
- 1linux系统之永久关闭防火墙_linux 永久关闭防火墙
- 2测试开发是什么?为什么现在那么多公司都要招聘测试开发?
- 3ChatGPT分销系统_chatgpt分销版搭
- 4Haproxy搭建Web群集实操(调度算法、群集配置、日志管理、参数优化)_haproxy 管理界面web gui
- 5等保篇-LINXU操作系统等保测评指南_等保 剩余信息保护 linux
- 6linux永久关闭防火墙_永久关闭防火墙linux
- 7Python_Scrapy安装问题及解决_使用pip命令安装后在pycharm仍不能导入_安装了scrapy,但是依然显示no module named 'scrapy
- 8docker配置出错Job for docker.service failed because the control process exited with error code解决方法
- 9Linux · Zookeeper的安装、使用及常用命令,虚拟机ping外网,linux防火墙设置
- 10hystrix-go 源码分析
Window 窗口函数 (Spark Sql)_sparksql window
赞
踩
目录
题目解析:根据这个题目要求我们可以将id进行排序然后用Window窗口函数进行排名取第一名即可
前言
在 Spark SQL 中,Window 函数是一种用于在查询结果集中执行聚合、排序和分析操作的强大工具。它允许你在查询中创建一个窗口,然后对窗口内的数据进行聚合计算。
首先先上语法代码(基础语法)
- import org.apache.spark.sql.expressions.Window
- import org.apache.spark.sql.functions._
-
- //1. 创建一个 WindowSpec 对象,指定窗口的分区和排序方式
- val windowSpec = Window.partitionBy("id").orderBy(desc("sales"))
-
- //2. 使用 Window 函数计算每个类别的销售额排名
- val result = df.withColumn("rank", rank().over(windowSpec))
-
- result.show()
语句解析:
1.Window.partitionBy("id").orderBy(desc("sales")
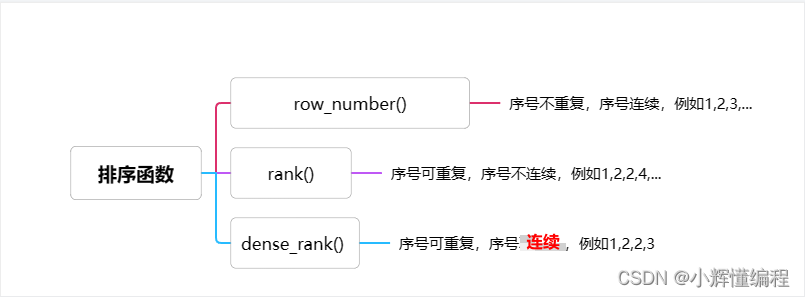
partitionBy() 分组函数(可以理解为groupBy函数)
orderBy() 排序函数函数 (desc|asc)
对字段“id”进行分组,然后分完组后对“sales”字段进行降序排序
2.val result = df.withColumn("rank", rank().over(windowSpec))
rank() 排序函数
over() 调用窗口函数
添加rank列,将排序后的值添加进去
排序函数
最后,使用 `withColumn` 方法将计算出的排名添加为新的列,并通过 `show()` 方法展示结果。
案例实战
先初始化一个sparkSql 对象 和 初始化数据
- object Main2 {
- def main(args: Array[String]): Unit = {
- var con = new SparkConf().setMaster("local[*]").setAppName("main")
-
-
- val sc = new SparkSession.Builder()
-
- .config(con)
- .enableHiveSupport()
- .getOrCreate()
-
- // 模拟数据
- // 创建数据框
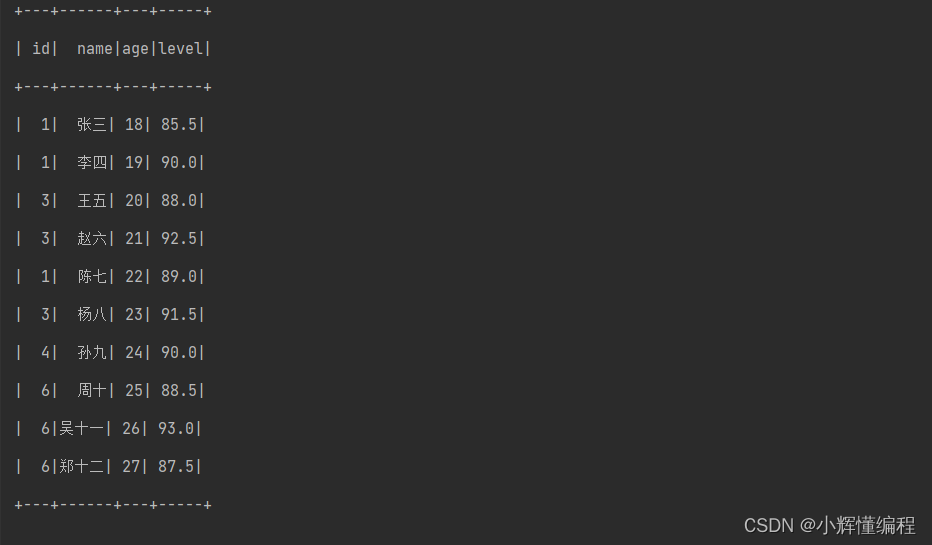
- val data = List(
- (1, "张三", 18, 85.5),
- (1, "李四", 19, 90.0),
- (3, "王五", 20, 88.0),
- (3, "赵六", 21, 92.5),
- (1, "陈七", 22, 89.0),
- (3, "杨八", 23, 91.5),
- (4, "孙九", 24, 90.0),
- (6, "周十", 25, 88.5),
- (6, "吴十一", 26, 93.0),
- (6, "郑十二", 27, 87.5)
- )
- // 将数据转换为DataFrame
- val df = sc.createDataFrame(data)
- val frame = df.toDF("id", "name", "age", "level") //添加列名
- frame.show()
-
-
- }
- }

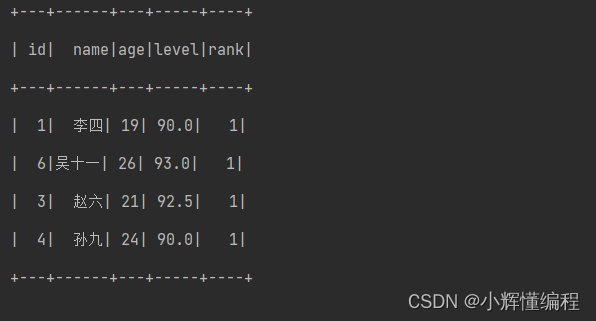
1.题目要求:求出id中成绩最高的数据
题目解析:根据这个题目要求我们可以将id进行排序然后用Window窗口函数进行排名取第一名即可
- // 1.定义窗口函数 (根据id列进行分组,然后level进行排序)
- val w1 = Window.partitionBy("id").orderBy(col("level").desc)
- // 2.利用窗口函数的排名进行排名
- val frame1 = frame.withColumn("rank", rank().over(w1)) //利用窗口函数的排名
- frame1.where(col("rank")=== 1).show() //过滤出排名第一的数据
最后过滤出排名是第一的数据
语句分析:
1.val w1 = Window.partitionBy("id").orderBy(col("level").desc)
首先是对"id"列进行了分组然后对“level”列进行了降序排序
2.frame.withColumn("rank", rank().over(w1))
然后添加了rank列,并插入排名数值
注意事项:
rank(): 可以是其他的函数代替起到不一样的效果
结果展示:
总结
窗口函数首先先进行分组(partition by),在进行排序(order by)。再用序号函数用over方法进行调用返回排名序号

