
- 1牛客 2022年中国高校计算机大赛-团队程序设计天梯赛(GPLT)上海理工大学校内选拔赛 签到题13题_2022gplt团体程序设计天梯赛a+b
- 2将数据库表导入到solr索引
- 3Pytorch教程入门系列5----神经网络核心torch.nn工具箱介绍
- 4第一篇【传奇开心果系列】AI工业应用经典算法和Python示例:基于AI的智能制造技术经典算法与Python实践_python与智能制造
- 5JS的Set的使用_js set.add
- 6【python】爬取百度热搜排行榜Top50+可视化【附源码】【送数据分析书籍】_python爬取百度热榜
- 7搭建Hadoop3.x完全分布式集群(CentOS 9)_192.168.121.160多台虚拟机
- 8MySQL 复合主键(Day02)_复合主键不能重复吗
- 9Oracle Performance Tuning 11g2 (2-1)
- 10Unity 编辑器篇|(一)MenuItem菜单栏_unity menuitem
Java知识点梳理-高级部分_java高级知识点
赞
踩
前言
一、多线程
1、并行与并发
- 并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。
- 并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。并发往往在场景中有公用的资源,那么针对这个公用的资源往往产生瓶颈,我们会用TPS或者QPS来反应这个系统的处理能力。
2、线程状态
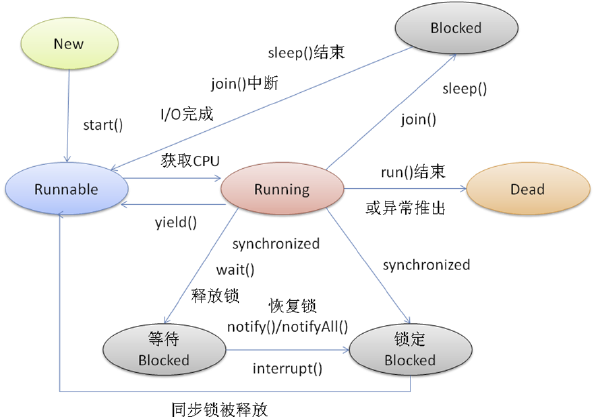
线程在Running的过程中可能会遇到阻塞(Blocked)情况:
- 调用join()和sleep()方法,sleep()时间结束或被打断,join()中断,IO完成都会回到Runnable状态,等待JVM的调度。
- 调用wait(),使该线程处于等待池(wait blocked pool),直notify()/notifyAll(),线程被唤醒被放到锁定池(lock blocked pool),释放同步锁使线程回到可运行状态(Runnable);
- 对Running状态的线程加同步锁(Synchronized)使其进入(lock blocked pool
),同步锁被释放进入可运行状态(Runnable)。
3、基本线程类
基本线程类指的是Thread类,Runnable接口,Callable接口。
Thread 类实现了Runnable接口,启动一个线程的方法:
MyThread my = new MyThread();
my.start();
- 1
- 2
Thread类相关方法:
//当前线程可转让cpu控制权,让别的就绪状态线程运行(切换)
public static Thread.yield()
//暂停一段时间
public static Thread.sleep()
//在一个线程中调用other.join(),将等待other执行完后才继续本线程。
public join()
//后两个函数皆可以被打断
public interrupte()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
**关于中断:**它并不像stop方法那样会中断一个正在运行的线程。线程会不时地检测中断标识位,以判断线程是否应该被中断(中断标识值是否为true)。终端只会影响到wait状态、sleep状态和join状态。被打断的线程会抛出InterruptedException。
Thread.interrupted()检查当前线程是否发生中断,返回boolean
synchronized在获锁的过程中是不能被中断的。
中断是一个状态!interrupt()方法只是将这个状态置为true而已。所以说正常运行的程序不去检测状态,就不会终止,而wait等阻塞方法会去检查并抛出异常。如果在正常运行的程序中添加while(!Thread.interrupted()) ,则同样可以在中断后离开代码体
Thread类最佳实践:
写的时候最好要设置线程名称 Thread.name,并设置线程组 ThreadGroup,目的是方便管理。在出现问题的时候,打印线程栈 (jstack -pid) 一眼就可以看出是哪个线程出的问题,这个线程是干什么的。
如何获取线程中的异常
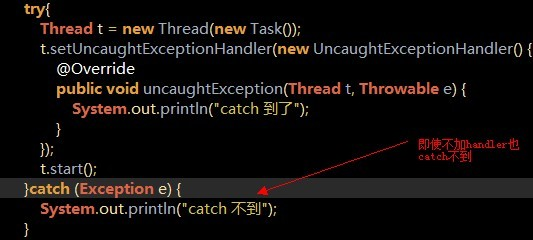
不能用try,catch来获取线程中的异常
- Runnable
与Thread类似
- Callable
future模式:并发模式的一种,可以有两种形式,即无阻塞和阻塞,分别是isDone和get。其中Future对象用来存放该线程的返回值以及状态
ExecutorService e = Executors.newFixedThreadPool(3);
//submit方法有多重参数版本,及支持callable也能够支持runnable接口类型.
