
热门标签
热门文章
- 1解决Untracked Files Prevent Checkout问题
- 2GPT2代码运行,个人文本生成助手,不依赖OpenAI API调用
- 3【智慧农业】智能灌溉系统应用方案_智慧农业喷淋灌溉项目方案
- 4【提效】让GPT帮你写爬虫程序,不懂爬虫也能行_如何用gpt写爬虫
- 5【网络安全】2024年热门网络安全运营工具/方案推荐_网络安全运营产品
- 6知识图谱---Neo4J篇_neo4j知识图谱
- 7【Shell编程】Shell中for循环、while循环、until循环语句_shell编程for
- 8在小程序中使用formdata上传数据,可实现多文件上传
- 9A Comprehensive Survey on Graph Neural Networks(2020 Trans)_complex-valued neural networks: a comprehensive su
- 10【ROS笔记本】ROS代码编写知识_getnumpublishers();
当前位置: article > 正文
开源免费多语言翻译模型
作者:盐析白兔 | 2024-04-04 00:51:58
赞
踩
翻译模型

今天给大家介绍赫尔辛基大学开源免费的多语言翻译模型,赫尔辛基大学开发了1400多个多语种翻译模型,我们可以在Hugging Face网站上免费下载免费使用这些模型,今天我来介绍其中的中译英和英译中两个模型。
我机器的环境是win11,adaconda,python10,最好在adaconda的环境里创建一个专用的虚拟环境,这样不好导致依赖冲突,我们可以在虚拟环境中需要安装以下包:
- pip install transformers[sentencepiece]
- pip install torch
- pip install sacremoses(可选)
1.模型下载
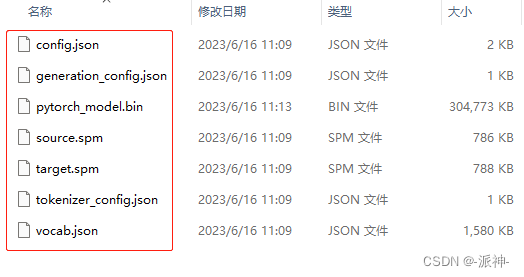
我们需要去Hugging Face的网站下载语言模型和所需文件,下面是中译英和英译中的两个模型所需的文件,并将它们分别存放在两个指定的本地文件夹中:

我们只需下载两个模型的这7个文件即可。
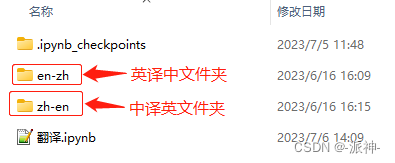
1.中译英
下面我们通过加载本地模型来实现中译英翻译功能:
- from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
- from transformers import pipeline
-
- model_path = './zh-en/'
- #创建tokenizer
- tokenizer = AutoTokenizer.from_pretrained(model_path)
- #创建模型
- model = AutoModelForSeq2SeqLM.from_pretrained(model_path)
- #创建pipeline
- pipeline = pipeline("translation", model=model, tokenizer=tokenizer)
下面我们来实现翻译功能:
- chinese = """
- 六岁时,我家在荷兰的莱斯韦克,房子的前面有一片荒地,
- 我称其为“那地方”,一个神秘的所在,那里深深的草木如今只到我的腰际,
- 当年却像是一片丛林,即便现在我还记得:“那地方”危机四伏,
- 洒满了我的恐惧和幻想。
- """
- result = pipeline(chinese)
- print(result[0]['translation_text'])

- chinese="""
- 谷歌于2019年推出了 53 量子位的 Sycamore 处理器,
- 而本次实验进一步升级了 Sycamore 处理器,已提升达到 70 个量子位。
- 谷歌表示升级 Sycamore 处理器之后,虽然受到相干时间等其它因素的影响,
- 其性能是此前版本的 2.41 亿倍。
- 在实验中,科学家们执行了随机电路采样任务。在量子计算中,
- 这涉及通过运行随机电路和分析结果输出来测试量子计算机的性能,
- 以评估其在解决复杂问题方面的能力和效率。
- """
-
- result = pipeline(chinese)
- print(result[0]['translation_text'])

2.英译中
接下来我们来实现英译中的功能:
- from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
- from transformers import pipeline
-
- model_path = './en-zh/'
- english="""
- China has expanded its share of global commercial services exports from 3 percent \
- in 2005 to 5.4 percent in 2022, according to a report jointly released by \
- the World Bank Group and World Trade Organization earlier this week.
- """
-
- tokenizer = AutoTokenizer.from_pretrained(model_path)
- model = AutoModelForSeq2SeqLM.from_pretrained(model_path)
- pipeline= pipeline("translation", model=model, tokenizer=tokenizer)
-
- finaltext = pipeline(english)
- print(finaltext[0]['translation_text'])


- %%time
- english="Which TV can I buy if I'm on a budget?"
- finaltext = pp(english)
- print(finaltext[0]['translation_text'])

- %%time
- english="""
- The European Union and Japan will increase cooperation around key \
- technologies, including artificial intelligence and computer chip \
- production, the 27-member bloc's commissioner for the internal market \
- has said.
- """
- finaltext = pp(english)
- print(finaltext[0]['translation_text'])

大家可以尝试一下,看看这两个模型的翻译效果怎么样。
参考资料
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/356969
推荐阅读
相关标签

