
- 1InfiniBand(IB网络交换机)_ib交换机
- 2【redis】redix在Linux下的环境配置和redis的全局命令_redis linux 查询命令
- 3RocketMq
- 4Nacos+ApiSix docker 集群环境搭建(docker-compose方式)_apisix nacos
- 5python tkinter控件_Python TKinter布局管理Place()Grid Pack详解
- 6【分析笔记】Linux gpio_wdt.c 看门狗设备驱动源码分析_wdt linux 驱动
- 7JS原生再现黑客帝国文字矩阵_字符矩阵js
- 8三十四、Hive常用的函数_hive version函数
- 9解决异常【MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transaction】_cause: com.mysql.jdbc.exceptions.jdbc4.mysqltransa
- 10Fisco开发第一个区块链应用
yolov3权重文件_小白笔记:动手做目标检测 --> YOLO v3(二)
赞
踩
前言
上期给大家讲述了一些关于我的学习经历,本期会和大家一起探讨目标检测算法。
作为小白笔记的开篇作,我会非常认真地讲述YOLO v3算法,并且确保所有代码都可以正常使用。有任何不同的见解都欢迎大家及时私信我。
学习目标检测的那点事儿
咱们长话短说。
我也是最近一个多月时间开始接触深度学习的计算机视觉。大家可能知道,我学的是车辆工程专业,并非科班出身。那么我刚开始学习图像分类时,就几乎不会遇到什么困难,短时间内就学完了《深度学习之PyTorch实战计算机视觉》这本书。但当我开始从图像分类过渡到目标检测时,却面临了很多痛苦和挣扎。首先我根本无法正常运行书上的代码,其次是巨大的代码量让我苦不堪言。
从Faster RCNN到SSD再到后来的YOLO v3,我用了很长时间去研究前两种算法的原理和代码,但都失败了。不怕大家笑话,为了看懂前两种算法的原理和代码,我从PyTorch框架又转到Keras,后来都放弃了。
但我总得做出来一种吧,我就咬牙坚持学习YOLO v3算法。几百行代码我都是一行一行地运行,一行一行地写注释,经过几天挣扎之后,最终成功了。因此关于目标检测,我首先给大家讲解YOLO v3算法。
给大家分享一句话:人在追求中纵然迷惘,却终将意识到有一条正途。
YOLO v3算法组成及原理
组成
这几种经典的目标检测算法在整体上组成部分都是一样的,只是存在着原理上的不同。
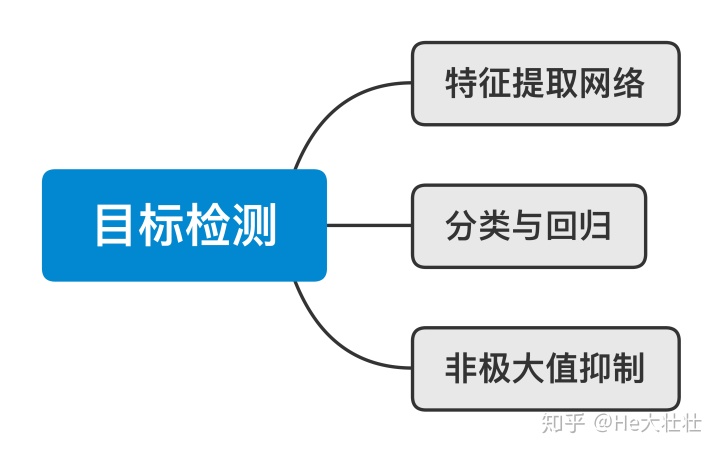
- 特征提取网络:提取输入图像的核心特征
- 分类与回归:检测物体位置及其类别
- 非极大值抑制:对同一物体检测到的多个位置按照置信度进行筛选
