
热门标签
热门文章
- 1使用ROS开发过程中遇到的问题以及解决方案汇总(更新中)_ros find package有问题
- 2关于用fiddler抓包后iPhone手机连不上网_fd抓包苹果手机不能上网
- 3新建微服务模块Maven子工程_创建maven子项目
- 4[oeasy]教您玩转python - 0003 - 编写 py 文件_oeasy.python3.py免费自学网站官网
- 5Ollama:一个在本地部署、运行大型语言模型的工具_ollama支持多卡吗
- 6(19)批量添加微信好友-微信UI自动化(.Net+C#)_自动化操作微信添加好友c#
- 7C++数据结构-冒泡排序及其优化_{46,74,16,53,14,26,40,38,86,65,27,34},利用冒泡排序算法
- 8RabbitMQ基本概念介绍_rabbitmq中的几个概念
- 9ajax post data 获取不到数据_jquery ajax post请求,获取不到data
- 10Python爬虫 当当网图书信息_爬取当当网python书籍用bs4爬
当前位置: article > 正文
Yarn HA(高可用)
作者:盐析白兔 | 2024-07-19 15:55:11
赞
踩
yarn ha
Yarn HA
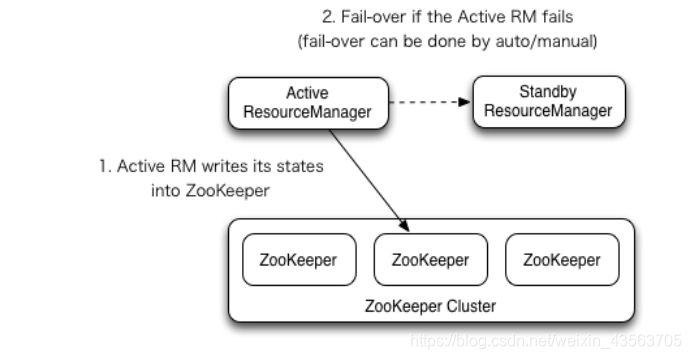
Yarn作为资源管理系统,是上层计算框架(如MapReduce,Spark)的基础。在Hadoop 2.4.0版本之前,Yarn存在单点故障(即ResourceManager存在单点故障),一旦发生故障,恢复时间较长,且会导致正在运行的Application丢失,影响范围较大。从Hadoop 2.4.0版本开始,Yarn实现了ResourceManager HA,在发生故障时自动failover,大大提高了服务的可靠性。
ResourceManager(简写为RM)作为Yarn系统中的主控节点,负责整个系统的资源管理和调度,内部维护了各个应用程序的ApplictionMaster信息、NodeManager(简写为NM)信息、资源使用等。由于资源使用情况和NodeManager信息都可以通过NodeManager的心跳机制重新构建出来,因此只需要对ApplicationMaster相关的信息进行持久化存储即可。
在一个典型的HA集群中,两台独立的机器被配置成ResourceManger。在任意时间,有且只允许一个活动的ResourceManger,另外一个备用。切换分为两种方式:
手动切换:在自动恢复不可用时,管理员可用手动切换状态,或是从Active到Standby,或是从Standby到Active。
自动切换:基于Zookeeper,但是区别于HDFS的HA,2个节点间无需配置额外的ZFKC守护进程来同步数据。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/852301
推荐阅读
相关标签

