
- 1C和C++相互调用 error LNK2001: unresolved external symbol_c++unresolved什么意思
- 2利用低代码从0到1开发一款小程序_小程序低代码
- 3Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本_gpt-4的层数和训练参数
- 4使用org.apache.commons.io.FileUtils,IOUtils;工具类操作文件
- 5shell命令-find常用命令_shell find -exec
- 6Gradle 安装和配置教程_gradle-8.3-bin.zip放哪个位置
- 7《最长的一帧》理解01_场景渲染
- 8负载均衡_用户将请求发送给负载均衡
- 9Apriori算法中使用Hash树进行支持度计数_hash树在apriori算法中的作用
- 10glance服务器上传的镜像支持,openstack-理解glance组件和镜像服务
论文笔记:Are Transformers Effective for Time Series Forecasting?
赞
踩
AAAI 2023 oral
1 Intro
- 自注意力计算是排列不变的(permutation-invariant)
- 虽然使用各种类型的position embedding和temporal embedding后,会保留一些order信息,但仍然时间信息可能会不可避免地丢失
- 本文质疑基于Transformer以进行时间序列预测的有效性
- 现有的基于Transformer的方法,通常比较的baseline是利用自回归、自我迭代来进行预测
- 由于不可避免的误差累积,故而这些baseline的长期预测能力会比较差
