
热门标签
热门文章
- 1idea+git 从远程Git仓库上获取项目源码 和 拉取新增或修改的文件 等 各种常规操作 较全_idea从git拉取项目
- 2Windows下安装和配置Redis_redis安装部署windows
- 3Git:分支发散问题处理,合并、变基和快进_git pull 合并 变基 快进
- 4windows7怎么安装python库_如何在Windows 7安装Python2.7
- 5一套详细的数据中心机房建设方案_基础网络设施和机房建设
- 6ubuntu下的翻译软件--比有道强大多了_ubuntu英文翻译中文
- 7微服务架构:注册中心 Eureka、ZooKeeper、Consul、Nacos的选型对比详解_微服务注册中心比较
- 8java集合知识_java集合知识点总结
- 9Ubuntu如何更换 PyTorch 版本_更换pytorch版本
- 10Flutter学习资源_flutter容许与其他音乐同时播放
当前位置: article > 正文
李沐 动手学 深度学习:实战Kaggle比赛:预测房价_李沐房价预测
作者:盐析白兔 | 2024-08-17 17:07:38
赞
踩
李沐房价预测
- #实现几个函数来方便下载数据
- #建立字典DATA_HUB,可以将数据集名称的字符串映射到数据集相关的二元组上:包含数据集的url和验证文件完整性的sha-1密钥。
- #所有类似的数据集都托管在地址为DATA_URL的站点上。
- import hashlib
- import os
- import tarfile
- import zipfile
- import requests
-
- import numpy as np
- import pandas as pd
- import torch
- from torch import nn
- from d2l import torch as d2l
-
- #@save
- DATA_HUB = dict()
- DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
-
- #download函数用来下载数据集,将数据集缓存在本地目录(../data)中,并返回下载文件的名称。
- #如果缓存目录已存在此数据集文件,且其sha-1与存储在DATA_HUB中的相匹配,将使用缓存的文件,以避免重复的下载。
- def download(name, cache_dir=os.path.join('..', 'data')): #@save
- """下载一个DATA_HUB中的文件,返回本地文件名"""
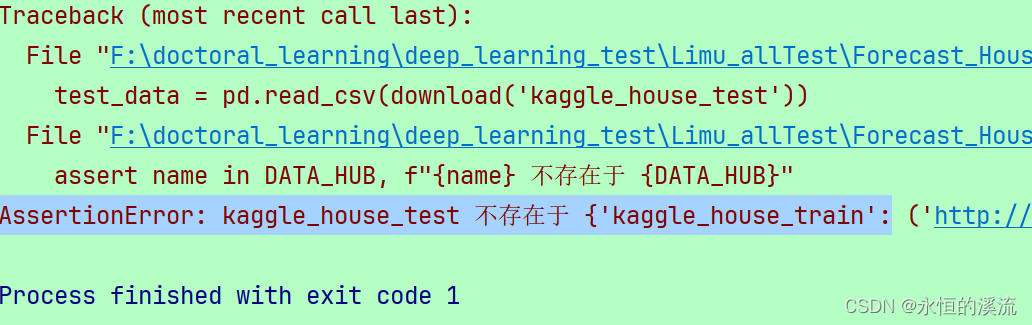
- assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"
- url, sha1_hash = DATA_HUB[name]
- os.makedirs(cache_dir, exist_ok=True)
- fname = os.path.join(cache_dir, url.split('/')[-1])
- if os.path.exists(fname):
- sha1 = hashlib.sha1()
- with open(fname, 'rb') as f:
- while True:
- data = f.read(1048576)
- if not data:
- break
- sha1.update(data)
- if sha1.hexdigest() == sha1_hash:
- return fname # 命中缓存
- print(f'正在从{url}下载{fname}...')
