
- 1Windows Azure部署和虚拟IP_azure vrrp virtual ip address github
- 2【Vulnhub】之Nagini_vulnhub靶场下载
- 3Linux中关于时间修改的命令_linux 改时间命令
- 4如何使用Docker本地部署Wiki.js容器并结合内网穿透实现知识库共享_docker wiki部署
- 5鸿蒙HarmonyOS开发实战—AI功能开发(图像超分辨率)_鸿蒙中如何调用ai算法
- 6【PX4-AutoPilot教程-仿真环境架构】梳理PX4&Gazebo&MAVLink&MAVROS&ROS&ROS2之间的关系_px4-autopilot无人机目标搜索gazebo仿真
- 7在Spring Boot环境中使用Mockito进行单元测试_springboot mockito
- 8Docker如何对镜像进行命名_docker build 指定镜像名称
- 9spring boot + vue + element-ui全栈开发入门——基于Electron桌面应用开发(一)_springboot vue electron结合
- 10关于5G无人机的最强科普_诺巴曼无人机5g控制原理
自然语言处理之机器翻译_自然语言处理中的机器翻译最后怎么输出文字
赞
踩
介绍
- 机器翻译,简单来说,给你一句英语,机器给翻译成法语,是不是想到了有道翻译?
- 过程:
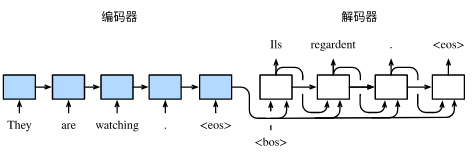
- 可以看出,句子都是不等长的,而且每个样本句子句末都有结束标记 ‘ < E o s > ’ ‘<Eos>’ ‘<Eos>’,另外解码器的一个输入是 ‘ < B o s > ’ ‘<Bos>’ ‘<Bos>’,然后输出第一个预测词。另外编码器需要设置一个最长步数max_len,所有句子的单词数不能超过max_len,不足的在结束标记 < B o s > <Bos> <Bos>之后添加多个 < p a d > <pad> <pad>标记。
- 另外编码器是用来提取特征的,叫做背景变量,它是对于输入样本每个时间步所对应的隐藏状态 h i h_{i} hi的某种操作。 即: c = q ( h 1 , … … , h T ) c=q(h_{1},……,h_{T}) c=q(h1,……,hT),q是操作函数,T是时间步数。那具体是什么函数操作q呢,我们引入注意力机制。
注意力机制
- 从图中可以看出这个背景变量c将参与到解码器每一步运算中,这也是必然的,因为每一步必然需要输入提取的编码器的特征来进行翻译嘛,就好比你翻译一句话当然要看前面的单词了。
- 但是这里面也存在问题,举个栗子,你翻译主语,当然应该主要参考样本的主语部分,其他部分也会了解一下,但是并没有那么大的权重。也就是说,对于解码器的每个时间步,应当对于前面编码器的不同时间步的隐藏状态有不同的侧重,所以在注意力机制中这个背景变量c是变化的,在不同的解码器时间步是不同的( c t ′ c_{t^{'}} ct′)。
- 所谓的注意力机制大概就是这个意思。
计算背景变量
- 那么如何计算背景变量c呢?解码器在时间步
t
′
t^{'}
t′的背景变量为所有编码器隐藏状态的加权平均:
c t ′ = ∑ t = 1 T α t ′ t h t c_{t^{'}}=\displaystyle\sum_{t=1}^{T} α_{t't}h_t ct′=t=1∑Tαt′tht,t是编码器的时间步,t’是解码器的时间步,T是编码器最长时间步,即max_len。 -
α
α
α是权重,
α
t
′
t
α_{t't}
αt′t是当解码器在t’时对应编码器时间步t时的隐藏状态权重。其中给定
t
′
t'
t′时,权重
α
t
′
t
α_{t't}
αt′t在
t
=
1
,
…
…
,
T
t=1,……,T
t=1,……,T的值是一个概率分布。为了得到概率分布,我们可以使用softmax运算:
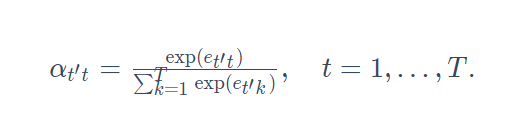
现在需要计算 e t ′ t e_{t't} et′t,它的计算同时取决于解码器的时间步t’和编码器的时间步t,我们通过函数a来计算它:
e t ′ t = a ( s t ′ − 1 , h t ) e_{t't}=a(s_{t'-1},h_t) et′t=a(st′−1,ht)
a函数的选择有很多,这里介绍两个:1.很简单,计算内积,即 a ( s , h ) = s T ∗ h a(s,h)=s^{T}*h a(s,h)=sT∗h,也就是说,计算 s t ′ − 1 和 h t s_{t'-1}和h_t st′−1和ht的内积,然后除以 s t ′ − 1 , h k 的 内 积 之 和 , k = 1 … … T s_{t'-1},h_k的内积之和,k=1……T st′−1,hk的内积之和,k=1……T得到概率,用这个概率作为权重。2.稍微复杂一些,最早提出注意力机制的论文则将输入连结后通过含单隐藏层的多层感知机变换,见下式:
