
热门标签
热门文章
- 1JS基础——模拟短信发送对话_模拟短信对话
- 2AI在招聘领域的这些应用,你都知道几个?_hr 生成式ai 应用
- 3python爬取豆瓣电影top250_Python爬虫——爬取豆瓣电影Top250代码实例
- 4bert预测被掩住的字_bert中的掩蔽词预测
- 52024年Python最全13 个Python开发者必知的Python GUI库
- 6自然语言处理中注意力机制综述
- 7【Unity3D开发小游戏】《植物大战僵尸游戏》Unity开发教程_unity植物大战僵尸
- 8分布式系列之分布式锁_分布式锁释放锁时宕机
- 9在wind7中运行启动hadoop出现错误 java.lang.UnsatisfiedLinkError_jvm.jvmmetrics (jvmmetrics.java:init(76)) - initia
- 10Python(十五)读取Excel_python 读excel 遍历
当前位置: article > 正文
【技术类-02】python实现docx段落文字的“手动换行符(软回车)”变成“段落标记(硬回车)”_python docx 段落标记
作者:盐析白兔 | 2024-06-14 01:04:27
赞
踩
python docx 段落标记
作品展示
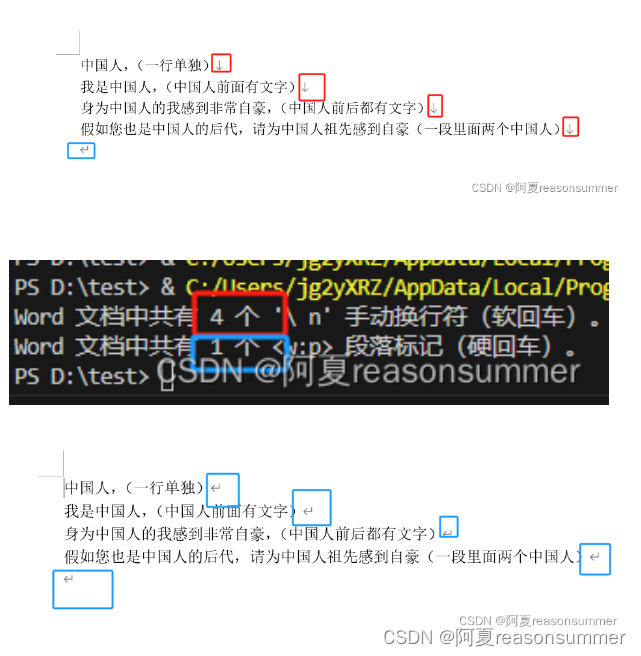
背景需求:
制作周计划时,需要将周计划docx内所有的表格里的手动换行符(软回车)”变成“段落标记(硬回车)”,


全部改成段落标记(硬回车)

但是19份docx每份都要打开,把软回车变成硬回车,就需要Python了
一开始,用替换“转义符”的思路,反复找了两天的代码,都没有成功。只能从头开始研究。
研究过程:
一、在Python里,手动换行符(^l)和段落标记(^p)是什么符号
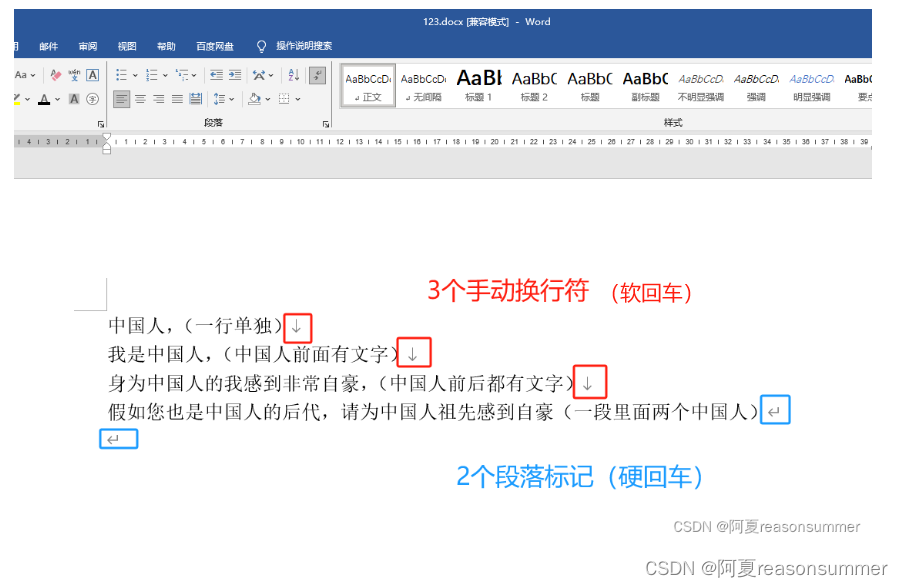
如果某个符号等于3,等于2,说明它们就是手动换行符和段落标记的代码。
AI写了很多编码、16进制、转义符,最终推算获得正确代码,能够计算手动换行符和段落标记的出现的数量。