原理
想搞清YOLO v3的原理,咱们看懂两张图就行。
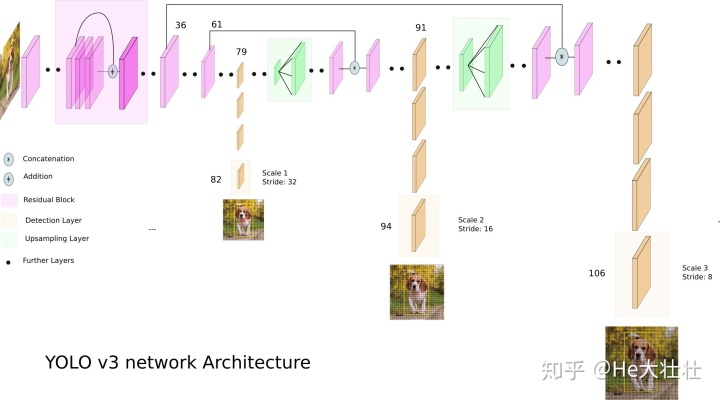
YOLO v3的特征提取网络采用DarkNet-53结构,其具体结构如下:
- “至暗卷积层”:由Convolutional Layer、Batch Normalize和LeakyReLu等模块组成
- Upsampling Layer:上采样层,将图像尺寸扩大
- Residual Block:残差模块,解决深度数据网络难以训练的问题
- Route Layer:将第36层和第61层分别于后面某层融合
- Detection Layer:输出特征图feature map,可见在特征提取网络的第82、第94和第106层输出
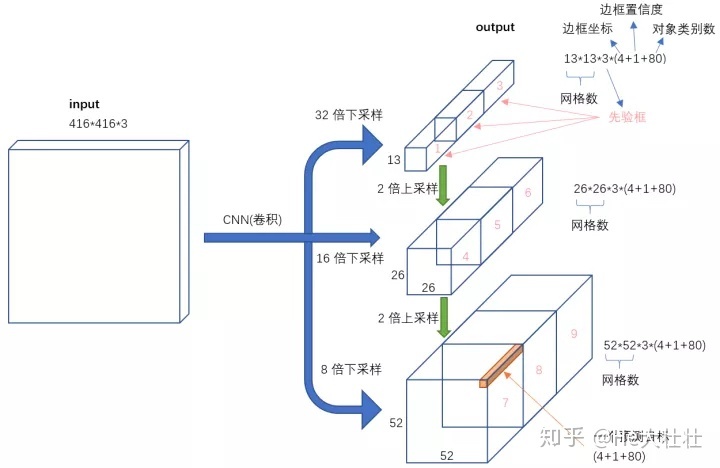
其中第82层输出的尺寸为(13,13),第94层输出的尺寸为(26,26),第106层输出的尺寸为(52,52),每一层都将被不同尺寸的锚框anchors处理。
具体细节将在代码里体现。
希望大家无论在读原理还是写代码,都能把这两张图放身边,加强理解。
准备工作
本系列YOLO v3目标检测算法所使用的源码来自GitHub,链接:
ayooshkathuria/YOLO_v3_tutorial_from_scratchgithub.com权重文件链接:
https://pjreddie.com/media/files/yolov3.weightspjreddie.com本系列代码先由Jupyter Lab编写再放置yolo.ipynb上进行组装,理由如下:
- 对小白而言,Jupyter Notebook或者Jupyter Lab界面都十分友好
- Jupyter Lab的代码块可以逐个运行和输出,方便我们理解
版本信息:
- Python --> 3.7.4
- PyTorch --> 1.4.0
- Opencv --> 4.1.2.30
文件总览
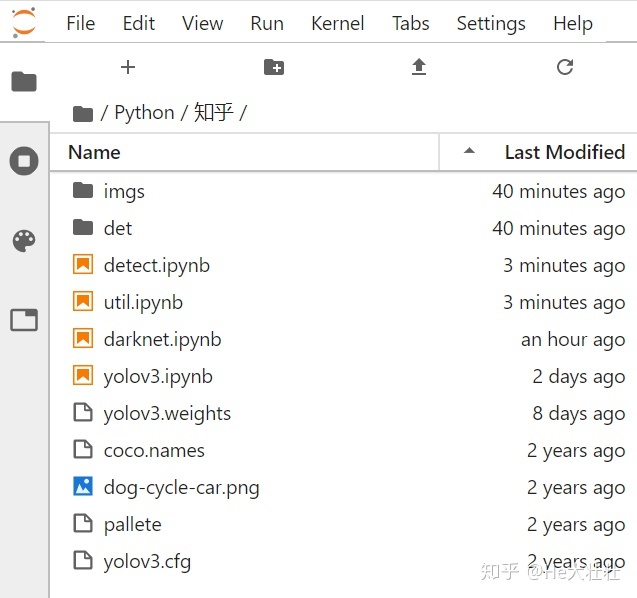
- imgs --> 存放输入图像
- det --> 存放输出图像
- darknet.ipynb --> 构建特征提取网络
- util.ipynb --> 存放特征变换、非极大值抑制等函数
- detect.ipynb --> 构建输入和输出流程
- yolov3.weights --> 权重文件
- coco.names --> 存放COCO数据集的类别
- pallete --> 存放颜色
- yolov3.cfg --> 特征提取网络配置文件
darknet.ipynb
导入第三方库
- from __future__ import division
- import torch
- import torchvision