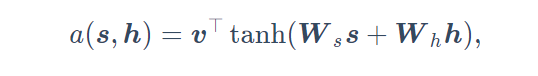
如果现在看不懂,待会看到代码就明白这个式子了。 - 好,总结一下就是下面这张图

先取出 s t ′ − 1 s_{t'-1} st′−1和 h k h_k hk,然后求a函数,再对其进行softmax得到概率,然后与 h k h_k hk加权求和得到背景变量c,完事。
矢量化计算背景变量
- 矢量化为矩阵的形式。以内积作为函数a为例,单个解码器时间步来说, s t ′ − 1 s_{t'-1} st′−1的尺寸是[batch,num_hiddens],num_hiddens是隐藏单元个数。然后编码器的隐藏状态尺寸是[max_len,batch,num_hiddens],交换第一第二维度调整为[batch,max_len,num_hiddens],设这个矩阵为 H H H,这时 s t ′ − 1 s_{t'-1} st′−1中的任意一行(一共batch行)与编码器中的一个[max_len,num_hiddens]的转置对应(一共有batch个这个矩阵),然后执行矩阵乘法: [ 1 , n u m _ h i d d e n s ] ∗ [ m a x _ l e n , n u m _ h i d d e n s ] T = [ 1 ∗ m a x _ l e n ] [1,num\_hiddens]*[max\_len,num\_hiddens]^T=[1*max\_len] [1,num_hiddens]∗[max_len,num_hiddens]T=[1∗max_len],因为一共batch行,所以得到[batch,max_len],对行执行softmax得到[batch,max_len]。
- 然后与编码器的隐层状态 H H H进行加权求和,具体操作是对于[batch,max_len]中任何一行[1,max_len](一共batch行),对应 H H H中的任何一个[max_len,num_hiddens](一共batch个这种矩阵),做矩阵乘法得到[1,num_hiddens],由于一共batch个,所以得到[batch,num_hiddens]这就是batch个样本得到的背景向量c。
- 上面是大体步骤,具体的矢量化过程在代码里,看的懂上面的再看代码就很轻松。
GRU中的改动
- 首先我们的解码器使用GRU门控。
- 再观察这张图:
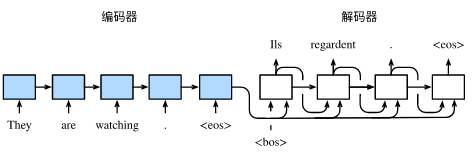
我们解码器每一步有三个输入,分别是上一步的隐藏状态 s t ′ − 1 、 c t ′ 、 y t ′ − 1 s_{t'-1}、c_{t'}、y_{t'-1} st′−1、ct′、yt′−1,所以GRU中改为:

但其实代码上没有任何改动,只要把输入尺寸开大一点等于 c t ′ 、 y t ′ − 1 c_{t'}、y_{t'-1} ct′、yt′−1尺寸之和就好了。
代码实战部分
数据预处理
- 没啥好说的,定义句子最大长度为7,不够的补
<
p
a
d
>
<pad>
<pad>,多说一句
<
p
a
d
>
,
<
B
o
s
>
,
<
E
o
s
>
<pad>,<Bos>,<Eos>
<pad>,<Bos>,<Eos>分别被编码为0,1,2了。我们给出输入句子和输出句子的样例。
(tensor([ 5, 4, 45, 3, 2, 0, 0]), tensor([ 8, 4, 27, 3, 2, 0, 0]))
可以看出,以2结尾,以0补充空余。
编码器
- 这部分比较简单,用来提取输入句子的特征,代码如下:
class Encoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
drop_prob=0, **kwargs):
super(Encoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=drop_prob)
def forward(self, inputs, state):
# 输入形状是(批量大小, 时间步数)。将输出互换样本维和时间步维
embedding = self.embedding(inputs.long()).permute(1, 0, 2) # (seq_len, batch, input_size)
return self.rnn(embedding, state)
def begin_state(self):
return None # 隐藏态初始化为None时PyTorch会自动初始化为0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
首先输入形状[batch,max_len]很容易理解,然后转化为词向量并交换维度得到[max_len,batch,embedd_size],经过GRU之后得到的outputs形状是[max_len,batch,num_hiddens],state形状是[num_layers,batch,num_hiddens]是最后一步得到的隐藏状态。
