
热门标签
热门文章
- 1蓝桥杯刷题--python-36
- 2探究 Android 调用软键盘搜索,setOnKeyListener 事件执行两次_editview.setonkeylistener(new onkeylistener() {}
- 3使用python查询Elasticsearch并导出所有数据_python elasticsearch查询
- 4好用的Android Studio插件管理器
- 5【Leetcode】283. 移动零(Java版)_leetcode 283. 移动零 java
- 6html雪花效果_雪花html代码
- 7SpringCloud学习之路(四): SpringCloud 整合 RabbitMq(一)----RabbitMq基本原理及自动创建并监听队列_rabbitmq集成springcloud
- 8第六章 网络学习相关技巧1(最优路径梯度)_梯度路径
- 9DFS:从递归去理解深度优先搜索
- 103.配置文件-常用配置说明
当前位置: article > 正文
爬虫实战 ——百度翻译_爬虫 百度翻译
作者:盐析白兔 | 2024-04-02 15:47:40
赞
踩
爬虫 百度翻译
使用post请求:
requests.post(url,data, headers)
寻找url:
1.打开百度翻译,随便输入一段值: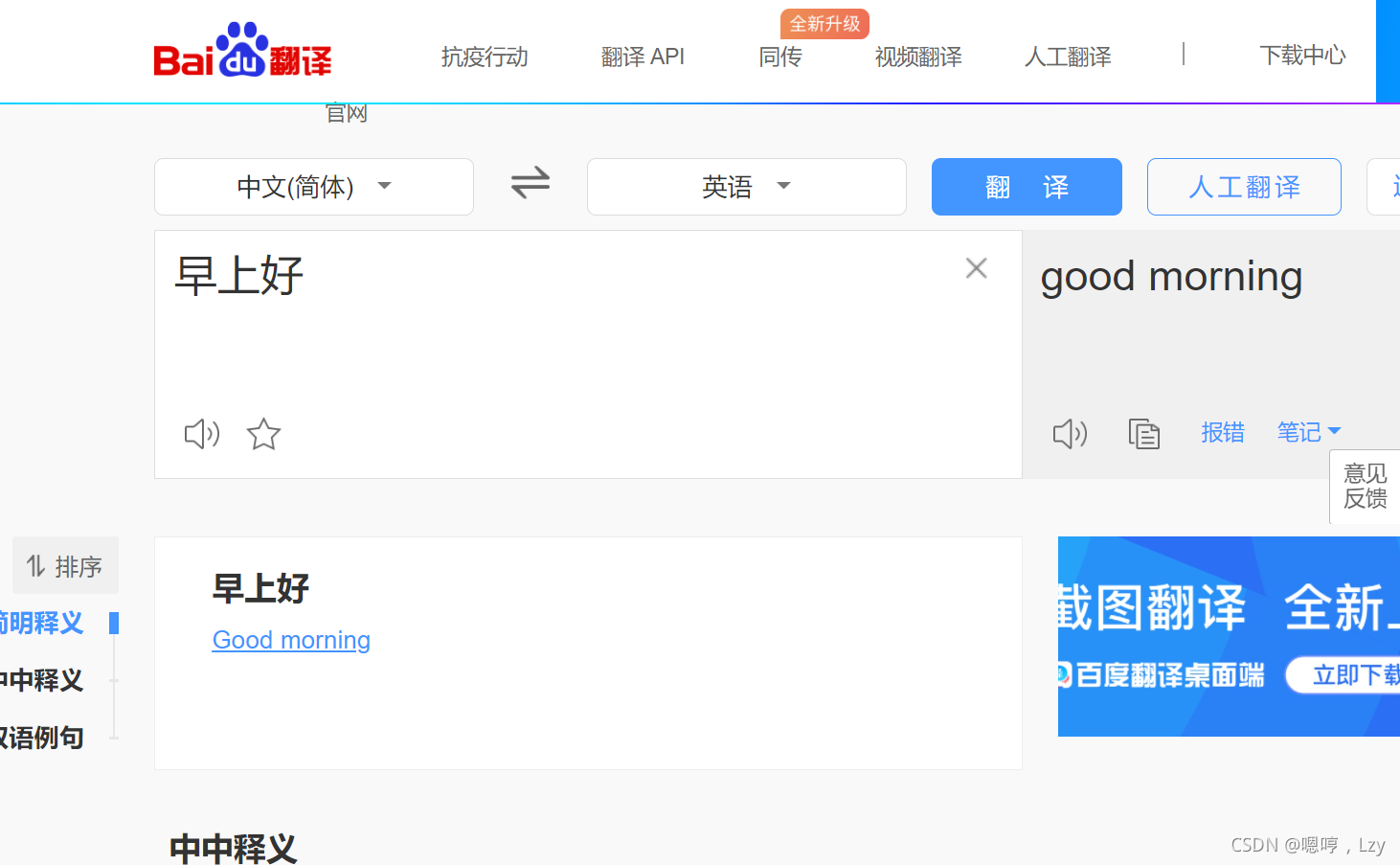
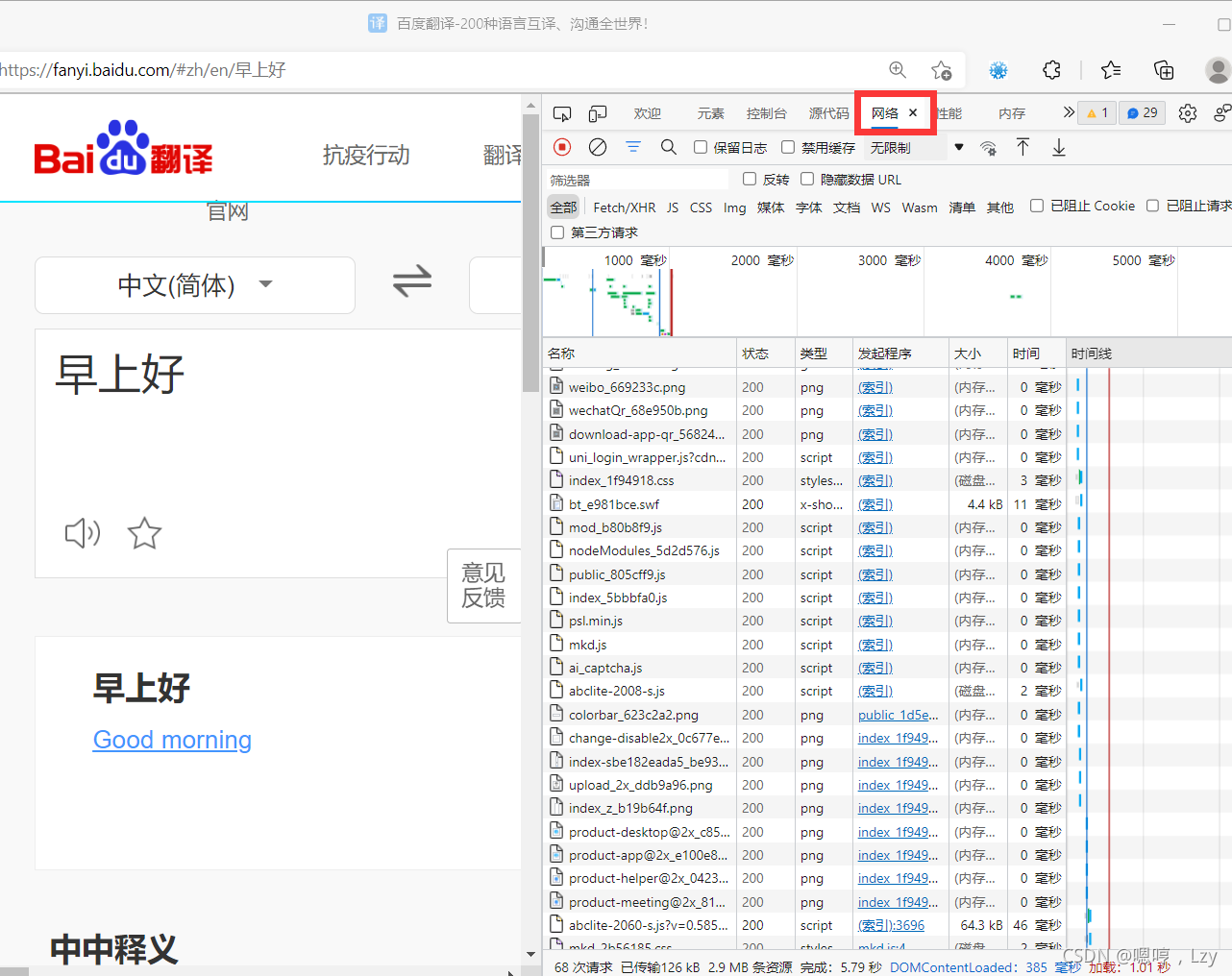
2.鼠标右击,打开检查选项,点击“网络”
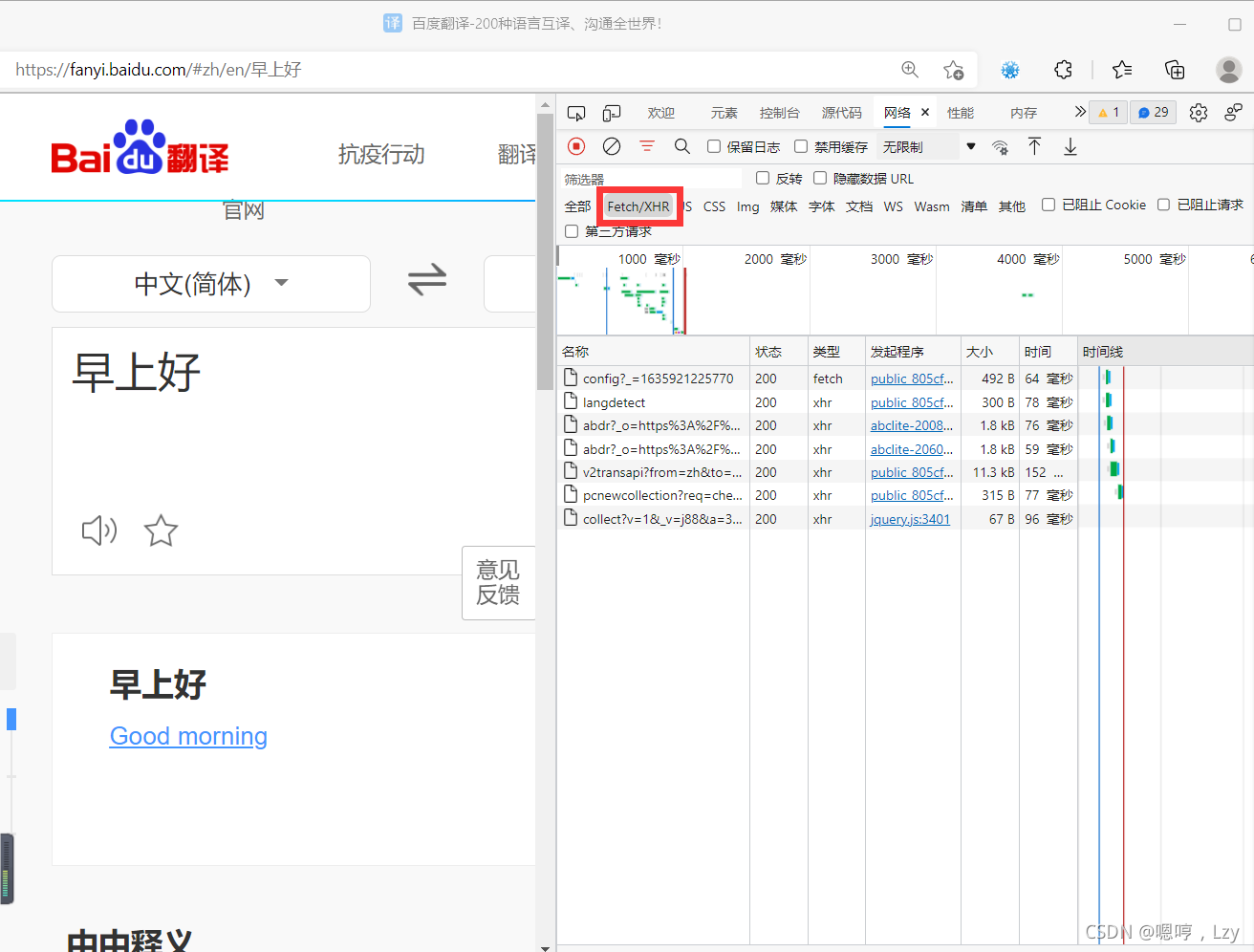
3.点击fetch/XHR
4.在翻译面板里随便输入或删除一些字,比如把“早上好”的“好”删除