Future future = e.submit(new myCallable());
future.isDone() //return true,false 无阻塞
future.get() // return 返回值,阻塞直到该线程运行结束
- 1
- 2
- 3
- 4
- 5
4、高级多线程控制类
4.1 ThreadLocal类
用处:保存线程的独立变量。对一个线程类(继承自Thread)
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。常用于用户登录控制,如记录session信息。
实现:每个Thread都持有一个TreadLocalMap类型的变量(该类是一个轻量级的Map,功能与map一样,区别是桶里放的是entry而不是entry的链表。功能还是一个map。)以本身为key,以目标为value。
主要方法是get()和set(T a),set之后在map里维护一个threadLocal -> a,get时将a返回。ThreadLocal是一个特殊的容器。
ThreadLocal的内存泄露原因
由于Thread中包含变量ThreadLocalMap,因此ThreadLocalMap与Thread的生命周期是一样长,如果都没有手动删除对应key,都会导致内存泄漏。
但是使用弱引用可以多一层保障:弱引用ThreadLocal不会内存泄漏,对应的value在下一次ThreadLocalMap调用set(),get(),remove()的时候会被清除。
因此,ThreadLocal内存泄漏的根源是:由于ThreadLocalMap的生命周期跟Thread一样长,如果没有手动删除对应key就会导致内存泄漏,而不是因为弱引用。
ThreadLocal正确的使用方法
每次使用完ThreadLocal都调用它的remove()方法清除数据
将ThreadLocal变量定义成private static,这样就一直存在ThreadLocal的强引用,也就能保证任何时候都能通过ThreadLocal的弱引用访问到Entry的value值,进而清除掉 。
4.2 原子类
常用原子类:
AtomicBoolean、AtomicIndteger、AutomicLong 元老级的原子更新,方法几乎一模一样
DoubleAdder、LongAdder 对Double、Long的原子更新性能进行优化提升
DoubleAccumulator、LongAccumlator 支持自定义运算
- 1
- 2
- 3
原子更新数组类型
AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
- 1
原子的更新属性
原子的更新某个类里的字段时,需要使用原子更新字段类,AtomicStampedReference、AtomicReference、FiledUpdater
- 1
参阅:https://blog.csdn.net/sinat_36265222/article/details/86636949
