
- 1【Git】回退单个文件到指定版本_git单个文件回到指定版本
- 2Unity程序基础框架__UI管理模块_unity ui管理器
- 3【TOP解刊】新晋中科院1区IEEE,跻身CCF-C类,国人友好,审稿极快!_ieee internet of things journal分区
- 4MapReduce(二): Job的运行状态_hadoop jobstate什么情况下是running
- 5gitblit服务器搭建
- 6Github新手使用教程_github下载后怎么使用
- 7区块链探秘:从基础到深度,全面解读区块链技术与应用_区块链的最新技术
- 8python爬虫实战之异步爬取数据_python 异步采集
- 9鸿蒙DevEco Studio 简单实现:使用页面路由实现登录跳转和返回功能。_鸿蒙deveco studio设计手机登录页面
- 10ArrayList集合的排序_第2关:用comparable接口实现arraylist集合的排序
大型语言模型(LLM)简介:基础知识、工作原理和示例_大语言模型原理
赞
踩
随着机器学习和自然语言处理的最新进展,大型语言模型获得了大量的关注和普及。大型语言模型是一种人工神经网络,它已经在大量文本数据上进行了训练,可以生成类似人类的文本。
“语言是一个自由创造的过程:它的规律和原则是固定的,但生成原则的使用方式是自由的和无限变化的。甚至词语的解释和使用也涉及自由创造的过程。“
在本文中,我们将探讨大型语言模型的基础知识、它们的工作原理以及一些流行的示例。
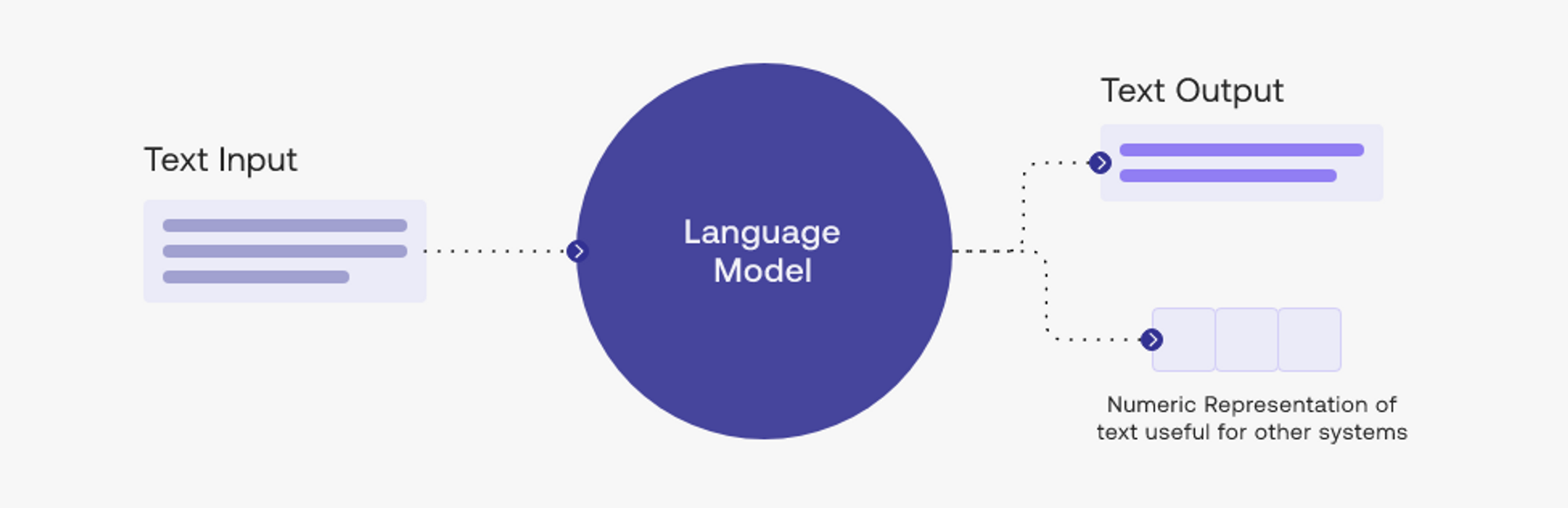
什么是大型语言模型?
语言模型是一种统计模型,用于预测单词序列的概率。它是一种人工神经网络,经过大量文本数据的训练,可以理解语言并预测序列中的下一个单词。大型语言模型是具有大量参数的神经网络,允许它们学习语言中的复杂模式。
大型语言模型,也称为预训练模型,是一种使用大量数据来学习语言特征的人工智能。这些模型用于生成基于语言的数据集,并可用于各种任务,例如语言理解和生成。
大型语言模型的关键特征之一是它们能够生成类似人类的文本。这些模型可以生成连贯、语法正确,有时甚至幽默的文本。他们还可以将文本从一种语言翻译成另一种语言,并根据给定的上下文回答问题。
大型语言模型如何工作?
大型语言模型使用一种称为无监督学习的技术来工作。在无监督学习中,模型是在没有任何特定标签或目标的情况下在大量数据上训练的。目标是学习数据的底层结构,并使用它来生成结构与原始数据相似的新数据。
对于大型语言模型,用于训练的数据通常是大型文本语料库。该模型学习文本数据中的模式,并使用它们来生成新文本。训练过程包括优化模型参数,以最小化语料库中生成的文本与实际文本之间的差异。
训练模型后,可以使用它来生成新文本。为此,模型被赋予一个单词的起始序列,并根据训练语料库中单词的概率生成序列中的下一个单词。重复此过程,直到生成所需的文本长度。
为了了解大型语言模型的工作原理,了解可用的不同类型的语言模型非常重要。最常见的语言模型类型是递归神经网络 (RNN)、卷积神经网络 (CNN) 和长短期记忆 (LSTM) 网络。这些模型通常用于在大型数据集(如宾夕法尼亚树库)上进行训练,并可用于生成基于语言的数据集。
训练语言模型后,它可用于在各种任务中生成文本,例如文本理解、文本生成、问答等。通过了解语言的一般特征,这些模型能够生成基于语言的数据集,这些数据集可用于为各种 NLP 应用程序提供支持。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/722228
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

