
热门标签
热门文章
- 1MongoDB 实战(一)基于PyMongo的电影影评分析 | 对数据结果进行可视化展示以及分析 | 评论词云 | 分时间段分析_xshell用mongodb取出数据并把数据可视化项目
- 2Hadoop大数据处理与分析教程_基于hadoop的大数据分析和处理
- 3Java泛型详解(史上最全泛型知识详解)_java 泛型
- 4自然语言处理---情感分析(1)【baseline 从RNN开始】_自然语言情感处理
- 5linux虚拟机中vi / vim编辑文件,保存并退出_虚拟机如何保存修改文件
- 6Elasticsearch探秘:原理剖析、高级运用与实战经验【文末送书】_《一本书讲透 elasticsearch》pdf下载一本书讲透elasticsearch:原理、进阶
- 7开源软件及国内发展现状_挖地兔 开源软件 现状
- 8Android开发中利用imeOptions属性将键盘回车键改成搜索等功能键【提高用户输入体验】_android:imeoptions="actionnext
- 9CSS - 浮动、定位
- 10基于STM32的出租车计价器系统
当前位置: article > 正文
Python数据分析与挖掘实战学习笔记(一)_信息分析与实战挖掘学习
作者:知新_RL | 2024-04-01 13:16:03
赞
踩
信息分析与实战挖掘学习
1. 数据清洗
(1)缺失值处理
三种方法:删除记录、数据插补、不处理
常见插补方法:均值/中位数/众数插补、使用固定值/期望值、回归方法(根据已有数据和其他与其有关变量等建立拟合模型来预测)、插值法(利用已知点建立合适的插值函数,如拉格朗日函数)
我们以餐厅销量数据为例,使用拉格朗日插值法进行缺失值处理 ,使用缺失值前后各5个未缺失数据参与建模,得出结果如下。
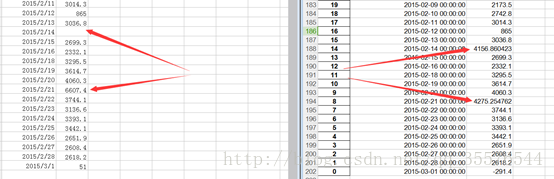
应用拉格朗日插值法代码如下:
- #拉格朗日插值代码
- import pandas as pd #导入数据分析库Pandas
- from scipy.interpolate import lagrange #导入拉格朗日插值函数
- inputfile = '../data/catering_sale.xls' #销量数据路径
- outputfile = '../data/sales.xls' #输出数据路径
- data = pd.read_excel(inputfile) #读入数据
- data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值
- #自定义列向量插值函数
- #s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
- def ployinterp_column(s, n, k=5):
- y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
- y = y[y.notnull()] #剔除空值
- return lagrange(y.index, list(y))(n) #插值并返回插值结果
-
-
- #逐个元素判断是否需要插值
- for i in data.columns:
- for j in range(len(data)):
- if (data[i].isnull())[j]: #如果为空即插值。
- data[i][j] = ployinterp_column(data[i], j)
-
- data.to_excel(outputfile) #输出结果,写入文件

(2)异常值处理
在处理时,有些异常值可能蕴含有用信息,需视情况而定。四种方法:删除含有异常值的记录、视为缺失值、平均值修正、不处理。
在数据量较多的时候我们不可能人工分辨,这里受用describe函数查看数据基
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/349008?site
推荐阅读

相关标签