- 论文尝试使用一种非常简单的线性模型,直接进行多部预测
- 这个线性模型优于所有Transformer的模型
- 同时大多数Transformer无法从长序列中提取有效的时间关系(预测误差不会随着sliding window的增加而减少)
- 由于并不是所有时间序列都是可以预测的,所以这里只研究趋势和周期相对清晰的时间序列。
- 现有的基于Transformer的方法,通常比较的baseline是利用自回归、自我迭代来进行预测
2 现有模型
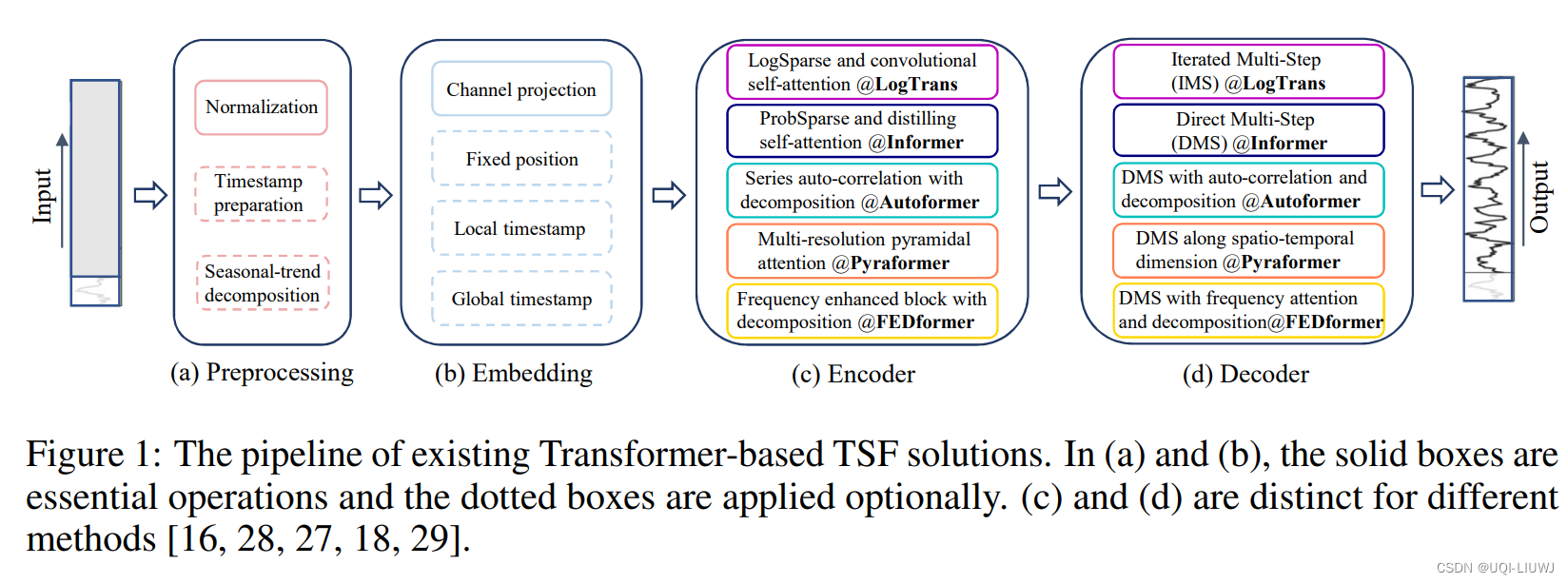
论文笔记 Enhancing the Locality and Breaking the MemoryBottleneck of Transformer on Time Series Forecas_UQI-LIUWJ的博客-CSDN博客论文笔记:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting_UQI-LIUWJ的博客-CSDN博客论文笔记:Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting_UQI-LIUWJ的博客-CSDN博客 论文笔记:PYRAFORMER: LOW-COMPLEXITY PYRAMIDAL ATTENTION FOR LONG-RANGE TIME SERIES MODELING AND FORECAST_UQI-LIUWJ的博客-CSDN博客论文笔记:FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting_UQI-LIUWJ的博客-CSDN博客
2.1 IMS(迭代多步)和DMS(直接多步)