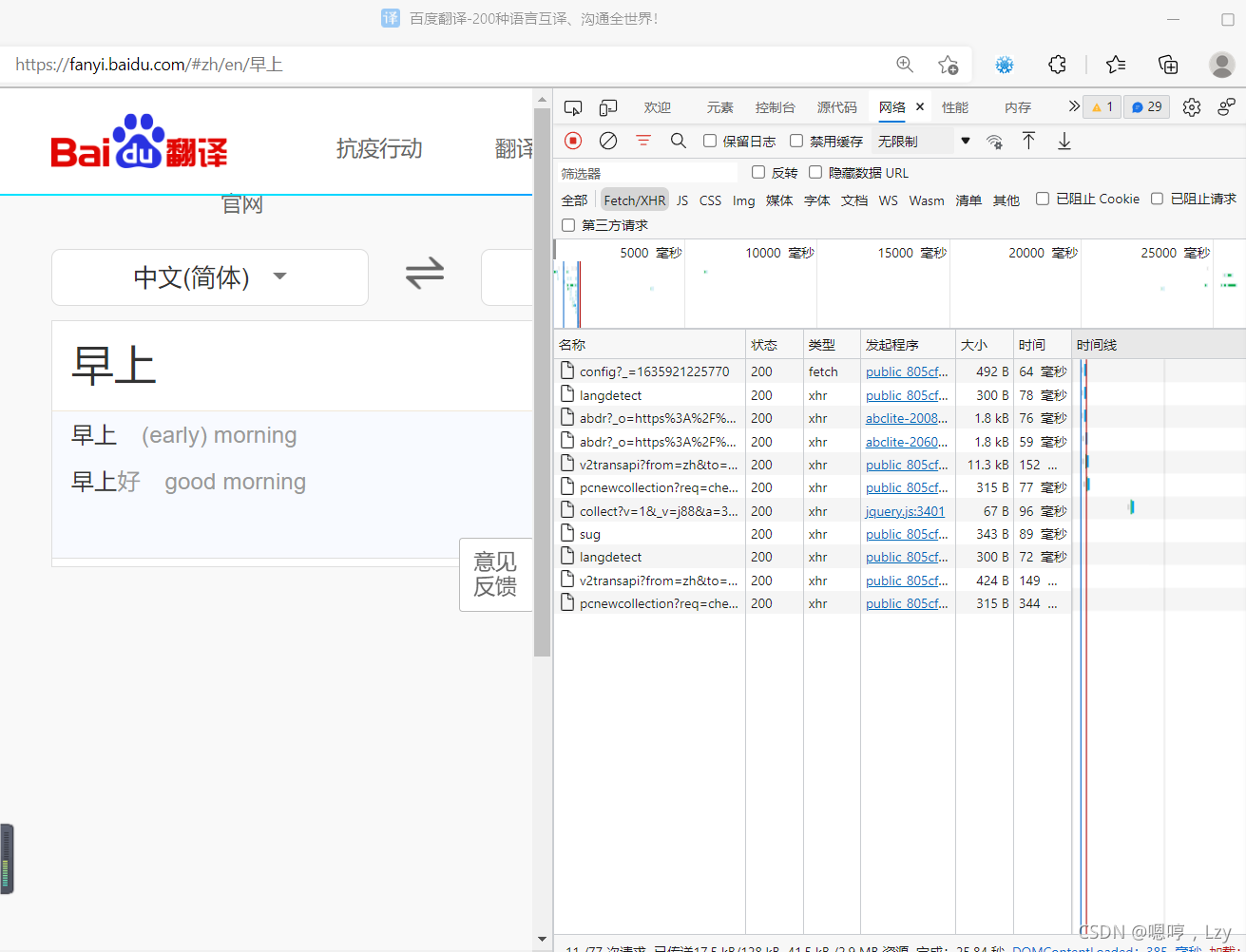
我们发现删去“好”后多出了很多新东西,比如sug
5,点击sug
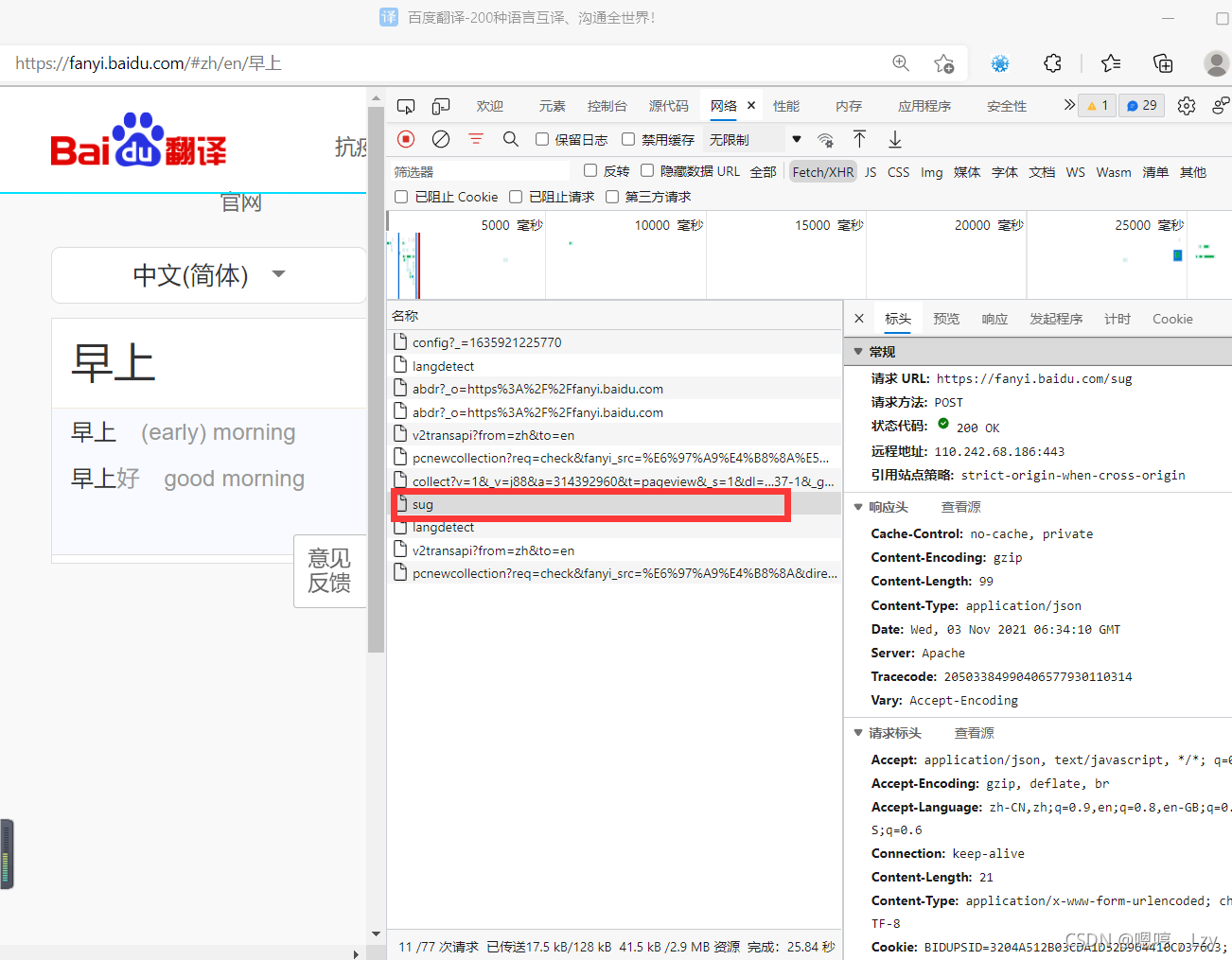
发现标头里有我们想要的URL:https://fanyi.baidu.com/sug
于是我们把url找到了
接下来开始写程序:
- # 导入工具包
- import requests
- import json
- #爬取百度翻译
- def baidu_spider(keyword:str='早上好')->str:
- """
- 根据关键字爬取百度翻译信息
- :param keyword: 需要翻译的文本
- :return: 百度翻译结果
- """
- if keyword is None:
- print("Parameter keyword should not be None!")
- return
- #1.指定链接
- url="https://fanyi.baidu.com/sug"#通过网页逆向工程得到
- #2.UA伪装
- headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'}
- #3.POST参数设置
- params={'kw':keyword}
- try:
- #4.发送请求
- r = requests.post(url=url, data=params, headers=headers)
- r.raise_for_status() # 如果状态不是200,引发HTTPError异常
- r.encoding = r.apparent_encoding # 获取并设置字符编码
- # 5.获取响应的信息
- dict_obj = r.json()
- #6.持久化存储
- fileName = keyword + '.json'
- fp = open(fileName, 'wt', encoding='utf-8')
- json.dump(dict_obj, fp=fp, ensure_ascii=False)
- fp.close()
- print("翻译结果: ", dict_obj["data"])
- except:
- print('error')
- return None
- if __name__ == "__main__":
- keyword=input("请输入需要翻译的中文:")
- baidu_spider(keyword)

看看运行结果:

嗯哼!完工!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/352898
推荐阅读
相关标签