https://blog.csdn.net/weixin_38003389/article/details/88569336
4.3 Lock类
使用ReentrantLock实现同步
class MyThread implements Runnable { private int ticket = 10; private Lock lock = new ReentrantLock(); public void run() { //获取对象锁 try { while (this.ticket > 0) { lock.lock(); System.out.println(Thread.currentThread().getName() + "还有" + this.ticket-- + "张票"); lock.unlock(); //释放对象锁 try { Thread.sleep(500); } catch (Exception e) { // TODO: handle exception } } } finally { } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
测试:
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
Thread thread = new Thread(myThread, "黄牛A");
Thread thread1 = new Thread(myThread, "黄牛B");
Thread thread2 = new Thread(myThread, "黄牛C");
thread.start();
thread1.start();
thread2.start();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
使用Condition实现等待/通知
5、容器类
5.1 BlockingQueue
阻塞队列。该类是java.util.concurrent包下的重要类,通过对Queue的学习可以得知,这个queue是单向队列,可以在队列头添加元素和在队尾删除或取出元素。类似于一个管道,特别适用于先进先出策略的一些应用场景。
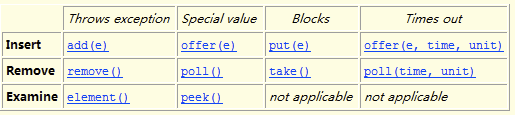
常见的阻塞队列有:
ArrayListBlockingQueue
LinkedListBlockingQueue
DelayQueue
SynchronousQueue
LinkedBlockingQueue :
1、读写锁分开,性能较 ArrayListBlockingQueue 只有一把锁控制读写要高一些。
2、无界队列,不会触发Reject异常,ArrayListBlockingQueue初始化时必须指定宽度。SynchronousQueue的容量只有1。
ArrayListBlockingQueue