- 如下面我们来创建一个批量大小为4、时间步数为7的小批量序列输入。设门控循环单元的隐藏层个数为2,隐藏单元个数为16。编码器对该输入执行前向计算后返回的输出形状为(时间步数, 批量大小, 隐藏单元个数)。门控循环单元在最终时间步的多层隐藏状态的形状为(隐藏层个数, 批量大小, 隐藏单元个数)。对于门控循环单元来说,state就是一个元素,即隐藏状态;如果使用长短期记忆,state是一个元组,包含两个元素即隐藏状态和记忆细胞。
encoder = Encoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
output, state = encoder(torch.zeros((4, 7)), encoder.begin_state())
output.shape, state.shape # GRU的state是h, 而LSTM的是一个元组(h, c)
- 1
- 2
- 3
- 4
输出
(torch.Size([7, 4, 16]), torch.Size([2, 4, 16]))
- 1
注意力机制
- 首先我们要实现注意力机制中定义的函数a
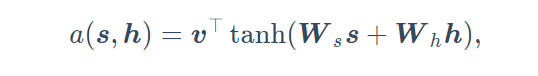
- 代码如下:
def attention_model(input_size, attention_size):
model = nn.Sequential(nn.Linear(input_size,
attention_size, bias=False),
nn.Tanh(),
nn.Linear(attention_size, 1, bias=False))
return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们当然也可以采用内积,这里实现的是第二种a函数定义方式。
- 然后我们要实现矢量化的整个注意力机制过程:
# 根据注意力机制返回背景变量[批量大小, 隐藏单元个数]
def attention_forward(model, enc_states, dec_state):
"""
enc_states: (时间步数, 批量大小, 隐藏单元个数) 是编码器在所有时间步的隐藏状态
dec_state: (批量大小, 隐藏单元个数) 是解码器在上一步的隐藏状态
"""
# 将解码器隐藏状态广播到和编码器隐藏状态形状相同后进行连结
dec_states = dec_state.unsqueeze(dim=0).expand_as(enc_states)# (时间步数, 批量大小, 隐藏单元个数)
enc_and_dec_states = torch.cat((enc_states, dec_states), dim=2)# (时间步数, 批量大小, 2*隐藏单元个数)
e = model(enc_and_dec_states) # 形状为(时间步数, 批量大小, 1)
alpha = F.softmax(e, dim=0) # 在时间步维度做softmax运算 形状为(时间步数, 批量大小, 1)
print((alpha * enc_states).shape) # torch.Size([7, 2, 64])
return (alpha * enc_states).sum(dim=0) # 返回背景变量 [batch,num_hiddens]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这里的dec_state就是咱们上面讲的
s
t
′
−
1
s_{t'-1}
st′−1,形状是[batch,num_hiddens],enc_states就是咱们上面讲的编码器的隐藏状态
H
H
H,形状是[max_len,batch,num_hiddens],dec_state.unsqueeze(dim=0)变为[1,batch,num_hiddens],expand_as(enc_states)变为[max_len,batch,num_hiddens],是通过复制的形式变成这个尺寸。然后在第三维度上联结,这样的话相当于把输入s和H一起放到函数a里。这里的a函数可不是计算内积了,而是第二种方法。执行完a函数得到e之后再对其的时间步维度执行softmax,然后将softmax之后的概率与隐藏层状态enc_states相乘得到每个时间步的加权隐藏层状态,再对时间步维度求和就可以得到最终的背景变量c,形状为[batch,num_hiddens]。
下面示范一下:
在下面的例子中,编码器的时间步数为10,批量大小为4,编码器和解码器的隐藏单元个数均为8。注意力机制返回一个小批量的背景向量,每个背景向量的长度等于编码器的隐藏单元个数。因此输出的形状为(4, 8)。
seq_len, batch_size, num_hiddens = 10, 4, 8
