
- 1Vscode解决ssh远程连接服务器失败问题_vscode ssh:connect to host :failure
- 2树莓派智能家居中枢
- 3C# Wpf MVVM 框架下的线程并发与异步编程_wpf mvvm 异步
- 4进程写时复制
- 5ERROR: An error occurred while performing the step: “Building kernel modules“.
- 6C/C++学习笔记(2020.11---2021.5)_silicon graphics computer system
- 7IC开发——VCS基本用法_vcs使用
- 8JDK安装及环境变量配置(保姆级教程)_jdk安装及配置教程
- 9在知乎有哪些赚钱的路子
- 10大数据治理关键技术解析
Datawhale AI夏令营 - 用户新增预测挑战赛 | 学习笔记
赞
踩
数据分析与可视化
为了拟合出更好的结果就要了解训练数据之间的相互关系,进行数据分析是必不可少的一步
导入必要的库
- # 导入库
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
pandas库是一个强大的分析结构化数据的python库,是Pythonopen in new window的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
numpy是python中科学计算的基础库,提供多维数组对象,各种派生对象(如掩码数组和矩阵),以及用于数组快速操作的各种API,有包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
可视化的图标能便于分析数据
matplotlib是一个python 2D绘图库,它以多种硬拷贝格式和跨平台的交互式环境生成出版物质量的图形。
seaborn 是一个基于matplotlib进行进行二次封装的绘图库,它也绘制更为集成、复杂的图表。
绘制数据热力图
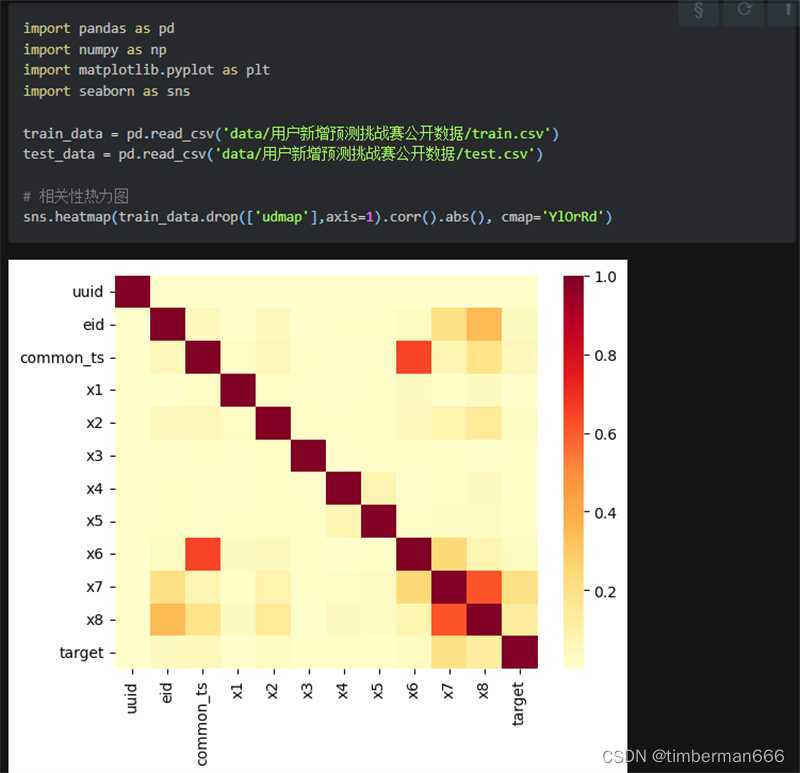
- # 相关性热力图
- sns.heatmap(train_data.corr().abs(), cmap='YlOrRd')
上面是教程给的代码,下面是自己尝试调整了一部分参数后的
- # 相关性热力图
- fig, ax = plt.subplots(figsize=(18,18))#设置画布大小
- sns.heatmap(
- train_data.corr(),
- square=True,
- annot=True,
- vmax=1,
- vmin=0,
- annot_kws={'size': 5},
- linewidths=0.3, # 控制每个小方格之间的间距
- linecolor="white", # 控制分割线的颜色
- cmap="RdBu_r"
- )
绘制直方图
- # x7分组下标签均值
- sns.barplot(x='x7', y='target', data=train_data)
模型交叉验证
交叉验证(Cross-Validation)是机器学习中常用的一种模型评估方法,用于评估模型的性能和泛化能力。
简单来说就是通过数据评估不同模型,避免过拟合或欠拟合,从而可以找到性能最优的模型。
上面的代码验证评估了四个模型,通过输出结果,其实不难发现,树模型的macro F1效果好
一般的,随机森林(RandomForestClassifier)效果比决策树(DecisionTreeClassifier)好一些,本题经过一定特征工程后亦是如此。
特征工程
通过进行特征工程,我们可以优化训练数据,使得得到的模型的性能提升
教程给了如上的特征处理,经过训练,发现common_ts_day与x1_mean,x2_mean是其中对提升精度影响比较大的特征
数据清洗 -- 缺失值与异常值处理
训练模型时遇到报错:ValueError:Input contains NaN, infinity or a value too large for dtype('float64').