1、读写一把锁,在大并发的消费者和生产者场景中,性能较LinkedBlockingQueue差一些。
2、有界队列,会触发Reject异常,在增加队列和删除队列元素时,不会产生额外的数据(数组特性),GC影响比LinkedBlockingQueue更小
SynchronousQueue
1、可以理解为容量为1的阻塞队列,只有被消费了,才能接受生产者的消息。
2、当线程池的线程数已经达到了maxiumSize时,新增加时出发Reject异常
3、有公平策略和不公平策略,对应到不同进出算法 - FIFO,LIFO。
场景归类
无界的消息任务,读写频繁,使用LinkedBlockingQueue
有界的,对GC影响较小,读写不过于频繁的场景,使用ArrayListBlockingQueue
只有一个生产者和消费者,需要使用不同的公平策略的场景,使用 SynchronousQueue
生产者-消费者 简单示例:
package container;
import java.util.Random;
import java.util.concurrent.BlockingQueue;
/** * TODO: * * @Version 1.0 * @Author HJL * @Date 2021/12/19 23:11 */ //生产者 public class Producer implements Runnable { private final BlockingQueue<Integer> blockingQueue; private Random random; public Producer(BlockingQueue<Integer> blockingQueue) { this.blockingQueue = blockingQueue; random = new Random(); } public void run() { while (true) { int info = random.nextInt(100); try { boolean result = blockingQueue.offer(info); System.out.println("生产:" + info + (result? " 成功":"失败!")); Thread.sleep(2000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
/** * TODO: * * @Version 1.0 * @Author HJL * @Date 2021/12/19 23:11 */ //消费者 public class Consumer implements Runnable{ private final BlockingQueue<Integer> blockingQueue; public Consumer(BlockingQueue<Integer> blockingQueue) { this.blockingQueue = blockingQueue; } public