model = attention_model(2*num_hiddens, 10)
enc_states = torch.zeros((seq_len, batch_size, num_hiddens))
dec_state = torch.zeros((batch_size, num_hiddens))
attention_forward(model, enc_states, dec_state).shape # torch.Size([4, 8])
- 1
- 2
- 3
- 4
- 5
- 6
解码器
- 我们直接将编码器在最终时间步的隐藏状态作为解码器的初始隐藏状态。这要求编码器和解码器的循环神经网络使用相同的隐藏层个数和隐藏单元个数。
- 下面是具体代码
# 解码器首先计算背景向量,然后和编码后的输入联结得到(批量大小, num_hiddens+embed_size),然后放入GRU+Linear得到[batch,vocab_size] # 即从输入[batch,]得到输出[batch,vocab_size] class Decoder(nn.Module): def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, attention_size, drop_prob=0): super(Decoder, self).__init__() self.embedding = nn.Embedding(vocab_size, embed_size) self.attention = attention_model(2*num_hiddens, attention_size) # GRU的输入包含attention输出的c和实际输入, 所以尺寸是 num_hiddens+embed_size self.rnn = nn.GRU(num_hiddens + embed_size, num_hiddens, num_layers, dropout=drop_prob) self.out = nn.Linear(num_hiddens, vocab_size) def forward(self, cur_input, state, enc_states): """ cur_input shape: (batch, ) state shape: (num_layers, batch, num_hiddens) """ # 使用注意力机制计算背景向量 [batch,num_hiddens] c = attention_forward(self.attention, enc_states, state[-1]) # 将嵌入后的输入和背景向量在特征维连结, (批量大小, num_hiddens+embed_size) input_and_c = torch.cat((self.embedding(cur_input), c), dim=1) # 为输入和背景向量的连结增加时间步维,时间步个数为1 rnn([(1,批量大小, num_hiddens+embed_size)],(num_layers, batch, num_hiddens)) # =(1,批量大小,num_hiddens),(num_layers, batch, num_hiddens) output, state = self.rnn(input_and_c.unsqueeze(0), state) # 移除时间步维,输出形状为(批量大小, 输出词典大小) output = self.out(output).squeeze(dim=0) return output, state def begin_state(self, enc_state): # 直接将编码器最终时间步的隐藏状态作为解码器的初始隐藏状态 return enc_state

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
为啥输入cur_input是(batch, )形状呢,因为每一次时间步调用一次解码器,所以输入的是某个时间步的batch个字,首先要得到背景向量,enc_states, state[-1]分别是编码器隐藏状态和解码器上一步的隐藏状态。然后还记得我们说过GRU需要改造一下,就是将c和input联结一下,然后作为输入输入到GRU层,input_and_c.unsqueeze(0)是增加一个步数维。
训练
- 这一块就不用说太多了,直接上代码
