
- 1【BIM+GIS】Supermap加载实景三维倾斜摄影模型_supermap打开osgb
- 2SSH生成密钥_生成 ssh秘钥 命令
- 3用java计算文本相似度_java 文本相似度
- 4案例21:Java农产品供求信息系统设计与实现开题报告_农产品商品信息系统开题报告
- 5免费的ChatGPT 镜像网站列表_chat.freegpts.org
- 6RTX操作系统教程[02]_rtx教程
- 7解决vmware克隆centos7后重复ip的问题_centos克隆虚拟机后ip与原来一样
- 8用python gdal裁剪栅格数据提取添加xy经纬度和栅格值_python 如何识别栅格图片的经纬度
- 9python gdal 矢量裁剪栅格_gdal tif切图五级之前有偏移
- 10《大道至简》改名记_大道至简,给所有人看的编程书
DCdetector: Dual Attention Contrastive Representation Learning for Time Series Anomaly Detection
赞
踩
时间序列异常检测的双注意对比表征学习 KDD2023
摘要
关键词:时间序列异常检测,对比学习,表示学习,自监督学习
时间序列异常检测对于广泛的应用至关重要。它旨在从时间序列中的正态样本分布中识别出异常样本。这项任务最根本的挑战是学习一个能够有效区分异常的表示图。基于重建的方法仍然占主导地位,但带有异常的表示学习可能会因其巨大的异常损失而损害性能。另一方面,对比学习旨在找到一种能够清晰区分任何实例与其他实例的表示,这可以为时间序列异常检测带来更自然、更有前景的表示。本文提出了一种多尺度双注意对比表征学习模型DCdetector。DCdetector利用一种新颖的双注意不对称设计来创建置换环境和纯对比损失来指导学习过程,从而学习出具有优越判别能力的置换不变表征。大量的实验表明,DCdetector在多个时间序列异常检测基准数据集上取得了最先进的结果。代码可在此URL1公开获取。
一、简介
时间序列异常检测在现实应用中有着广泛的应用,包括但不限于工业设备状态监测、金融欺诈检测、故障诊断、汽车日常监控维护等[3,20,27,57,79]。随着不同传感器的快速发展,在许多不同的应用中,已经在系统运行期间收集了大规模的时间序列数据[44,71,77]。有效发现系统中的异常模式对于确保安全、避免经济损失至关重要[81]。例如,在能源行业中,及时发现风力发电机传感器的异常有助于避免灾难性故障。在金融行业,检测欺诈对于减少经济损失至关重要。
然而,从大量复杂的时间序列中发现异常模式是一项挑战。首先,我们仍在确定这些异常会是什么样子。异常也被称为离群值或新颖性,这意味着观察不寻常的,不规则的,不一致的,意想不到的,罕见的,错误的,或者仅仅是奇怪的,这取决于情况[59]。此外,典型的情况通常是复杂的,这使得很难定义什么是不寻常的或
意外的。例如,风力涡轮机在不同的天气情况下以不同的模式工作。其次,异常通常是罕见的,因此需要工作来获得标签[80]。大多数监督或半监督方法在给定有限的标记训练数据的情况下无法工作。第三,异常检测模型应该考虑时间序列数据的时间、多维和非平稳特征[78]。多维性描述了多元时间序列中维度之间通常存在依赖关系,非平稳性意味着时间序列的统计特征是不稳定的。具体来说,时间依赖性是指相邻点之间存在潜在的相互依赖性。虽然每个点都应该被标记为正常或异常,但将单个点视为样本是不合理的。
