
- 1[转]大数据环境搭建步骤详解(Hadoop,Hive,Zookeeper,Kafka,Flume,Hbase,Spark等安装与配置)_大数据集群搭建,hadoop,hive,hbase
- 22024年最新如何安装Pycharm最新版本-详细教程_pycharmeve和arm64,2024年最新C C++开发最佳实践手册全网独一份_pycharm2024安装教程
- 35.gradle配置和project_gradle implementation project
- 4【秋招总结】双非本小菜鸡的坎坷秋招之路(附面经)_古茗offer 3天
- 5Allure精通指南(02)Mac和Windows系统环境配置_allure配置环境变量
- 6如何把自己的数据分享给chatgpt让它处理你的数据_分享用gpt写的
- 7资讯|WebRTC M90 更新_webrtc m100
- 8物体检测框架 RetinaNet 深度神经网络简介
- 9江大白 | 基于Pytorch框架,从零实现Transformer模型实战(建议收藏!)_transformer实战
- 10SQL注入之WAF绕过技巧_sql绕过waf的方法
NLP[1] -《基于PyTorch的自然语言处理》_prelu() missing 1 required positional arguments: "
赞
踩
新书《基于PyTorch的自然语言处理》的详细笔记!
主要是对这本书的代码部分的理解和处理,整理了处理方法的过程,这样可以给刚刚步入NLP的学者提供一些帮助。
博客的内容是按照文章章节的部分来整理的,大家可以选择部分内容进行学习。
欢迎转载,转载请注明出处:https://blog.csdn.net/qq_41709378/article/details/113354298
第1章 概述
这部分主要是介绍了PyTorch中张量的基本概念,张量的类型大小,张量的基本操作,索引,切片和连接。
这里解决习题的代码:
import torch # 1.随机创建一个二维张量,然后第0维插入1个维度 a = torch.rand(3, 3) a.unsqueeze(0) print(a) # 2.去掉刚刚加入张量上的维度 a.squeeze(0) print(a) # 3.在区间[3, 7]中创建一个形状为5*3的随机向量 a = 3 + torch.rand(5, 3)*(7-3) print(a) # 4.创建一个具有正态分布(mean = 0, std = 1)值的张量 a = torch.rand(3,3) a.normal_() print(a) print(a.normal_()) # 5.找到torch.Tensor([1,1,1,0,1])中所有非零元素的索引 a = torch.Tensor([1,1,1,0,1]) print(torch.nonzero(a)) # 6.创建一个大小为(3,1)的随机张量,水平扩展4个副本 a = torch.rand(3,1) print(a.expand(3, 4)) # 7.返回两个3维矩阵的乘积(a=torch.rand(3,4,5), b=torch.rand(3,5,4)) a = torch.rand(3,4,5) b = torch.rand(3,5,4) print(torch.bmm(a,b)) # 8.返回一个3维矩阵和一个2维矩阵的乘积(a=torch.rand(3,4,5), b=torch.rand(5,4)) a = torch.rand(3,4,5) b = torch.rand(5,4) print(b.unsqueeze(0).expand(a.size(0), *b.size())) print(torch.bmm(a, b.unsqueeze(0).expand(a.size(0), *b.size())))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
这部分其他知识点的内容:
1.1 损失函数
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
(1)0-1损失函数(zero-one loss)

(2)log对数损失函数

(3)平均绝对误差损失函数


(4)均方差损失函数

假设模型预测与真实值之间的误差服从标准高斯分布,也就是说在模型输出与真实值的误差服从高斯分布的假设下,最小化均方差损失函数与极大似然估计本质上是一致的,因此在这个假设能被满足的场景中(比如回归),均方差损失是一个很好的损失函数选择;当这个假设没能被满足的场景中(比如分类),均方差损失不是一个好的选择。
(5)交叉熵损失函数

1.交叉熵函数与最大似然函数的联系和区别?
区别: 交叉熵函数使用来描述模型预测值和真实值的差距大小,越大代表越不相近;似然函数的本质就是衡量在某个参数下,整体的估计和真实的情况一样的概率,越大代表越相近。
联系: 交叉熵函数可以由最大似然函数在伯努利分布的条件下推导出来,或者说最小化交叉熵函数的本质就是对数似然函数的最大化。
最小化交叉熵函数的本质就是对数似然函数的最大化。
交叉熵损失应该算作是log损失的一个特例,相当于将log损失应用在数据分布为伯努利分布的情况下,
如果我们把数据分布换成高斯分布,那么log损失便会退化为均方损失,
换成laplace分布,会退化为绝对值损失。
2.在用sigmoid作为激活函数的时候,为什么要用交叉熵损失函数,而不用均方误差损失函数?
其实这个问题求个导,分析一下两个误差函数的参数更新过程就会发现原因了。
由于激活函数sigmoid的特点,在z取大部分的时候,求导后的值会很小,使得模型参数更新的时间会很长,如果使用均方误差损失函数,在使用梯度下降更新参数时,可以看到参数更新中具有sigmoid函数求导这一项,
而使用了交叉熵损失函数后,参数迭代的过程中是不含有这一项:
可以看到参数更新公式中没有sigmoid求导这一项,权重的更新受sigmoid 影响,受到误差的影响,
所以当误差大的时候,权重更新快;当误差小的时候,权重更新慢。这是一个很好的性质。
所以当使用sigmoid作为激活函数的时候,常用交叉熵损失函数而不用均方误差损失函数。