-
- '''
- 了解在Python里,docx的手动换行符,段落标记用什么符号表示
- 作者:AI 对话大师、百度AI
- 时间:2024年3月15日
- '''
-
- from docx import Document
-
- # 读取Word文档
- doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\测试word换行符\123.docx')
-
- # 初始化换行符计数器
- newline_count = 0
-
- # 遍历文档中的每个段落,统计换行符数量
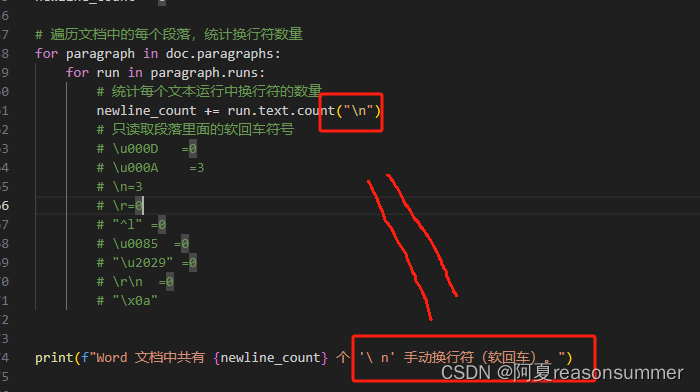
- for paragraph in doc.paragraphs:
- for run in paragraph.runs:
- # 统计每个文本运行中换行符的数量
- newline_count += run.text.count("\n")
- # 只读取段落里面的软回车符号
- # \u000D =0
- # \u000A =3
- # \n=3
- # \r=0
- # "^l" =0
- # \u0085 =0
- # "\u2029" =0
- # \r\n =0
- # "\x0a"
-
-
- print(f"Word 文档中共有 {newline_count} 个 '\ n' 手动换行符(软回车)。")
-
-
- from docx import Document
-
- # 打开 Word 文档
- doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\测试word换行符\123.docx')
-
- # 初始化计数器
- p_count = 0
-
- # 遍历文档中的所有段落
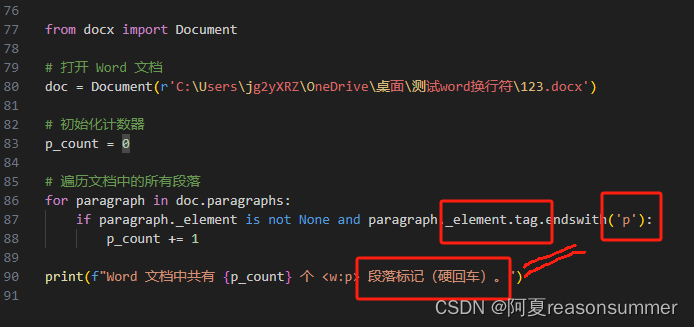
- for paragraph in doc.paragraphs:
- if paragraph._element is not None and paragraph._element.tag.endswith('p'):
- p_count += 1
-
- print(f"Word 文档中共有 {p_count} 个 <w:p> 段落标记(硬回车)。")

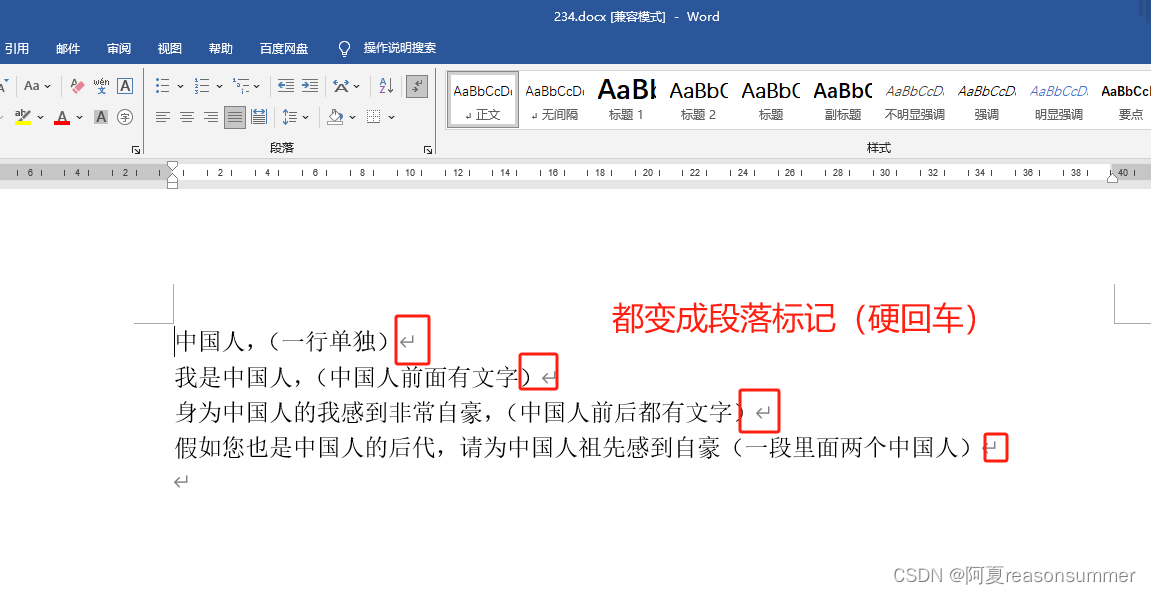
结论:正好3个软回车,2个硬回车

因此说明:
1、'\n'代表docx里面的手动换行符(软回车)——转义符
2、‘段落元素’代表docx里面的段落标记(硬回车)——添加段落增加回车
在以上结论基础上,我用AI对话大师和百度AI生成并测试了无数次,终于将样板的四行段落文字(三行手动换行符+一行硬回车)替换成过了四行硬回车。
替换前
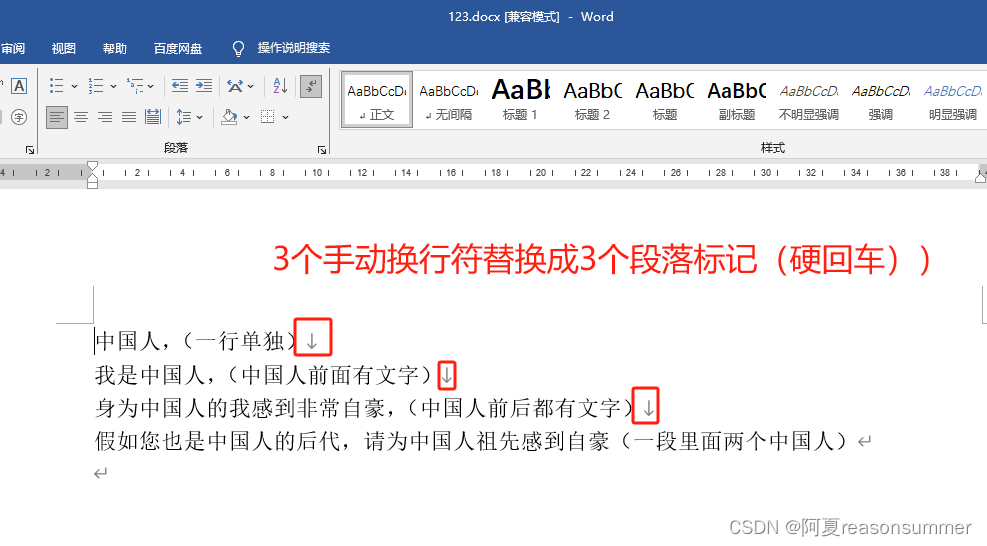
替换后:
代码展示:
- '''
- word段落文字里的手动换行符变成段落标记
- 作者:AI对话大师、百度AI对话
- 时间:2024年3月15日
- '''
-
-
- from docx import Document
- from docx.shared import Pt
-
- # 打开 Word 文档
- doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\测试word换行符\123.docx')
-
- # 用于保存要删除的段落
- paragraphs_to_delete = []
-
- # 遍历文档中的所有段落
- for paragraph in list(doc.paragraphs):
- # 查找段落中的软回车(\n)
- if '\n' in paragraph.text:
- # 分割段落文本,找到软回车的位置
- texts = paragraph.text.split('\n')
-
- # 首先处理第一个文本块
- paragraph.text = texts[0]
-
- # 在软回车的位置插入新的段落
- for text in texts[0:]:
- new_paragraph = paragraph.insert_paragraph_before(text)
- new_paragraph.style = paragraph.style # 保留原始样式
-
- # 将原始段落添加到待删除列表中
- paragraphs_to_delete.append(paragraph)
-
-
- # 删除原来的段落
- for paragraph in paragraphs_to_delete:
- paragraph._element.getparent().remove(paragraph._element)
-
- doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\测试word换行符\234.docx')
通过代码观察:
Python对docx段落文字的替换的原理
1、将手动换行符左侧的内容复制到新列表,然后在原有位置重新段落写入,就会有硬回车。
2、将包含手动换行符的原始段落进行删除。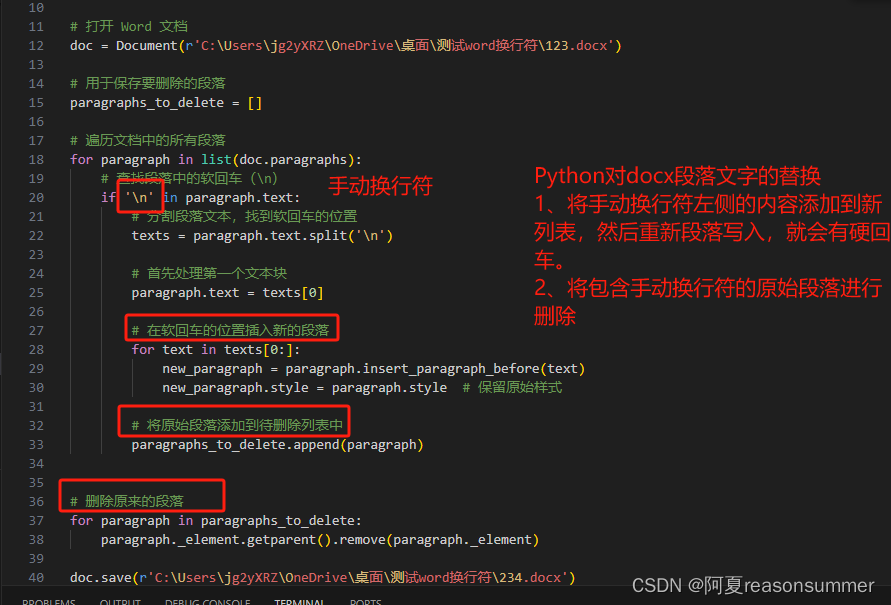
思考:
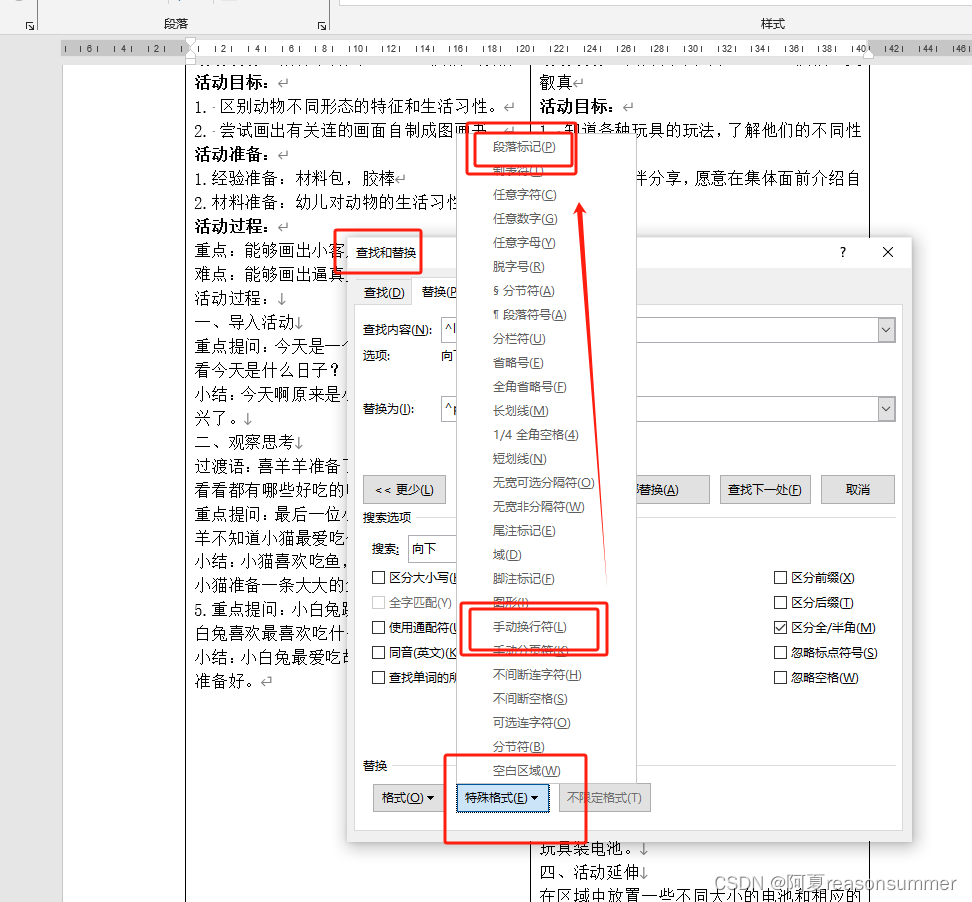
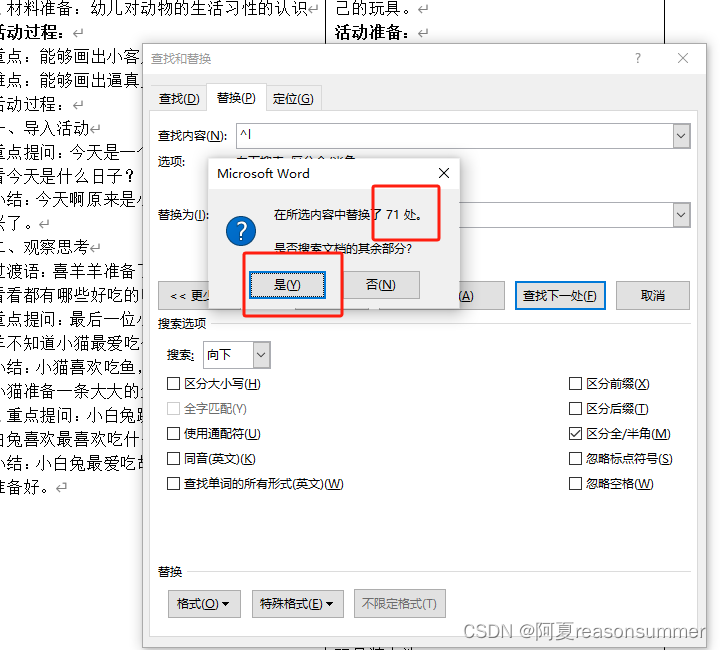
Python的替换与word直接批量查找替换不同,
1、word可以对全文中段落和表格中的手动换行符全部替换,
2、以上Python代码(只涉及paragraphs)只能对word段落文字中的手动换行符进行删除和重新写入段落,从而获得段落标记回车符。
其他测试
把手动换行符与段落标记的位置换一下,看看结果是否有误差。
测试1:

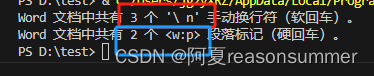

测试2

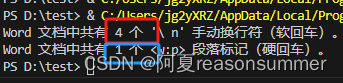

全部代码(计算回车数量+批量删添段落实现回车符)
-
- '''
- 了解在Python里,docx的手动换行符,段落标记用什么符号表示
- 作者:AI 对话大师、百度AI对话
- 时间:2024年3月15日