为了应对这些挑战,研究人员设计了各种时间序列异常检测方法。它们可以大致为分类为统计、经典机器学习和基于深度学习的方法[6,59]。机器学习方法,特别是基于深度学习的方法,由于其强大的表示优势,已经取得了很大的成功。大多数监督和半监督方法[14,18,51,53,87,90]无法处理有限标记数据的挑战,特别是异
常是动态的,以前从未观察到的新异常可能会出现。无监督方法在对标记数据没有严格要求的情况下很受欢迎,包括基于一类分类、基于概率、基于距离、基于预测、基于重构的方法[11,24,42,59,66,85,92]。
基于重建的方法学习一个模型来重建正态样本,因此无法被学习模型重建的实例是异常。这种方法正在迅速发展,因为它通过将其与不同的机器学习模型相结合来处理复杂数据的能力,以及实例表现异常异常的可解释性。然而,在不受异常阻碍的情况下,为正常数据学习一个重建良好的模型通常是具有挑战性的。在时间序列异常检测中,情况甚至更糟,因为异常的数量是未知的,正常点和异常点可能出现在一个实例中,这使得学习一个干净的、重建良好的法向点模型变得更加困难。
近年来,对比代表性学习因其设计的多样性和在计算机视觉领域下游任务中的突出表现而受到关注[13,15,29,82]。然而,对比代表性学习在时间序列异常检测领域的有效性仍有待探索。本文提出了一种双注意对比表征学习异常检测器dc检测器来解决时间序列异常检测中的难题。我们的dc检测器的关键思想是正态时间序列点共享潜在模式,这意味着正态点与其他点具有很强的相关性。相比之下,异常点则没有(即与其他点的弱相关性)。从不同的观点学习异常的一致表示将是困难的,但对于正常点来说很容易。主要动机是,如果正常点和异常点的表示是可区分的,我们可以在没有高质量重建模型的情况下检测异常。
具体来说,我们提出了一个具有两个分支和双重关注模块的对比结构,两个分支共享网络权重。这个模型是基于两个分支的相似性来训练的,因为正规点占大多数。异常的表示不一致会很明显。因此,如果没有一个高质量的重建模型,正常和异常数据之间的表示差异就会被放大。为了捕捉时间序列中的时间依赖性,dc检测器采用基于补丁的注意力网络作为基本模块。提出了一种多尺度设计,以减少修补过程中的信息丢失。对于多变量时间序列,dc检测器采用通道无关设计,有效地将所有通道表示成表示。特别是,dc检测器不需要事先了解异常情况,因此可以处理以前从未观察到的新异常值。我们的dc检测器的主要贡献总结如下:
•架构:设计了一个基于对比学习的双分支注意结构来学习一个排列不变的表征,该表征扩大了表征差异在正常点和异常点之间。此外,还提出了信道无关补丁来增强时间序列中的局部语义信息。在注意力模块中提出了多尺度,以减少补片过程中的信息丢失。
•优化:基于两个分支的相似性设计了一个有效且鲁棒的损失函数。请注意,该模型是纯粹对比训练的,没有
重建损失,这减少了异常的干扰。
•性能和理由:dc检测器在七个多变量和一个单变量时间序列异常检测基准数据集上实现了与最先进的方法相
当或优越的性能。我们还提供论证讨论,以解释我们的模型如何在没有负样本的情况下避免崩溃。
二、相关工作
在本节中,我们展示了这项工作的相关文献。相关工作包括异常检测和对比表征学习。
时间序列异常检测。检测时间序列异常的方法有很多种,包括统计方法、经典机器学习方法和深度学习方法[63]。统计方法包括使用移动平均线、指数平滑[56]和自回归集成移动平均(ARIMA)模型[9]。机器学习方法包括聚类算法,如k-means[34]和基于密度的方法,以及分类算法,如决策树[35,46]和支持向量机(svm)。深度学习方法包括使用自编码器、变分自编码器(VAEs)[53,61]和循环神经网络(rnn)[12,66],如长短期记忆(LSTM)网络[85]。最近在时间序列异常检测方面的工作还包括基于生成对抗网络(GANs)的方法[16,16,41,91]和基于深度