- r = requests.get(url, stream=True, verify=True)
- with open(fname, 'wb') as f:
- f.write(r.content)
- return fname
-
-
- #实现两个实用函数:一个将下载并解压缩一个zip或tar文件,另一个是将本书中使用的所有数据集从DATA_HUB下载到缓存目录中。
- def download_extract(name, folder=None): #@save
- """下载并解压zip/tar文件"""
- fname = download(name)
- base_dir = os.path.dirname(fname)
- data_dir, ext = os.path.splitext(fname)
- if ext == '.zip':
- fp = zipfile.ZipFile(fname, 'r')
- elif ext in ('.tar', '.gz'):
- fp = tarfile.open(fname, 'r')
- else:
- assert False, '只有zip/tar文件可以被解压缩'
- fp.extractall(base_dir)
- return os.path.join(base_dir, folder) if folder else data_dir
-
- def download_all(): #@save
- """下载DATA_HUB中的所有文件"""
- for name in DATA_HUB:
- download(name)
-
- #使用pandas分别加载包含训练数据和测试数据的两个CSV文件。
- train_data = pd.read_csv(download('kaggle_house_train'))
- test_data = pd.read_csv(download('kaggle_house_test'))

出错:AssertionError: kaggle_house_test 不存在于 {'kaggle_house_train':
猜测可能没有连接上网站,所以自己动手下载了。
1.如何注册Kaggle网站?按照下面这个网友的办法 注册成功。
kaggle网站注册登录流程详细介绍(小白必看)_kaggle注册-CSDN博客
2.在这里下载:
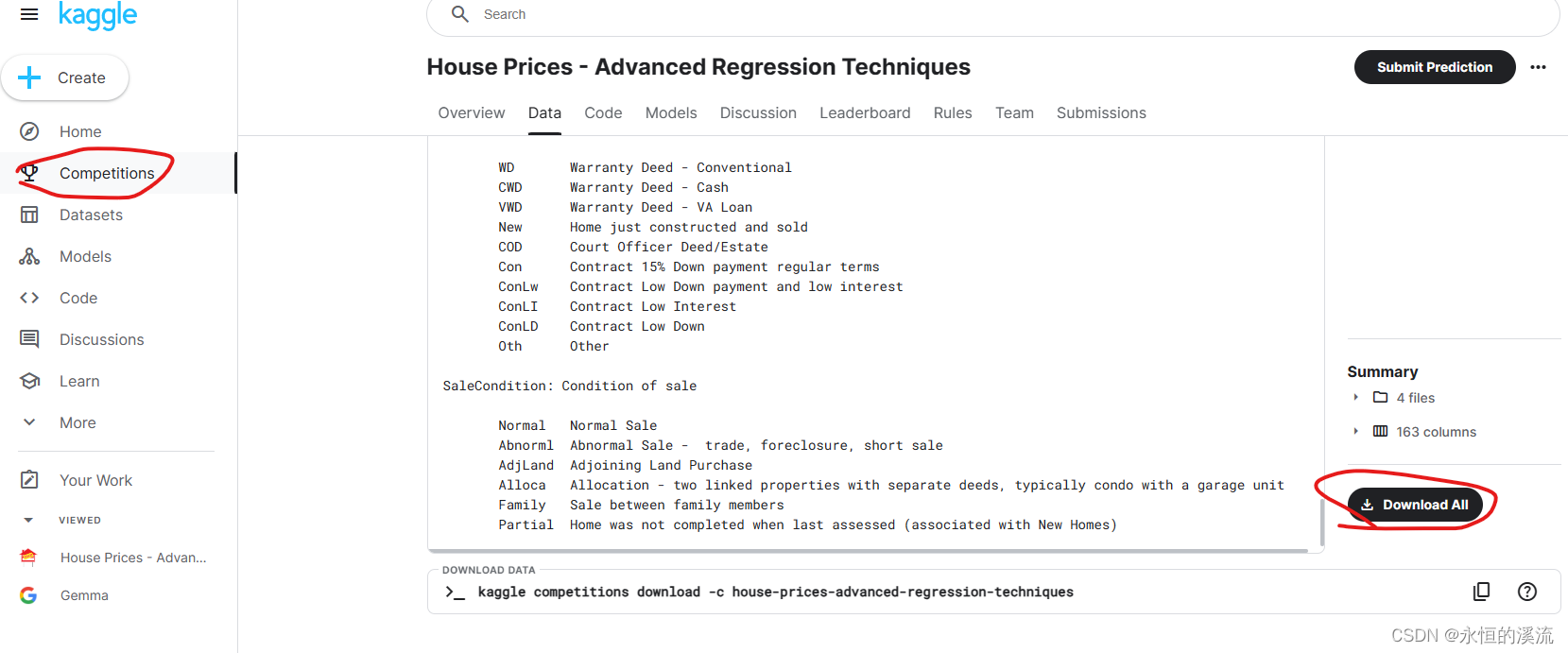
3.运行代码后出错:
- #matplotlib_inline
- import numpy as np
- import pandas as pd
- import torch
- from torch import nn
- from d2l import torch as d2l
-
- #1.访问和读取数据集
- #使用pandas分别加载包含训练数据和测试数据的两个CSV文件。
- train_data = pd.read_csv(r'F:\doctoral_learning\deep_learning_test\Limu_allTest\data\house-prices-advanced-regression-techniques\train.csv')
- test_data = pd.read_csv(r'F:\doctoral_learning\deep_learning_test\Limu_allTest\data\house-prices-advanced-regression-techniques\test.csv')
-
- #训练数据集包括1460个样本,每个样本80个特征和1个标签,而测试数据集包含1459个样本,每个样本80个特征。
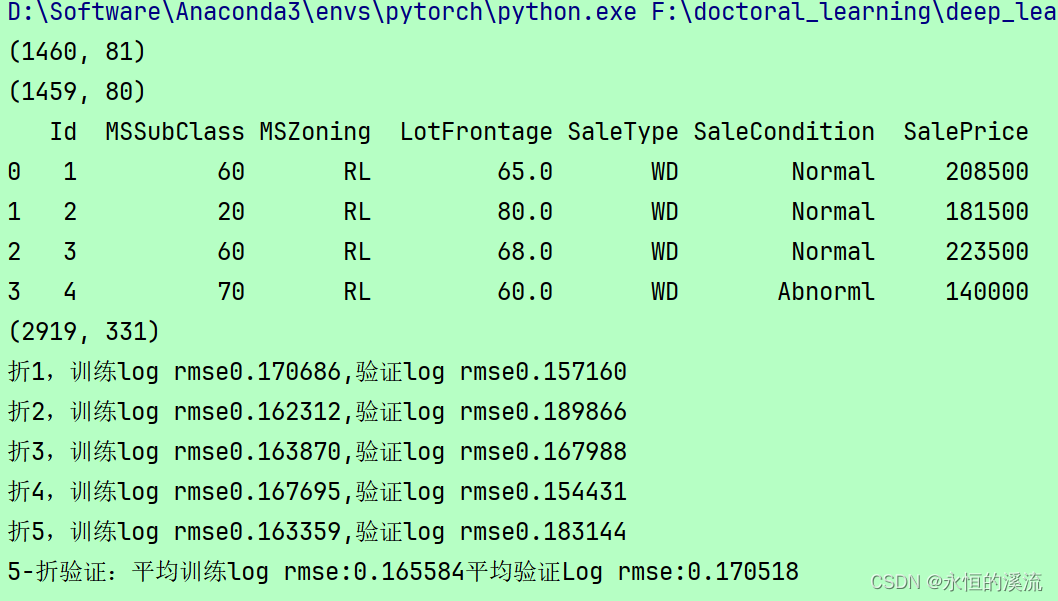
- print(train_data.shape)
- print(test_data.shape)
-
- #看看前四个和最后两个特征,以及相应标签(房价)。
- print(train_data.iloc[0:4,[0,1,2,3,-3,-2,-1]])
-
- #每个样本中,第一个特征是ID,这有助于模型识别每个训练样本。
- # 虽然这很方便,但它不携带任何用于预测的信息。故在将数据提供给模型之前,我们将其从数据集中删除。
- all_features = pd.concat((train_data.iloc[:,1:-1],test_data.iloc[:,1:]))#训练集和测试集均去掉第一列后合并
-
- #2.数据预处理
- #将所有缺失的值替换为相应特征的平均值。为了将所有特征放在一个共同的尺度上,通过将特征重新缩放到零均值和单位方差来标准化数据
