- 1JavaScript基础(前端的知识,很详细,很详细,很详细)_javascript前端
- 2太强了,英伟达面对ChatGPT还有这一招..._英伟达chat gpt
- 3MSCOMCTL.OCX文件缺少找不到如何解决的?
- 4如何为JBoss Developer Studio 8设置BPM和规则工具
- 5设计模式学习笔记 - 设计模式与范式 -结构型:3.装饰器模式
- 6springboot actuator 监控组件应用
- 7汽车自动驾驶是人工智能吗,自动驾驶是人工智能_无人驾驶和人工智能的关系
- 8tp5.0路由配置及thinkphp5.1使用Route路由说明
- 9FISCO BCOS区块链平台上的智能合约压力测试指南_fisco-bcos
- 10图神经网络综述_ggn和gan
排序(rank)后重排(re-rank)?
赞
踩
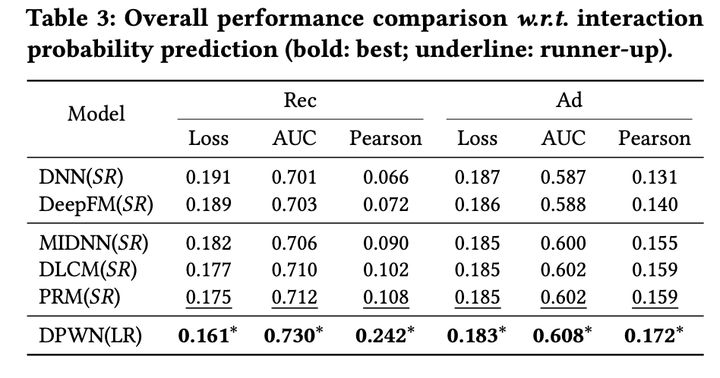
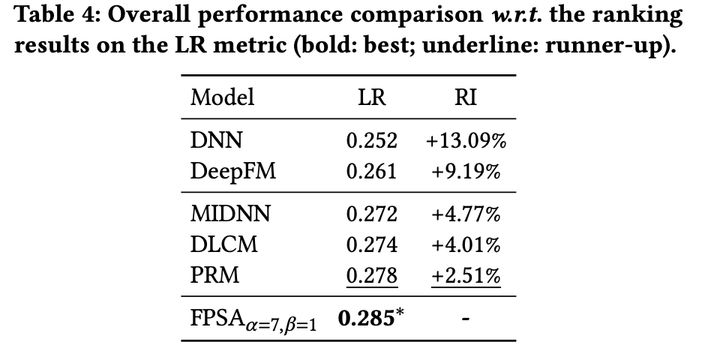
说起排序,对排序的认知还停留在召回阶段召回的item经过粗排过滤,剩下较少的item在精排中打分,按epcm或者其他策略挑选出最终要曝光的item。精排模型往往都是point-wise的,一个DNN加丰富的用户/item/上下文特征预估点击率。自从看了阿里这篇 《Revisit Recommender System in the Permutation Prospective》,了解到了排序完可以再一次重排,以达到用户体验最佳,且平台收益更好。下面就来详细看下重排到底做了啥?

permutation-wise
听过point-wise,pair-wise,也听过list-wise,permutation-wise 还是第一次听。
所以什么是permutation-wise?
见下图:
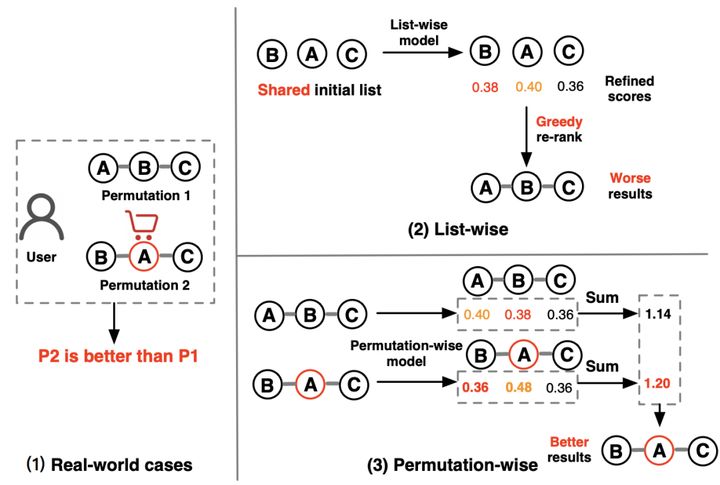
这个图给了个真实的案例,一个User,给他展示了A、B、C就不会买任何item,给他展示了B、A、C就后购买A。What? 论文给了个例子,如果把贵的商品B放前面,用户就会觉得A便宜,值得购买。
好像很有道理,所以我们看到,如果是list-wise的模型给排好序的的B->A->C分别预估一个分(0.38, 0.40, 0.36),然后按照这个分重排序,就会得到A->B->C,用户就不会购买了。
如果我们提供多个候选排列队列: A->B->C和B->A->C,然后把list-wise的分加起来,得到不同排列的分,那就会得到最优解,B->A->C。
但是一般情况下,需要重排序的item可能有上百个,上百个item做排列,再过list-wise模型预估,这是不现实的,于是论文提出了两阶段的重排序框架PRS(Permutation Retrieve System),分别是PMatch阶段和PRank阶段,整体架构如下图所示。