def batch_loss(encoder, decoder, X, Y, loss): batch_size = X.shape[0] enc_state = encoder.begin_state() # 获取特征enc_outputs,[步数,batch,num_hiddens],最后一步的隐藏层状态enc_state[num_layers,batch,num_hiddens] enc_outputs, enc_state = encoder(X, enc_state) # 初始化解码器的隐藏状态 dec_state = decoder.begin_state(enc_state) # 解码器在最初时间步的输入是BOS,输入形状为[batch,] dec_input = torch.tensor([out_vocab.stoi[BOS]] * batch_size) # 我们将使用掩码变量mask来忽略掉标签为填充项PAD的损失 mask, num_not_pad_tokens = torch.ones(batch_size,), 0 l = torch.tensor([0.0]) for y in Y.permute(1,0): # Y shape: (batch, seq_len) y:[1,batch],一个字一个字来 # 得到第一步batch个字的输出,为[batch,vocab_size],state:(num_layers, batch, num_hiddens) dec_output, dec_state = decoder(dec_input, dec_state, enc_outputs) l = l + (mask * loss(dec_output, y)).sum() dec_input = y # 使用强制教学 num_not_pad_tokens += mask.sum().item() # EOS后面全是PAD. 下面一行保证一旦遇到EOS接下来的循环中mask就一直是0 mask = mask * (y != out_vocab.stoi[EOS]).float() return l / num_not_pad_tokens def train(encoder, decoder, dataset, lr, batch_size, num_epochs): enc_optimizer = torch.optim.Adam(encoder.parameters(), lr=lr) dec_optimizer = torch.optim.Adam(decoder.parameters(), lr=lr) loss = nn.CrossEntropyLoss(reduction='none') data_iter = Data.DataLoader(dataset, batch_size, shuffle=True) for epoch in range(num_epochs): l_sum = 0.0 for X, Y in data_iter:# (batch, seq_len) enc_optimizer.zero_grad() dec_optimizer.zero_grad() l = batch_loss(encoder, decoder, X, Y, loss) l.backward() enc_optimizer.step() dec_optimizer.step() l_sum += l.item() if (epoch + 1) % 10 == 0: print("epoch %d, loss %.3f" % (epoch + 1, l_sum / len(data_iter))) embed_size, num_hiddens, num_layers = 64, 64, 2 attention_size, drop_prob, lr, batch_size, num_epochs = 10, 0.5, 0.01, 2, 50 encoder = Encoder(len(in_vocab), embed_size, num_hiddens, num_layers, drop_prob) decoder = Decoder(len(out_vocab), embed_size, num_hiddens, num_layers, attention_size, drop_prob) train(encoder, decoder, dataset, lr, batch_size, num_epochs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
总结
- 总结一下其实就是:
数据预处理->编码器提取输入特征->解码器怎么使用编码器的特征呢?答案是通过对编码器各个时间步的隐藏状态和解码器上一步的隐藏状态计算进行加权求和得到背景向量c,这个向量就代表了计算解码器当前步数的输出所能用到的前面的所有的编码器经验信息,然后再与上一步解码器的隐藏状态以及上一步解码器的输出一起作为本步解码器的输入,经过GRU门控网络得到本步隐藏状态,再经过out全连接层预测得到输出,这两个再参与下一步的解码器运算。 - 总结来看,机器翻译还是循环网络,区别于情感分析,情感分析其实是对整个句子提取特征后的二分类问题,一个样本只需要进行一次分类,属于一对一问题,而机器翻译一个样本对应多个分类,属于一对多问题。由于情感分析问题的特殊性,所以可以使用卷积神经网络来进行操作。