void run() { while(true){ Integer info; try { info = blockingQueue.poll(100, TimeUnit.MILLISECONDS); if(null == info) { System.err.println("当前商品紧缺!"); }else { System.out.println("消费:" + info); } Thread.sleep(500); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
public class QueueTest {
public static void main(String[] args) {
ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue(100);
Consumer consumer = new Consumer(blockingQueue);
Producer producer = new Producer(blockingQueue);
Thread thread = new Thread(consumer);
Thread thread1 = new Thread(producer);
thread.start();
thread1.start();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
TimeUnit 使用
主要作用
- 时间颗粒度转换
- 延时
常用的颗粒度
TimeUnit.DAYS //天
TimeUnit.HOURS //小时
TimeUnit.MINUTES //分钟
TimeUnit.SECONDS //秒
TimeUnit.MILLISECONDS //毫秒
- 1
- 2
- 3
- 4
- 5
1、时间颗粒度转换
public long toMillis(long d) //转化成毫秒
public long toSeconds(long d) //转化成秒
public long toMinutes(long d) //转化成分钟
public long toHours(long d) //转化成小时
public long toDays(long d) //转化天
- 1
- 2
- 3
- 4
- 5
5.2 ConcurrentHashMap
在JDK1.7中ConcurrentHashMap采用了数组+Segment+分段锁的方式实现。
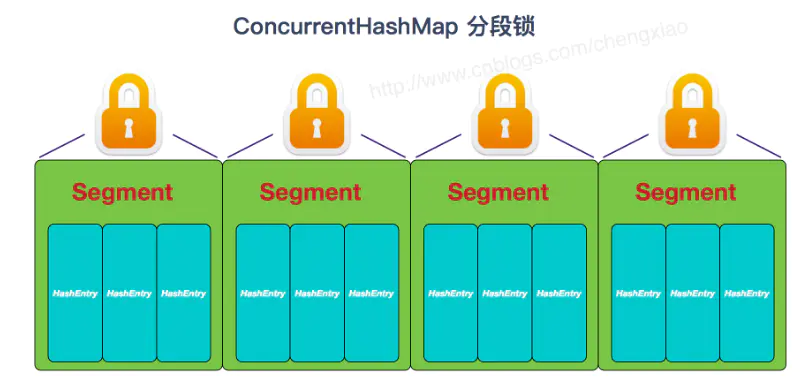
JDK8中ConcurrentHashMap参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作。并发控制使⽤synchronized 和 CAS 来操作。
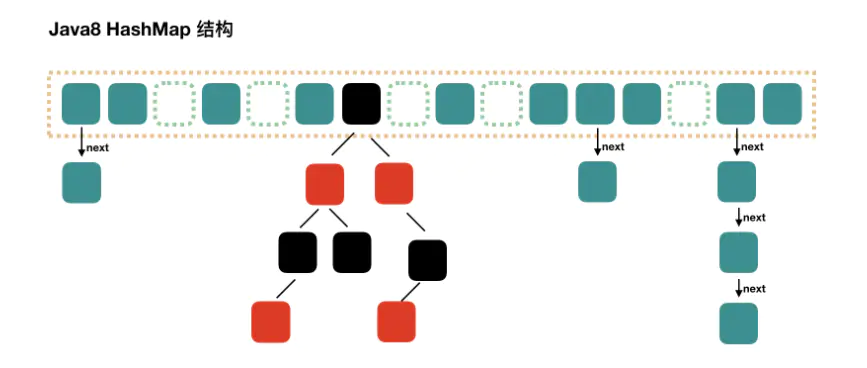