- #标准化数据有两个原因:方便优化;因为不知道哪些特征是相关的,所以我们不想让惩罚分配给一个特征的系数比分配给其他任何特征的系数更大。
- #若无法获得测试数据,可根据训练数据计算均值和标准差
- numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index#不是文本特征的话就是数值特征
- all_features[numeric_features] = all_features[numeric_features].apply( #所有数值特征做归一化
- lambda x:(x - x.mean()) / (x.std()))
- #在标准化数据之后,所有均值消失,可以将缺失值设置为0
- all_features[numeric_features] = all_features[numeric_features].fillna(0)
- #接下来处理离散值。包括诸如“MSZoning”之类的特征,用独热编码替换它们,方法与前面将多类别标签转换为向量的方式相同
- #如,“MSZoning”包含值“RL”和“Rm”,将创建两个新的指示器特征“MSZoning_RL”和“MSZoning_RM”,其值为0或1。
- #根据独热编码,如果“MSZoning”的原始值为“RL”,则:“MSZoning_RL”为1,“MSZoning_RM”为0。
- #“Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
- all_features = pd.get_dummies(all_features,dummy_na=True)
- print(all_features.shape)
- #此转换会将特征的总数量从79个增加到331个。通过values属性,从pandas格式中提取NumPy格式,并将其转换为张量表示用于训练。
- n_train = train_data.shape[0]
- train_features = torch.tensor(all_features[:n_train].values,dtype=torch.float32)
- test_features = torch.tensor(all_features[n_train:].values,dtype=torch.float32)
- train_labels = torch.tensor(
- train_data.SalePrice.values.reshape(-1,1),dtype=torch.float32)
-
-
- #3.训练
- #训练一个带有损失平方的线性模型。线性模型很难在竞赛中获胜,但线性模型提供了一种健全性检查,以查看数据中是否存在有意义的信息。
- #如果不能做得比随机猜测更好,那么很可能存在数据处理错误。如果一切顺利,线性模型将作为基线(baseline)模型,让直观地知道最好的模型有超出简单的模型多少。
- loss = nn.MSELoss()
- in_features = train_features.shape[1]
-
- def get_net():
- net = nn.Sequential(nn.Linear(in_features,1)) #单层线性回归
- return net
-
- #房价就像股票价格一样,关心的是相对数量,而不是绝对数量。因此,更关心相对误差,而不是绝对误差
- #解决这个问题的一种方法是用价格预测的对数来衡量差异:官方用来评价提交质量的误差指标。
- def log_rmse(net,features,labels):#为了在取对数时进一步稳定该值,讲小于1的值设置为1
- clipped_preds = torch.clamp(net(features),1,float('inf'))
- rmse = torch.sqrt(loss(torch.log(clipped_preds),
- torch.log(labels)))
- return rmse.item()
-
- #训练函数将借助Adam优化器 (将在后面章节更详细地描述)。Adam优化器的主要吸引力在于它对初始学习率不那么敏感。
- def train(net,train_features,train_labels,test_features,test_labels,
- num_epochs,learning_rate,weight_decay,batch_size):
- train_Is,test_Is = [],[]
- train_iter = d2l.load_array((train_features,train_labels),batch_size)
- #使用Adam优化算法
- optimizer = torch.optim.Adam( net.parameters(),
