
热门标签
热门文章
- 1python实现onnx模型推理_onnx推理代码
- 2基于SpringBoot+Vue+uniapp微信小程序的微信阅读小程序的详细设计和实现_springboot vue 小程序
- 33.6k star, 免费开源跨平台的数据库管理工具 dbgate_数据库管理工具 开源
- 4从Github上下载文件的方法汇总_github如何下载文件
- 5【计算机毕业设计】基于ssm的宠物医院管理系统的设计与实现
- 6maven jar包瘦身
- 7构建文本数据集(tokenize、vocab)_数据集:英文小说time machine
- 8解码自然语言处理之 Transformers
- 9基于DataX迁移MySQL到OceanBase集群_datax mysql 同步到oceanbean
- 10ros打开笔记本电脑的摄像头_roslaunch usb_cam-test.launch
当前位置: article > 正文
论文笔记:Detecting Pretraining Data from Large Language Models
作者:知新_RL | 2024-04-08 06:45:13
赞
踩
论文笔记:Detecting Pretraining Data from Large Language Models
iclr 2024 reviewer评分 5688
1 intro
- 论文考虑的问题:给定一段文本和对一个黑盒语言模型的访问权限,在不知道其预训练数据的情况下,能否判断该模型是否在这段文本上进行了预训练
- 这个问题是成员推断攻击(Membership Inference Attacks,MIA)的一个实例
- 最近存在一些工作将微调数据检测作为一个MIA问题进行了研究
- 但是,将这些方法应用到检测大模型相关数据中,存在两个独特的技术挑战
- 与通常运行多个epoch的微调不同,预训练使用的数据集要大得多,但每个实例只暴露一次,
- ——>这显著减弱了成功MIA所需的潜在记忆
- 以前的方法通常依赖于一个或多个参考模型(影子模型)
- 这些模型以与目标模型相同的方式进行训练(从相同的基础预训练数据分布中采样的影子数据上进行训练)
- 这对于大型语言模型来说不可行,因为训练分布通常不可用,训练成本也太高
- 与通常运行多个epoch的微调不同,预训练使用的数据集要大得多,但每个实例只暴露一次,
- 但是,将这些方法应用到检测大模型相关数据中,存在两个独特的技术挑战
- ——>论文提出了一个基准 WikiMIA和一种预训练数据检测方法Min-K% Prob
2 WikiMIA
- 使用在特定日期(2023年1月1日)之后添加到维基百科的事件来构建基准
- 将这些事件视为非成员数据,因为可以保证这些数据不会出现在预训练数据中
- ——>最终收集了394个最近事件作为我们的非成员数据,并随机选择了394个在2016年前的维基百科页面中的事件作为我们的成员数据
2.1 数据的三个理想属性
- 准确:
- 在语言模型预训练之后发生的事件保证不会出现在预训练数据中。
- 事件的时间性质确保非成员数据确实未曾见过,并没有在预训练数据中提到。
- 通用
- 不限于任何特定的模型,可以应用于使用维基百科数据进行预训练的各种模型(OPT、LLaMA、GPT-Neo)
- 动态:
- 由于这里的数据构建流程是完全自动化的,论文将通过从维基百科收集更多最近的非成员数据(即更近期的事件)来持续更新论文的基准
3 Min-K% Prob
3.1 微调MIA 方法的不足
- 微调的MIA方法通常是:
- 用在相似数据分布上训练的参考模型(影子模型)来校准目标模型使用某一个样本的概率。
- 但是,由于预训练数据的黑盒性质和其高计算成本,这些方法在预训练数据检测中是不实际的。
- ——>论文提出了一个无参考的MIA方法Min-K% Prob
3.2 方法介绍
- 论文的方法基于一个简单的假设——一个未见过的样本往往包含几个具有低概率的异常词,而一个见过的样本不太可能包含这样低概率的词。
- Min-K% Prob计算离群词元的平均概率。
- Min-K% Prob可以在不了解预训练语料库或,不需要任何额外训练的情况下使用

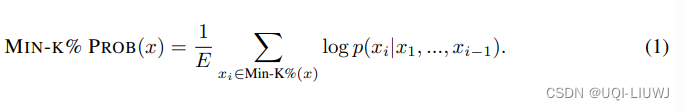
如果平均概率高,那么很有可能文本在预训练数据中
4 实验
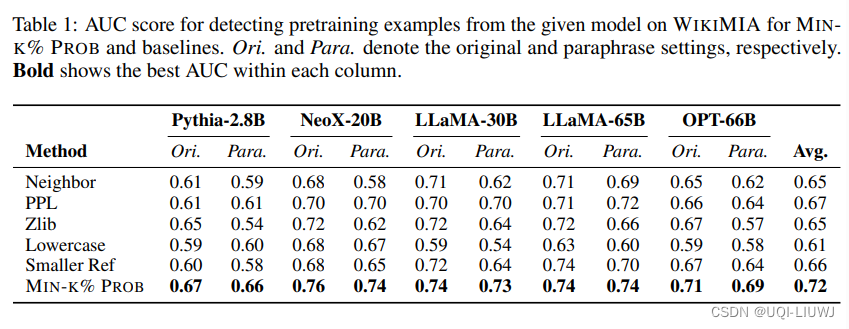
4.1 检测结果
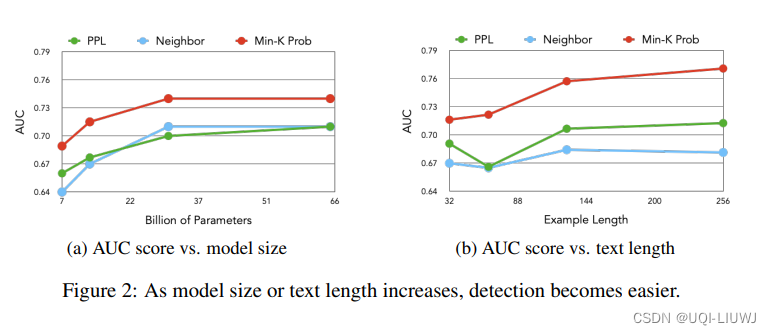
4.2 文本和模型大小的影响
4.3 GPT3 预训练数据中的Top20书籍

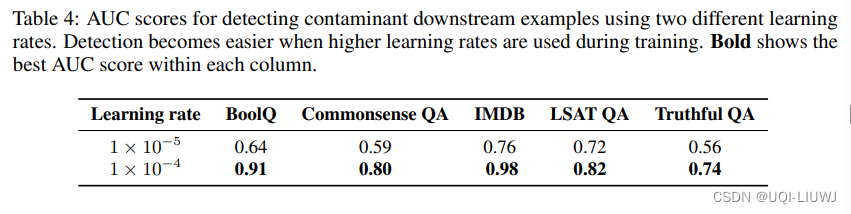
4.4 不同learning rate的影响
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/383640
推荐阅读
相关标签

