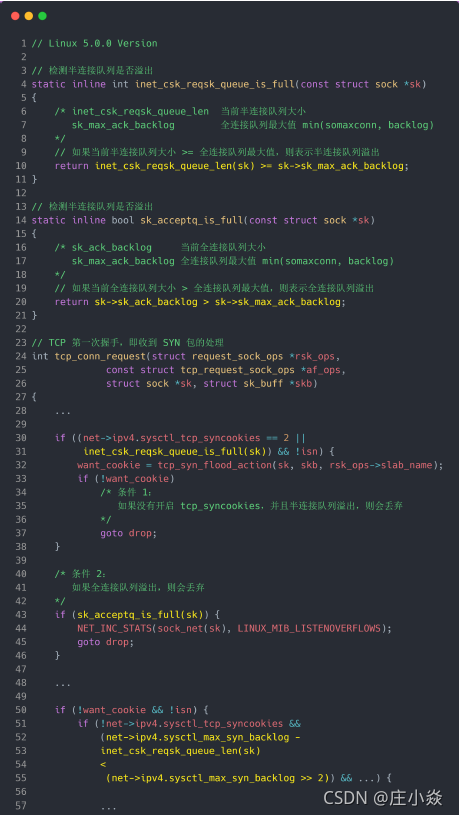
接下来,我们继续跟一下检测半连接队列是否满的函数 inet_csk_reqsk_queue_is_full 和 检测全连接队列是否满的函数 sk_acceptq_is_full :
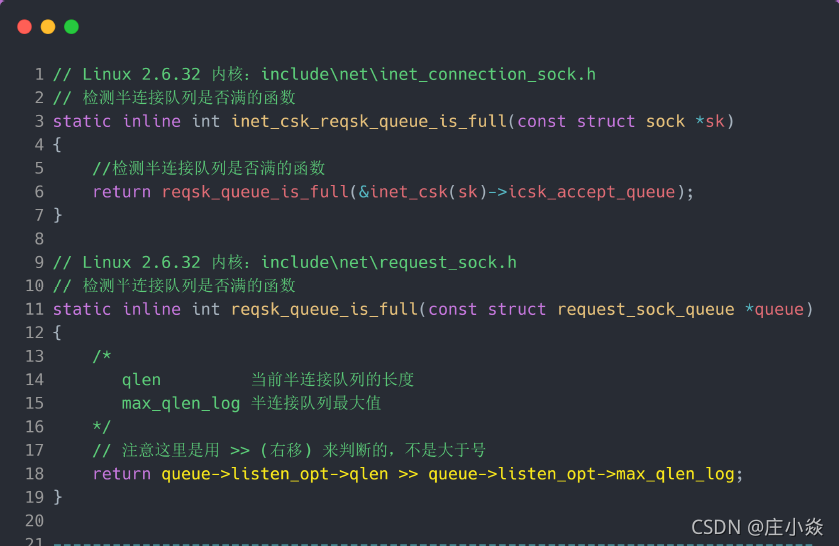

从上面源码,可以得知:
- 全连接队列的最大值是 sk_max_ack_backlog 变量,sk_max_ack_backlog 实际上是在 listen() 源码里指定的,也就是 min(somaxconn, backlog);
- 半连接队列的最大值是 max_qlen_log 变量,max_qlen_log 是在哪指定的呢?现在暂时还不知道,我们继续跟进;
我们继续跟进代码,看一下是哪里初始化了半连接队列的最大值 max_qlen_log:
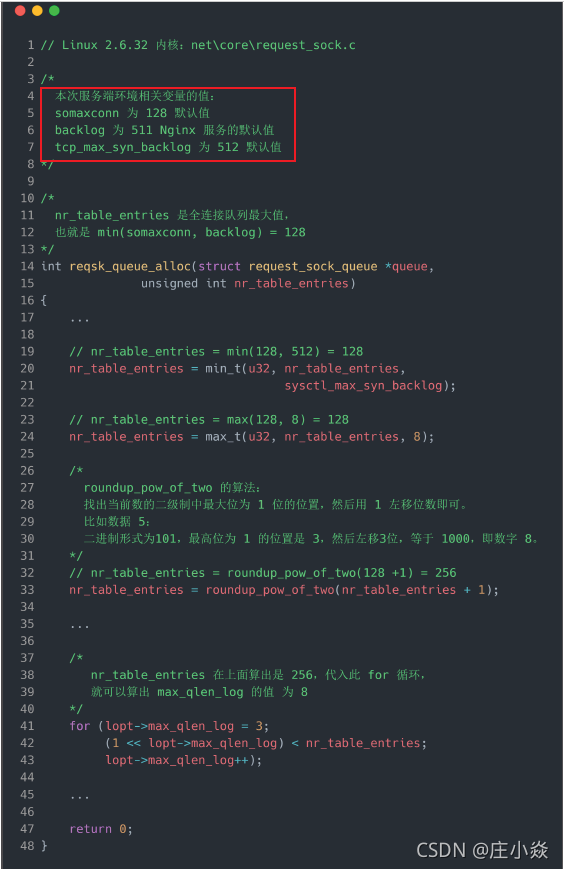
从上面的代码中,我们可以算出 max_qlen_log 是 8,于是代入到 检测半连接队列是否满的函数
reqsk_queue_is_full :