强化学习(DRL)的方法[30,84]。一般来说,深度学习方法在识别时间序列数据中的异常方面更有效,特别是当数据是高维或非线性的时候。
另一种观点认为,时间序列异常检测模型大致可以分为两类:有监督和无监督异常检测算法。当异常标签可用或负担得起时,监督方法可以表现得更好。这样的方法可以追溯到AutoEncoder[61]、LSTM-VAE[53]、Spectral Residual (SR)[57]、RobustTAD[26]等。另一方面,在异常标签难以获得的情况下,可以应用无监督异常检测算法。这种多功能性导致了社区长期以来对开发新的无监督时间序列异常检测方法的兴趣,包括DAGMM[92]、OmniAnomaly[66]、GDN[24]、RDSSM[42]等。无监督深度学习方法在时间序列异常检测中得到了广泛的研究。其主要原因如下。首先,在现实世界的应用中,通常很难或负担不起获得所有时间序列序列的标签。其次,深度模型在表示学习方面很强大,在无监督设置下有可能获得不错的检测精度。其中大多数是基于重建方法,即为法向点学习一个重建良好的模型;然后,重构失败的实例就是异常。
最近,一些已经提出了基于自监督学习的方法来增强无监督异常检测中的泛化能力[33,88,90]。
对比表征学习(contrast Representation Learning)。对比表示学习的目标是学习一个嵌入空间,在这个空间中,相似的数据样本彼此保持接近,而不相似的数据样本相距很远。对比学习的思想可以追溯到Inst-Dic[73]。经典对比模型创建<正、负>样本对来学习一种表示,其中正样本彼此靠近(拉在一起),远离负样本(推开)[13,15,29,82]。他们的关键设计是关于如何定义负样本和处理高计算能力/大批量需求[37]。另一方面,BYOL[28]和SimSiam[17]消除了负样本的参与,这样一个简单的siamese模型(SimSiam)实现了与其他最先进的复杂架构相当的性能。
利用对比设计使两类样本的距离变大,是很有启发性的。我们尝试通过精心设计的基于多尺度补丁的关注模块来区分时间序列异常点和正态点。此外,我们的dc检测器也没有负样本,即使没有“停止梯度”也不会陷入平凡的解决方案。
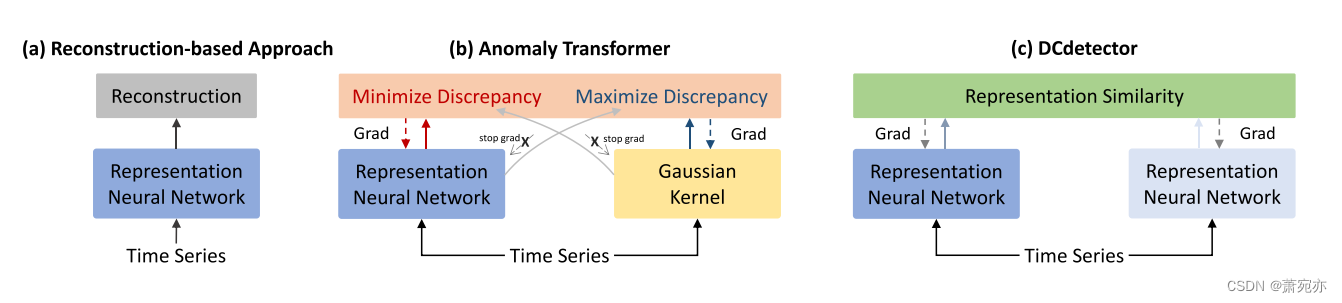
图1:三种方法的架构比较。基于重建的方法使用表征神经网络来学习法线点的模式并进行重建。在Anomaly Transformer中,利用高斯核学习先验差异,利用transformer模块学习关联差异;最小极大关联学习也很关键,并且包含了重建损失。dcdetector简洁,没有特别设计的高斯核或最小极大学习策略,也没有重建损失。
三、方法学
考虑一个长度为T的多元时间序列:
X
=
(
x
1
,
x
2
,
…
,
x
T
)
,
\mathcal{X}=(x_1,x_2,\ldots,x_T),
X=(x1,x2,…,xT),
其中每个数据点
x
t
∈
R
d
x_t\in\mathbb{R}^d
xt∈Rd是在某一时间戳
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