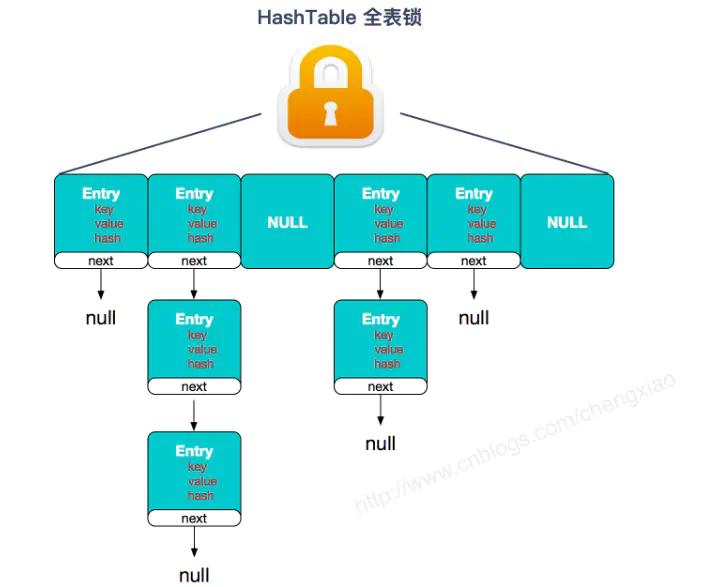
ConcurrentHashMap不论1.7还是1.8,他的执行效率都比HashTable要高的多,主要原因还是因为Hash Table使用了一种全表加锁的方式。
6、管理类
6.1 ThreadPoolExecutor
ExecutorService e = Executors.newCachedThreadPool();
ExecutorService e = Executors.newSingleThreadExecutor();
ExecutorService e = Executors.newFixedThreadPool(3);
// 第一种是可变大小线程池,按照任务数来分配线程,
// 第二种是单线程池,相当于FixedThreadPool(1)
// 第三种是固定大小线程池。
// 然后运行
e.execute(new MyRunnableImpl());
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
二、反射
1、反射机制的功能
Java反射机制主要提供了以下功能:
在运行时判断任意一个对象所属的类。
在运行时构造任意一个类的对象。
在运行时判断任意一个类所具有的成员变量和方法。
在运行时调用任意一个对象的方法。
生成动态代理。
2、 实现反射机制的类
Java中主要由以下的类来实现Java反射机制(这些类都位于java.lang.reflect包中):
Class类:代表一个类。 Field类:代表类的成员变量(成员变量也称为类的属性)。
有三种方式可以获得类的Class对象实例:
1、Object的getClass()方法
// 创建对象,通过对象的getClass()方法获取Class对象实例
Class clazz = new HelloWorld().getClass();
- 1
- 2
2、类型的.class
// 通过类型的class获得Class实例
Class clazz = HelloWorld.class;
- 1
- 2
3、Class.forName(“类的完全限定名”)
// 通过Class.forName("类的完全限定名")获取Class对象实例
try {
Class clazz = Class.forName("com.learn.demo.reflection.HelloWorld");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Method类:代表类的方法。
// 获得类的public成员方法
Method[] methods0 = clazz.getMethods();
- 1
- 2
Constructor类:代表类的构造方法。
// 构造方法-一个int类型参数的构造方法
Constructor constructor0 = clazz.getConstructor(int.class);