也就是 qlen >> 8 什么时候为 1 就代表半连接队列满了。这计算这不难,很明显是当 qlen 为 256
时, 256 >> 8 = 1 。至此,总算知道为什么上面模拟测试 SYN 攻击的时候,服务端处于 SYN_RECV 连接最大只有 256个。可见,半连接队列最大值不是单单由 max_syn_backlog 决定,还跟 somaxconn 和 backlog 有关系。
在 Linux 2.6.32 内核版本,它们之间的关系,总体可以概况为:
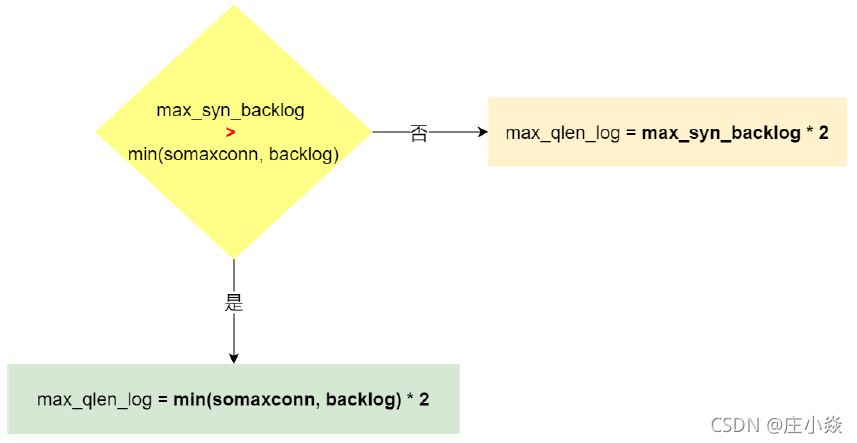
- 当 max_syn_backlog > min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log =min(somaxconn, backlog) * 2;
- 当 max_syn_backlog < min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log =max_syn_backlog * 2;
半连接队列最大值 max_qlen_log 就表示服务端处于 SYN_REVC 状态的最大个数吗?