- lr = learning_rate,
- weight_decay = weight_decay)
- for epoch in range(num_epochs):
- for X,y in train_iter:
- optimizer.zero_grad()
- I = loss(net(X),y)
- I.backward()
- optimizer.step()
- train_Is.append(log_rmse(net,train_features,train_labels))
- if test_labels is not None:
- test_Is.append(log_rmse(net,test_features,test_labels))
- return train_Is,test_Is
-
- #4.K折交叉验证:
- # 有助于模型选择和超参数调整.首先需要定义一个函数,在K折交叉验证过程中返回第i折的数据
- #选择第i个切片作为验证数据,其余部分作为训练数据。这并不是处理数据的最有效方法,如果数据集大得多,会有其他解决办法。
- def get_k_fold_data(k,i,X,y):
- assert k > 1
- fold_size = X.shape[0] // k
- X_train,y_train = None,None
- for j in range(k):
- idx = slice(j * fold_size,(j+1) * fold_size)
- X_part,y_part = X[idx,:],y[idx]
- if j == i: #当前第几折
- X_valid,y_valid = X_part,y_part
- elif X_train is None:
- X_train,y_train = X_part,y_part
- else:
- X_train = torch.cat([X_train,X_part],0)
- y_train = torch.cat([y_train,y_part],0)
- return X_train,y_train,X_valid,y_valid
-
- #在K折交叉验证中训练K次后,返回训练和验证误差的平均值。
- def k_fold(k,X_train,y_train,num_epochs,learning_rate,weight_decay,batch_size):
- train_l_sum,valid_l_sum = 0,0
- for i in range(k):
- data = get_k_fold_data(k,i,X_train,y_train)
- net = get_net()
- train_Is,valid_Is = train(net,*data,num_epochs,learning_rate,
- weight_decay,batch_size)
- train_l_sum += train_Is[-1]
- valid_l_sum += valid_Is[-1]
- if i == 0:
- d2l.plot(list(range(1,num_epochs + 1)),[train_Is,valid_Is],
- xlabel='epoch',ylabel='rmse',xlim=[1,num_epochs],
- legend=['train','valid'],yscale='log')
- print(f'折{i+1},训练log rmse{float(train_Is[-1]):f},'
- f'验证log rmse{float(valid_Is[-1]):f}')
- return train_l_sum / k,valid_l_sum / k
-
- #5.模型选择:
- #选择了一组未调优的超参数。找到一组调优的超参数可能需要时间,这取决于优化了多少变量。
- #有了足够大的数据集和合理设置的超参数,K折交叉验证往往对多次测试具有相当的稳定性。如果超参数不合理,验证效果不再代表真正的误差。
- k,num_epochs,lr,weight_decay,batch_size = 5,100,5,0,64
- train_I,valid_I = k_fold(k,train_features,train_labels,num_epochs,lr,
- weight_decay,batch_size)
- print(f'{k}-折验证:平均训练log rmse:{float(train_I):f}'
- f'平均验证Log rmse:{float(valid_I):f}')

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/993708
推荐阅读
相关标签