- 与DMS预测结果相比,由于采用了自回归模式,IMS预测的方差较小,但不可避免地会受到误差累积效应的影响。
- 因此,当有一个高度准确的单步的predictor,且T相对较小时,IMS更可取。相比之下,当难以获得无偏的单步预测模型或T较大时,DMS预测会生成更准确的预测
2.2 提出的模型
2.2.0 Linear
直接将N*T的输入序列,通过一个线性层,输出到N*T'的输出序列
2.2.1 Dlinear
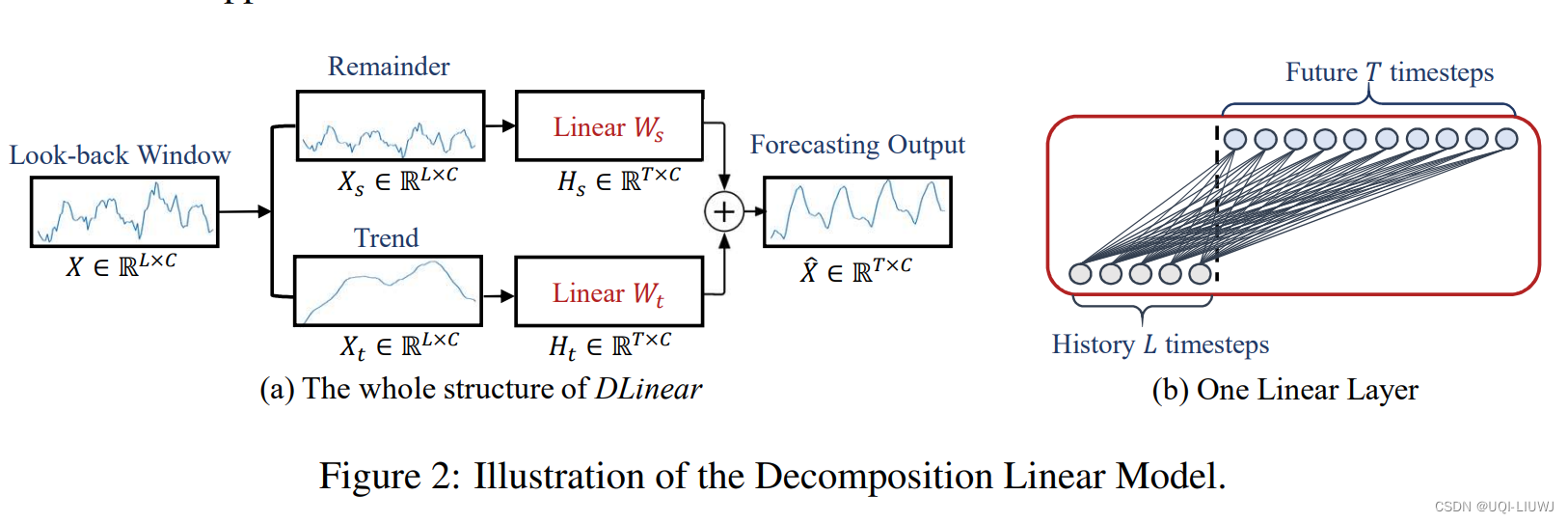
举例:
- 比如现在有一个10个变量的时间序列,历史长度为100,我们要预测未来50个时间步
- 先将原来10*100维的时间序列矩阵分解成两个10*100维的趋势和周期时间序列
- 然后使用100*50的线性映射层,将趋势和周期时间序列转变成10*50维的两个矩阵
- 将他们加和,得到10*50维的输出,这个就是预测的结果
2.2.2 NLinear
- 输入序列首先全部减去 序列的最后一个值
- 将减去后的序列送入一个线性层
- 得到预测结果后,将减去的部分加回来
- (可以将加法和减法看作输入序列的规范化)
3 实验部分
3.1 数据

3,2 实验结果
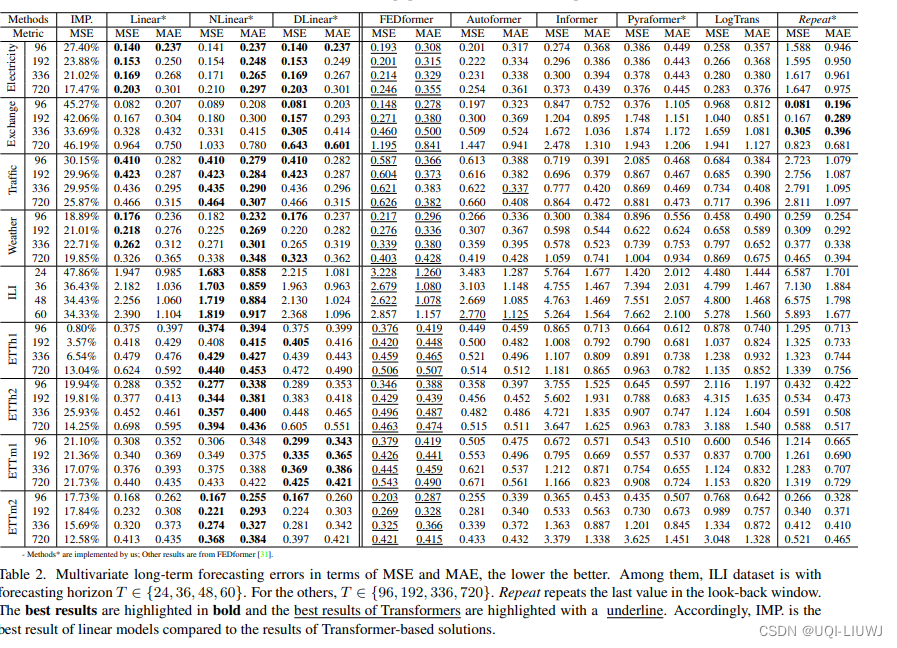
可以看到Linear/DLinear/NLinear效果比Transformer的好
3.3 预测结果可视化
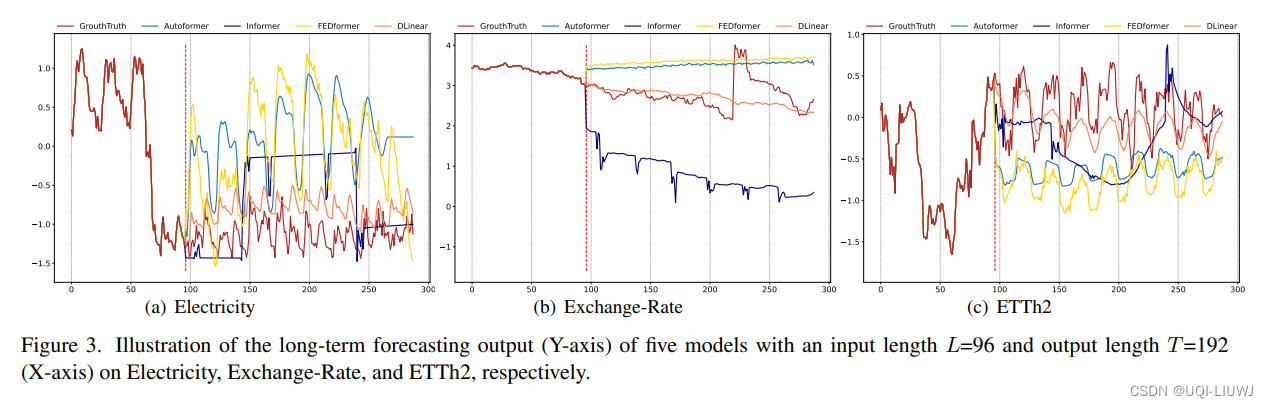
可以看到Linear的效果依旧最好
3.4 输入窗口大小和预测结果的关系
- 为了研究输入回望窗口大小的影响,论文用L进行了实验∈ {24、48、72、96、120、144、168、192、336、504、672、720}用于长期预测(T=720)。