max_qlen_log 是理论半连接队列最大值,不一定代表服务端处于 SYN_REVC 状态的最大个数。
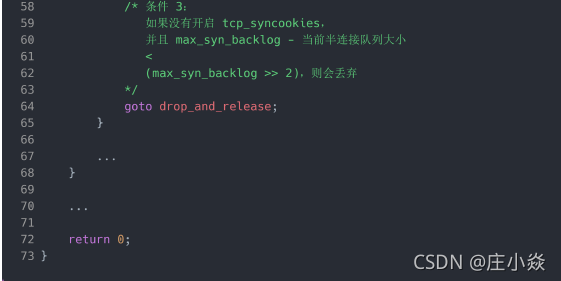
在前面我们在分析 TCP 第一次握手(收到 SYN 包)时会被丢弃的三种条件:
- 1. 如果半连接队列满了,并且没有开启 tcp_syncookies,则会丢弃;
- 2. 若全连接队列满了,且没有重传 SYN+ACK 包的连接请求多于 1 个,则会丢弃;
- 3. 如果没有开启 tcp_syncookies,并且 max_syn_backlog 减去 当前半连接队列长度小于(max_syn_backlog >> 2),则会丢弃;
假设条件 1 当前半连接队列的长度 「没有超过」理论的半连接队列最大值 max_qlen_log,那么如果条件3成立,则依然会丢弃 SYN 包,也就会使得服务端处于 SYN_REVC 状态的最大个数不会是理论值max_qlen_log。
服务端环境如下:
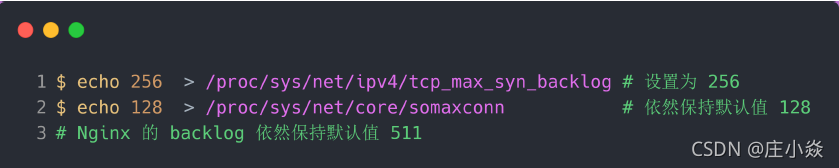
配置完后,服务端要重启 Nginx,因为全连接队列最大值和半连接队列最大值是在 listen() 函数初始化。根据前面的源码分析,我们可以计算出半连接队列 max_qlen_log 的最大值为 256:

客户端执行 hping3 发起 SYN 攻击:

服务端执行如下命令,查看处于 SYN_RECV 状态的最大个数:
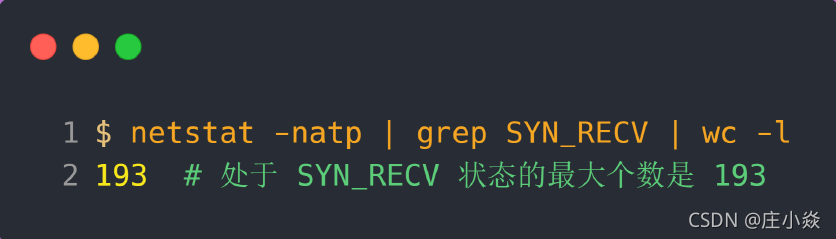
可以发现,服务端处于 SYN_RECV 状态的最大个数并不是 max_qlen_log 变量的值。
这就是前面所说的原因:如果当前半连接队列的长度 「没有超过」理论半连接队列最大值max_qlen_log,那么如果条件 3 成立,则依然会丢弃 SYN 包,也就会使得服务端处于 SYN_REVC状态的最大个数不会是理论值 max_qlen_log。
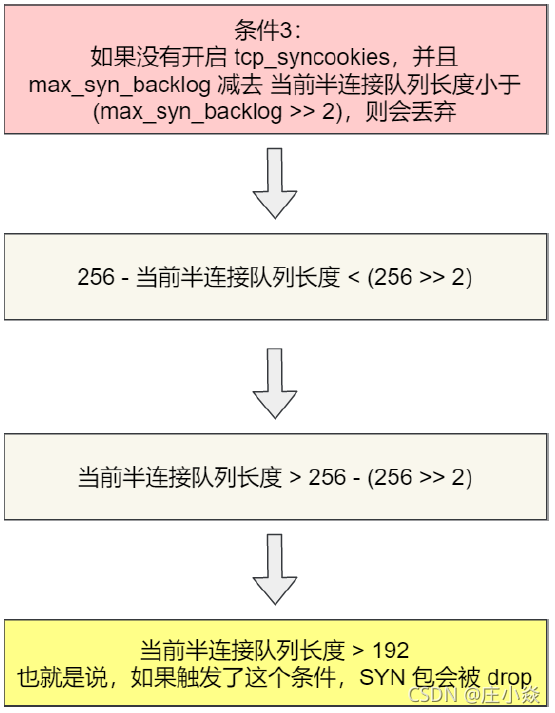
从上面的分析,可以得知如果触发「当前半连接队列长度 > 192」条件,TCP 第一次握手的 SYN 包是会被丢弃的。在前面我们测试的结果,服务端处于 SYN_RECV 状态的最大个数是 193,正好是触发了条件 3,所以处于 SYN_RECV 状态的个数还没到「理论半连接队列最大值 256」,就已经把 SYN 包丢弃了。
所以,服务端处于 SYN_RECV 状态的最大个数分为如下两种情况:
- 如果「当前半连接队列」没超过「理论半连接队列最大值」,但是超过 max_syn_backlog -(max_syn_backlog >> 2),那么处于 SYN_RECV 状态的最大个数就是 max_syn_backlog -(max_syn_backlog >> 2);
- 如果「当前半连接队列」超过「理论半连接队列最大值」,那么处于 SYN_RECV 状态的最大个数就是「理论半连接队列最大值」;
每个 Linux 内核版本「理论」半连接最大值计算方式会不同
在上面我们是针对 Linux 2.6.32 版本分析的「理论」半连接最大值的算法,可能每个版本有些不同。比如在 Linux 5.0.0 的时候,「理论」半连接最大值就是全连接队列最大值,但依然还是有队列溢出的三个条件:
如果 SYN 半连接队列已满,只能丢弃连接吗?