Object obj0 = constructor0.newInstance(1);
// 构造方法-一个int类型参数和一个String类型参数的构造方法
Constructor constructor1 = clazz.getConstructor(int.class, String.class);
Object obj1 = constructor1.newInstance(2, "我出生了!");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
获得类的成员变量
// 通过getDeclaredFields方法获取private成员变量
Field [] fields = clazz.getDeclaredFields();
- 1
- 2
Array类:提供了动态创建数组,以及访问数组的元素的静态方法。
//利用Array.newInstance创建一维数组
int rows = 3;
int cols = 2;
Integer[] array = (Integer[]) Array.newInstance(Integer.class,rows);
Array.set(array,0,110);
//利用Array.newInstance创建多维数组
Double[][] arraymn = (Double[][]) Array.newInstance(Double.class,rows,cols);
Array.set(arraymn[0],0,1D);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
三、IO流
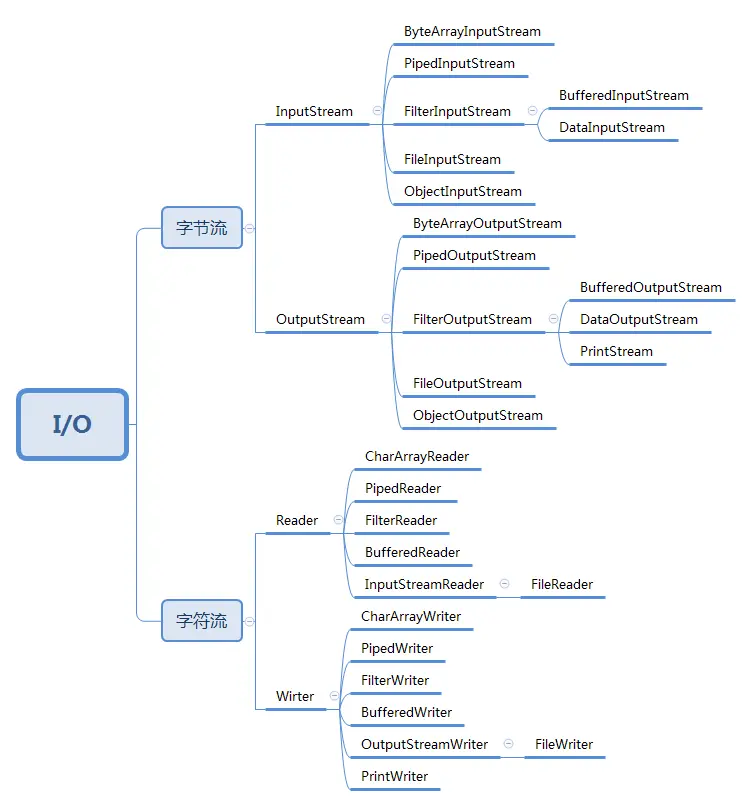
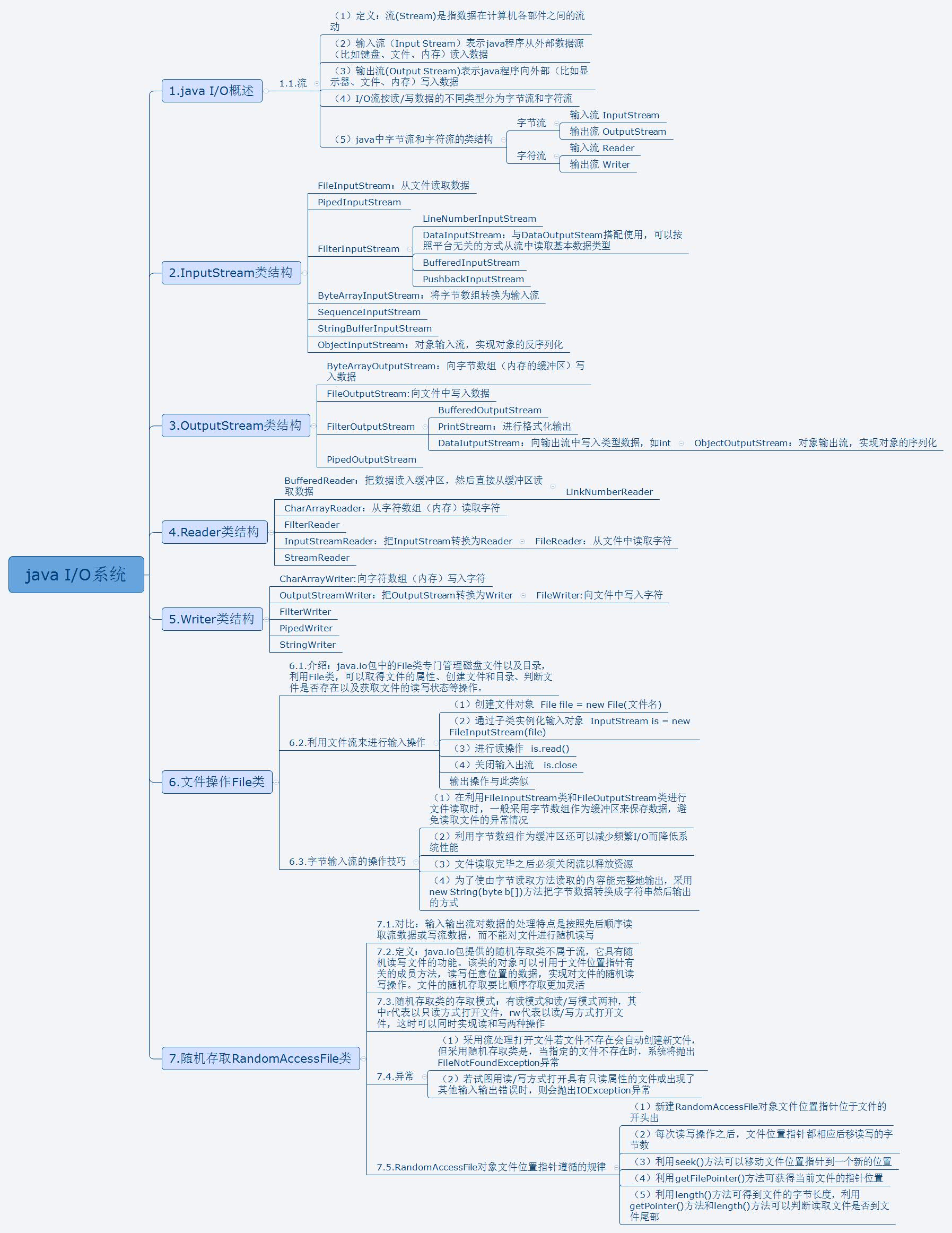
具体参阅:https://www.cnblogs.com/wugongzi/p/12092326.html
四、网络编程
1、网络协议
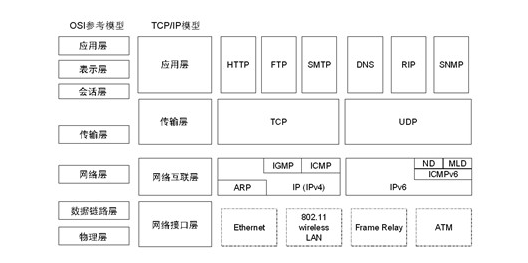
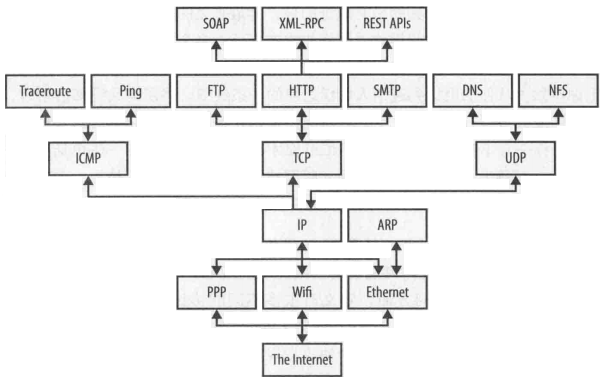
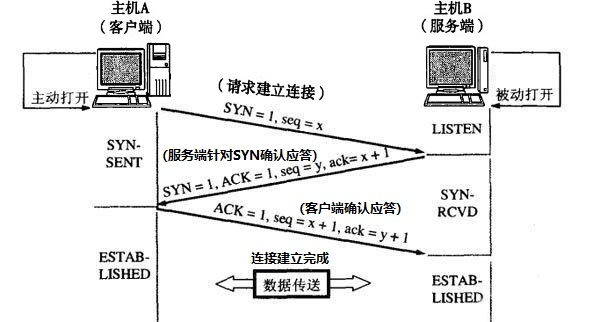
TCP三次握手过程:
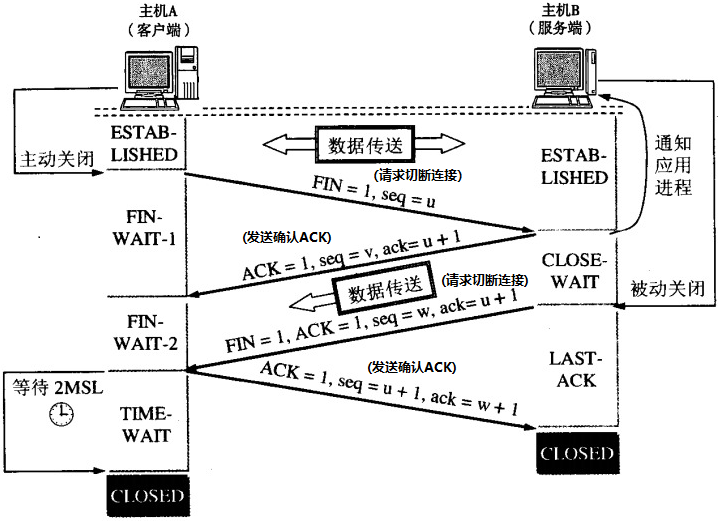
TCP四次挥手过程:
TCP与UDP的区别
- TCP基于连接,UDP是无连接的;
- 对系统资源的要求,TCP较多,UDP较少;
- UDP程序结构较简单;
- TCP是流模式,而UDP是数据报模式;
- TCP保证数据正确性,而UDP可能丢包;TCP保证数据顺序,而UDP不保证;
2、Socket整体流程
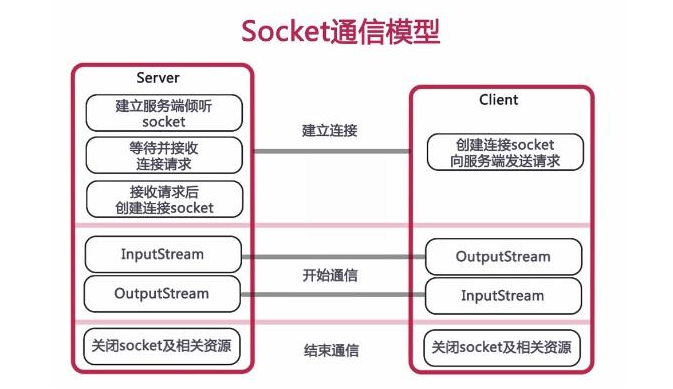
总结
此处记录自己在重温java知识点中的部分重点纪要,对java中的高级基础知识点作一个概括性梳理,铸就更扎实的基础。