处理异常值(以训练集 train_data 为例):
1.检查特征类型
print(train_data.dtypes()) #打印训练集特征类型2.针对不符合类型训练时抛弃
train_data.drop(['udmap', 'common_ts', 'uuid') #训练时3.无穷值处理
- #检查是否有无穷数据
- print(np.isfinite(train_data).all())
- #或
- print(np.isinf(train_data).all())
-
- #处理
- train_inf = np.isinf(train_data) #提取
- train_data[train_inf] = 0 #替换
在使用 dropna 时遇到删除带有缺失值行数据失败的情况:
这里是因为 NaN 是一个空字符串, 但 dropna 并不会将空字符串当作缺失值处理, 所以没能成功删除
同时,因为删除带有缺失值的行会改变行数,处理测试集 test_data 后会导致提交平台检测出错误
所以采用填充处理
最简单的是用 0 填充
train_data.fillna(0) #将 NaN 替换成 0也可以使用 replace()
- train_data.replace("0",np.nan,inplace=True) #将缺失值替换成 0
- #如果在其他项目中这里也可以替换成 "nan" 然后使用 dropna
缺失值填补有很多方法
1.人工填补 2.平均数填补 3.众数填补 4.中位数填补 5.临近数填补
等等等等,还可以采用一些算法进行填补
1.独热编码(One-HotEncoding)
可以扩充特征,采用N位状态寄存器来对N个可能的取值进行编码,每个状态都由独立的寄存器来表示
baseline 中的函数 udmap_onethot :
- # 定义函数 udmap_onethot,用于将 'udmap' 列进行 One-Hot 编码
- def udmap_onethot(d):
- v = np.zeros(9) # 创建一个长度为 9 的零数组
- if d == 'unknown': # 如果 'udmap' 的值是 'unknown'
- return v # 返回零数组
-
- d = eval(d) # 将 'udmap' 的值解析为一个字典
- for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身
- if 'key' + str(i) in d: # 如果当前键存在于字典中
- v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上
-
- return v # 返回 One-Hot 编码后的数组
对星期进行 One-Hot 编码 :
- # 定义函数 week_onethot,用于将 'common_ts_week' 列进行 One-Hot 编码
- def week_onethot(d):
- v = np.zeros(7)
- if d == 'Sunday':
- v[0] = 1
- elif d == 'Monday':
- v[1] = 1
- elif d == 'Tuesday':
- v[2] = 1
- elif d == 'Wednesday':
- v[3] = 1
- elif d == 'Thursday':
- v[4] = 1
- elif d == 'Friday':
- v[5] = 1
- elif d == 'Saturday':
- v[6] = 1
- return v

2.特征二元化
将数值型的属性转换为布尔值的属性,设定一个阈值或条件划分属性值为0或1
简单来说就是将特征分成两部分,用 1 / 0 区分是否满足某条件
baseline 中的 udmap_isunknown :
- # 编码 udmap 是否为空
- train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
- test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
判断 x7 是否为 1 :
- # 特征 x7 是否为 1
- train_data['x7_is1'] = train_data['x7'].apply(lambda d : d == 1)
- test_data['x7_is1'] = test_data['x7'].apply(lambda d : d == 1)