PMatch
PMatch一句话总结就是,把上百个item的排列都给list-wise模型预估排列分不现实,PMatch负责挑选出候选的排列。论文提出了一种permutation-wise和goal-oriented的beam-search算法,称为 FPSA (Fast Permutation Searching Algorithm)。
首先需要离线训练模型,预估item ctr和next score,next score表示用户看完这个item后是否会往下继续浏览。这两个模型都是point-wise的,定义如下:
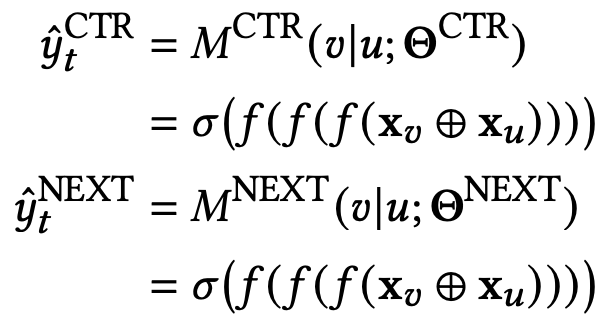
f函数就是relu,loss用log loss即可。
在线的时候,就要用beam search的方法,选择候选排列了。方法如下:

总结一下,就是先对所有待排列的item,预估出ctr和next score,然后设定输出长度n和beam search大小k,还有两个超参数。
beam search不过多介绍,我们看算分的地方,rPV会累加序列中每个item曝光的概率*每个item会带来下次曝光的概率,这个值肯定越大越好,能够让用户更加深度的探索。
rIPV会累加每个item曝光的概率*点击率,这个值越大,表示序列中item被点击的概率更高,因为曝光概率受上一个item影响,所以pExpose *= PNext。最后选择rSum高的排列,进入下一阶段。
PRank
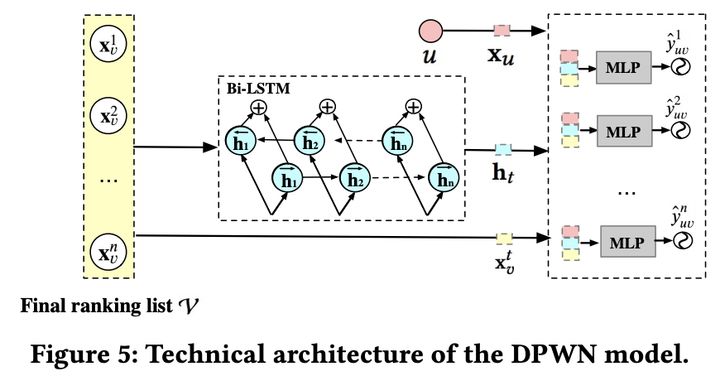
这个阶段就比较简单了,先离线训练一个模型,该模型输入是一个长度为n的序列 (x1, x2, ..., xn),然后输入到Bi-LSTM里,就会得到n个隐向量,每个隐向量concat用户特征和序列中每个item的原始特征,过mlp预测点击率即可:
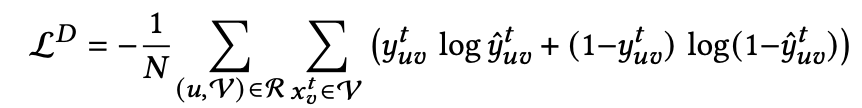
线上服务时,通过上述模型对每个候选排列进行点击率预估,直接把队列中每个物品的预测点击率之和作为评判标准,挑选最终的排列:
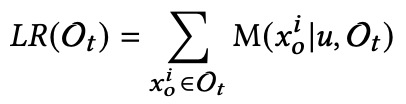
实验
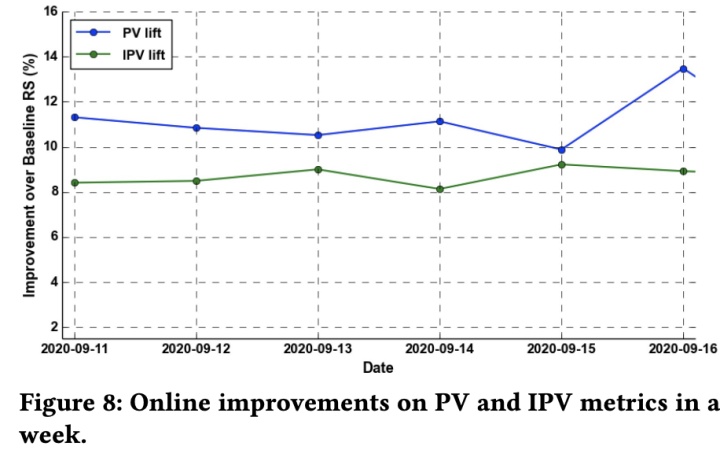
实验结果就是效果贼好,性能还贼优。