- 下图展示了两个数据集的MSE结果。
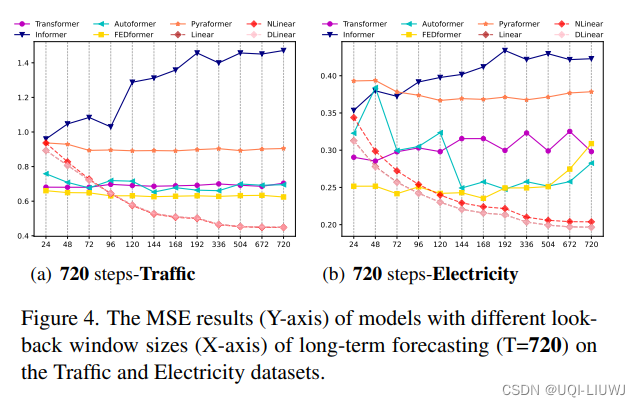
可以看到有些基于Transformer的模型在回望窗口增大时性能会恶化或保持不变。
相比之下,所有LTSF Linear的性能都随着输入窗口大小的增加而显著提高。
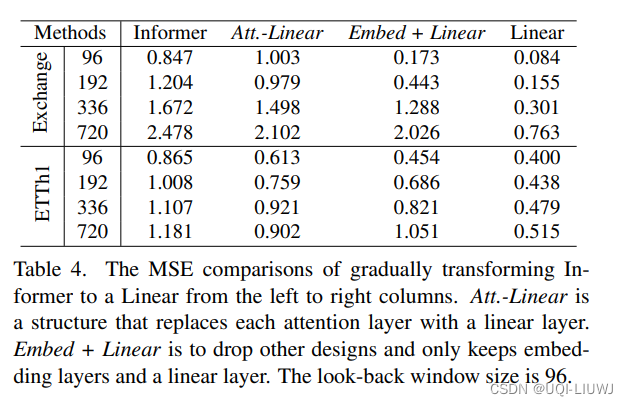
3.5 自注意力对时间序列预测的影响
逐渐将Informer中的组成部分替换成Linear,发现性能随着逐步简化,而不断提高
3.6 Transformer可以维持时间顺序嘛?
在进行embedding 之前,对原始时间序列输入进行shuffle:
- Shuf:随机shuffle整个序列
- Half-Ex:shuffle一半的序列,然后将序列的前半部分和后半部分对调
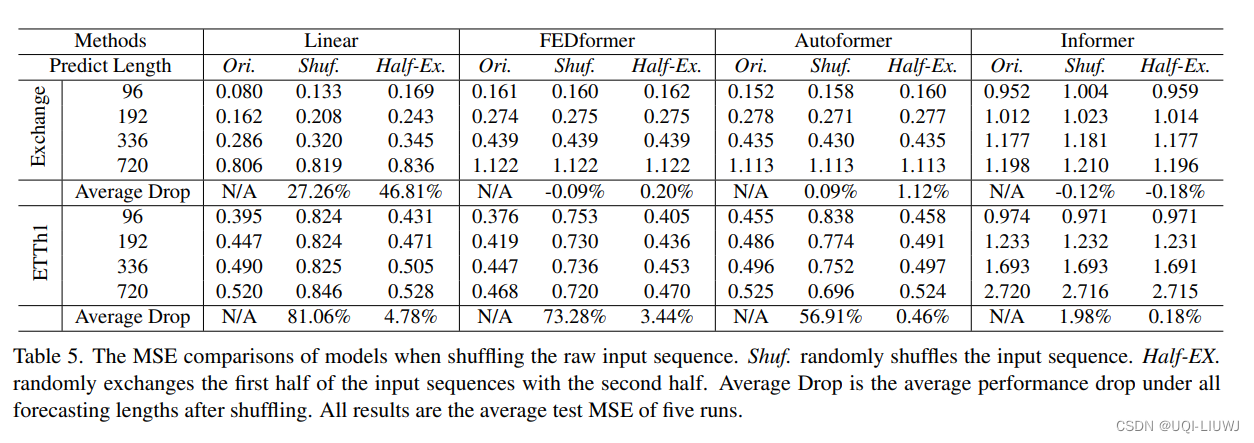
- 与最初的设置相比,所有基于Transformer的方法的性能都没有波动,即使输入序列是随机shuffle的。
- 相反,LTSF Linear的性能受到了严重损害。