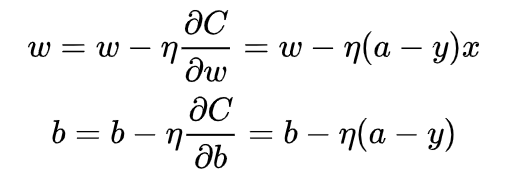
参考文章:
(1)https://zhuanlan.zhihu.com/p/58883095
(2)https://zhuanlan.zhihu.com/p/77686118
(2)one-hot编码
(3)梯度下降
(4)TF 和 TF-IDF
(1)TF-IDF算法介绍及实现:
https://blog.csdn.net/asialee_bird/article/details/81486700
https://www.cnblogs.com/lianyingteng/p/7755545.html
第2章 自然语言处理
刚开始使用spacy包时,导入“en”.
import spacy
nlp = spacy.load("en")
text = "Mary, don't slap the green witch"
print([str(token) for token in nlp(text.lower())])
- 1
- 2
- 3
- 4
会出现以下问题:
OSError: [E050] Can’t find model ‘en’.
It doesn’t seem to be a shortcut link, a Python package or a valid path to a data directory
- 1
- 2
解决方法一:
参考博客:https://blog.csdn.net/mr_muli/article/details/111592360
from spacy.lang.en import English
# 如下会报错:
# import spacy
# spacy_en = spacy.load('en')
# return lambda s: [tok.text for tok in spacy_en.tokenizer(s)]
# 替换之后:
from spacy.lang.en import English
spacy_en = English()
return lambda s: [tok.text for tok in spacy_en.tokenizer(s)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
解决方法二:
参考博客:https://github.com/hamelsmu/Seq2Seq_Tutorial/issues/1
参考博客:https://www.cnblogs.com/zrdm/p/8667131.html(这个是解决方法)
点击en_core_web_sm获得en_core_web_sm-2.2.0.tar
获得en_core_web_sm-2.2.0.tar后:
参考这篇博客:https://www.cnblogs.com/xiaolan-Lin/p/13286885.html
然后执行:
pip install en_core_web_sm-2.2.0.tar.gz
- 1
最后,代码如下:
import spacy
nlp = spacy.load("en_core_web_sm")
# nlp = spacy.load('en')
text = "Mary, don't slap the green witch"
print([str(token) for token in nlp(text.lower())])
- 1
- 2
- 3
- 4
- 5
- 6
这里第二章中的习题代码:
""" 第二章:自然语言处理 """ # 例2-1:文本分词 """ from spacy.lang.en import English # 如下会报错: # import spacy # spacy_en = spacy.load('en') # return lambda s: [tok.text for tok in spacy_en.tokenizer(s)] # 替换之后: from spacy.lang.en import English spacy_en = English() return lambda s: [tok.text for tok in spacy_en.tokenizer(s)] """ import spacy nlp = spacy.load("en_core_web_sm") # nlp = spacy.load('en') text = "Mary, don't slap the green witch" print([str(token) for token in nlp(text.lower())], '\n') from nltk.tokenize import TweetTokenizer tweet = u"Snow White and the Seven Degrees MakeAMovieCold@midnight:-)" tokenizer = TweetTokenizer() print(tokenizer.tokenize(tweet.lower()), "\n") # 例2-2:从文本生成n元模型 def n_grams(text, n): return [text[i:i+n] for i in range(len(text)-n+1)] cleand = ['mary', ',', "n't", 'slap', 'green', 'witch', '.'] print(n_grams(cleand, 3), "\n") # 例2-3:词形还原:将单词还原为词根形式 import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("he was running late") for token in doc: print('{} --> {}'.format(token, token.lemma_)) print("\n") # 例2-4:词性标注 import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("Mary slapped the green witch.") for token in doc: print('{} --> {}'.format(token, token.pos_)) print("\n") # 例2-5 名词短语(NP)分块 import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("Mary slapped the green witch.") for chunk in doc.noun_chunks: print('{} --> {}'.format(chunk, chunk.label_)) print("\n")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
第3章 神经网络基础
在学习 例3-5 时,会报错:
TypeError: prelu() missing 1 required positional arguments: "weight"
- 1
解决方法:
这里我们,需要加入权重a,注意的是加入权重a的类型为:torch.FloatTensor
# 例3-5:PRelu激活函数
import torch
import matplotlib.pyplot as plt
import numpy as np
prelu = torch.nn.PReLU(num_parameters = 1)
x = torch.range(-5., 5., 0.1)
a = torch.tensor([0.25]) # a为torch.FloatTensor数据类型
# a = torch.from_numpy(np.array(0.25)).int() # 运用form_numpy()可以实现类型转换
y = torch.prelu(x, a)
plt.plot(x.numpy(), y.numpy())
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
第4章 用于自然语言处理的前馈网络
第5章 嵌入单词和类型
(1)[NLP] 秒懂词向量Word2vec的本质:
https://zhuanlan.zhihu.com/p/26306795