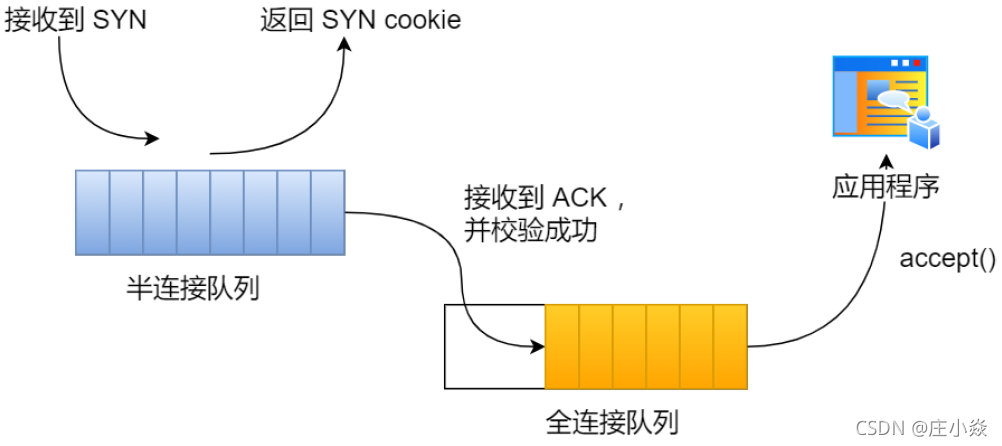
并不是这样,开启 syncookies 功能就可以在不使用 SYN 半连接队列的情况下成功建立连接,在前面我们源码分析也可以看到这点,当开启了 syncookies 功能就不会丢弃连接。
syncookies 是这么做的:服务器根据当前状态计算出一个值,放在己方发出的 SYN+ACK 报文中发出,当客户端返回 ACK 报文时,取出该值验证,如果合法,就认为连接建立成功,如图所示。
syncookies 参数主要有以下三个值:
- 0 值,表示关闭该功能;
- 1 值,表示仅当 SYN 半连接队列放不下时,再启用它;
- 2 值,表示无条件开启功能;
那么在应对 SYN 攻击时,只需要设置为 1 即可:

如何防御 SYN 攻击?