- '''
-
- from docx import Document
-
- # 读取Word文档
- doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\测试word换行符\123.docx')
-
- # 初始化换行符计数器
- newline_count = 0
-
- # 遍历文档中的每个段落,统计换行符数量
- for paragraph in doc.paragraphs:
- for run in paragraph.runs:
- # 统计每个文本运行中换行符的数量
- newline_count += run.text.count("\n")
- # 只读取段落里面的软回车符号
- # \u000D =0
- # \u000A =3
- # \n=3
- # \r=0
- # "^l" =0
- # \u0085 =0
- # "\u2029" =0
- # \r\n =0
- # "\x0a"
-
-
- print(f"Word 文档中共有 {newline_count} 个 '\ n' 手动换行符(软回车)。")
-
-
- from docx import Document
-
- # 打开 Word 文档
- doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\测试word换行符\123.docx')
-
- # 初始化计数器
- p_count = 0
-
- # 遍历文档中的所有段落
- for paragraph in doc.paragraphs:
- if paragraph._element is not None and paragraph._element.tag.endswith('p'):
- p_count += 1
-
- print(f"Word 文档中共有 {p_count} 个 <w:p> 段落标记(硬回车)。")
-
-
-
- '''
- word段落文字里的手动换行符变成段落标记
- 作者:AI对话大师、百度AI对话
- 时间:2024年3月15日
- '''
-
-
- from docx import Document
- from docx.shared import Pt
-
- # 打开 Word 文档
- doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\测试word换行符\123.docx')
-
- # 用于保存要删除的段落
- paragraphs_to_delete = []
-
- # 遍历文档中的所有段落
- for paragraph in list(doc.paragraphs):
- # 查找段落中的软回车(\n)
- if '\n' in paragraph.text:
- # 分割段落文本,找到软回车的位置
- texts = paragraph.text.split('\n')
-
- # 首先处理第一个文本块
- paragraph.text = texts[0]
-
- # 在软回车的位置插入新的段落
- for text in texts[0:]:
- new_paragraph = paragraph.insert_paragraph_before(text)
- new_paragraph.style = paragraph.style # 保留原始样式
-
- # 将原始段落添加到待删除列表中
- paragraphs_to_delete.append(paragraph)
-
-
- # 删除原来的段落
- for paragraph in paragraphs_to_delete:
- paragraph._element.getparent().remove(paragraph._element)
-
- doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\测试word换行符\234.docx')
-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/715613
推荐阅读

相关标签