- 这表明,具有不同位置和时间嵌入的transformer保留了非常有限的时间关系,并且容易在嘈杂的数据上过拟合,而LTSF线性可以自然建模顺序,并且较少的参数也可以避免过拟合。
3.7 position embedding的有效性
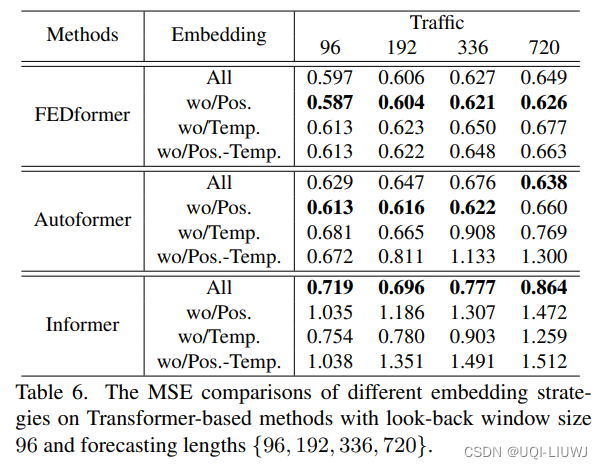
- 如果没有position和temporal embedding,Informer的性能会大大下降(因为INformer是稀疏的逐点乘积attention)
- 而AutoFormer和FedFormer会对temporal embedding和position embedding的敏感度小一些
- AutoFormer是使用Auto-correlation代替逐点乘积attention
- FEDFormer是在谱域上的attention
- 他们都不是单个时间片的attention
3.8 是不是数据集的大小制约了Transformer的学习能力
Ori是一个完整的数据,Short是截断了的数据
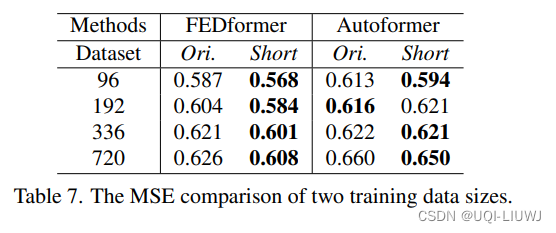
在这里,增加了数据,反而模型效果降低了。