这里给出几种防御 SYN 攻击的方法:
增大半连接队列;
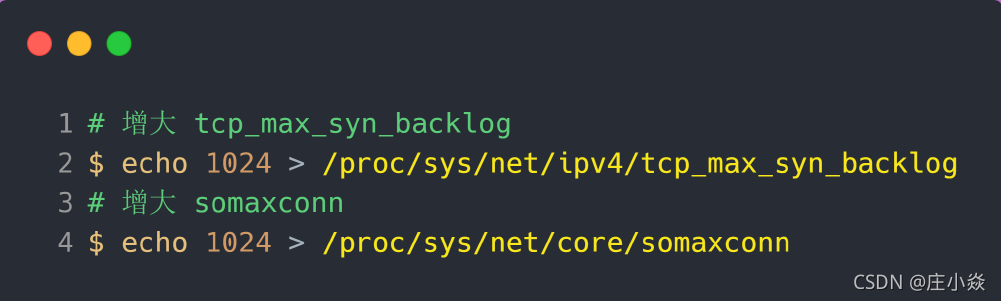
得知要想增大半连接队列,我们得知不能只单纯增大 tcp_max_syn_backlog 的值,还需一同增大 somaxconn 和 backlog,也就是增大全连接队列。否则,只单纯增大tcp_max_syn_backlog 是无效的。增大 tcp_max_syn_backlog 和 somaxconn 的方法是修改 Linux 内核参数:
增大 backlog 的方式,每个 Web 服务都不同,比如 Nginx 增大 backlog 的方法如下:
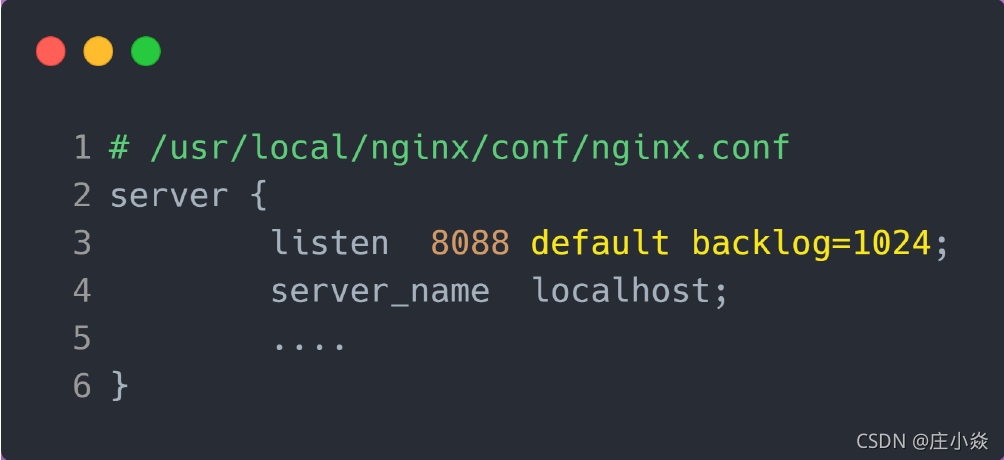
最后,改变了如上这些参数后,要重启 Nginx 服务,因为半连接队列和全连接队列都是在 listen() 初始化的。
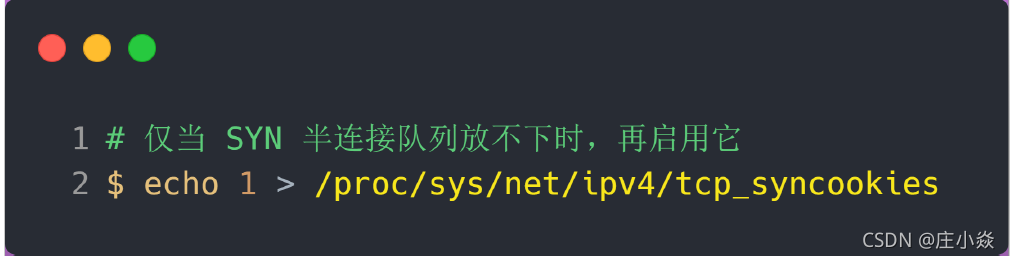
开启 tcp_syncookies 功能
开启 tcp_syncookies 功能的方式也很简单,修改 Linux 内核参数:
减少 SYN+ACK 重传次数
当服务端受到 SYN 攻击时,就会有大量处于 SYN_REVC 状态的 TCP 连接,处于这个状态的 TCP 会重传 SYN+ACK ,当重传超过次数达到上限后,就会断开连接。
那么针对 SYN 攻击的场景,我们可以减少 SYN+ACK 的重传次数,以加快处于 SYN_REVC 状态的TCP 连接断开。

博文参考
- 系统性能调优必知必会.陶辉.极客时间.
- https://www.cnblogs.com/zengkefu/p/5606696.html
- https://blog.cloudflare.com/syn-packet-handling-in-the-wild/


