
热门标签
热门文章
- 1docker(容器)——跨主机网络访问(不同宿主机上的容器之间的通信)_不同主机容器之间通信 路由
- 2Android安卓进阶技巧之Kotlin结合Jetpack构建MVVM_kotlin jetpack mvvm
- 3产品读书《AI人工智能:发展简史+技术案例+商业应用》_知乎 ai产品经理相关书籍推荐
- 4开源免费CasaOS:轻松打造高效便捷的家庭云生活新体验_rk3218 安装casaos
- 5Android 系统属性(SystemProperties)介绍
- 6数据仓库之拉链表设计与实现_通过hdl生成拉链表
- 7Android如何动态改变桌面图标和label_android改变lable的内容
- 8YOLO系列(v1~v3)的学习及YOLO-Fastest在海思平台的部署(上)_yolov3需要的算力
- 9Docker 系列2【docker安装mysql】【开启远程连接】
- 10Android移动开发基础案例教程第2版课后题答案_android移动开发基础案例教程第二版答案
当前位置: article > 正文
cuda 复数矩阵求逆_矩阵求逆cuda
作者:盐析白兔 | 2024-03-16 00:00:08
赞
踩
矩阵求逆cuda
https://blog.csdn.net/kewang93/article/details/118702824?spm=1001.2014.3001.5502
这一篇为复数矩阵求逆
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- #include <ctype.h>
- #include <math.h>
-
- #include <cuda_runtime.h>
- #include <cublas_v2.h>
-
- #include <helper_cuda.h>
- //#include "batchCUBLAS.h"
-
-
- #define T_ELEM cuComplex
- #define CUBLASTEST_FAILED 1
- #define MATDEM 2
- const char *sSDKname = "batchCUBLAS";
-
-
-
- static __inline__ int imax(int x, int y)
- {
- return (x > y) ? x : y;
- }
- static __inline__ unsigned cuRand(void)
- {
- /* George Marsaglia's fast inline random number generator */
- #define CUDA_ZNEW (cuda_z=36969*(cuda_z&65535)+(cuda_z>>16))
- #define CUDA_WNEW (cuda_w=18000*(cuda_w&65535)+(cuda_w>>16))
- #define CUDA_MWC ((CUDA_ZNEW<<16)+CUDA_WNEW)
- #define CUDA_SHR3 (cuda_jsr=cuda_jsr^(cuda_jsr<<17), \
- cuda_jsr = cuda_jsr ^ (cuda_jsr >> 13), \
- cuda_jsr = cuda_jsr ^ (cuda_jsr << 5))
- #define CUDA_CONG (cuda_jcong=69069*cuda_jcong+1234567)
- #define KISS ((CUDA_MWC^CUDA_CONG)+CUDA_SHR3)
- static unsigned int cuda_z = 362436069, cuda_w = 521288629;
- static unsigned int cuda_jsr = 123456789, cuda_jcong = 380116160;
- return KISS;
- }
- #include <windows.h>
- static __inline__ double second(void)
- {
- LARGE_INTEGER t;
- static double oofreq;
- static int checkedForHighResTimer;
- static BOOL hasHighResTimer;
-
- if (!checkedForHighResTimer)
- {
- hasHighResTimer = QueryPerformanceFrequency(&t);
- oofreq = 1.0 / (double)t.QuadPart;
- checkedForHighResTimer = 1;
- }
-
- if (hasHighResTimer)
- {
- QueryPerformanceCounter(&t);
- return (double)t.QuadPart * oofreq;
- }
- else
- {
- return (double)GetTickCount() / 1000.0;
- }
- }
- struct gemmOpts
- {
- int m;
- int n;
- int k;
- //testMethod test_method;
- char *elem_type;
- int N; // number of multiplications
- };
- struct gemmTestParams
- {
- cublasOperation_t transa;
- cublasOperation_t transb;
- int m;
- int n;
- int k;
- T_ELEM alpha;
- T_ELEM beta;
- };
- #define CLEANUP() \
- do { \
- if (A) free (A); \
- if (B) free (B); \
- if (C) free (C); \
- for(int i = 0; i < opts.N; ++i) { \
- if(devPtrA[i]) cudaFree(devPtrA[i]);\
- if(devPtrB[i]) cudaFree(devPtrB[i]);\
- if(devPtrC[i]) cudaFree(devPtrC[i]);\
- } \
- if (devPtrA) free(devPtrA); \
- if (devPtrB) free(devPtrB); \
- if (devPtrC) free(devPtrC); \
- if (devPtrA_dev) cudaFree(devPtrA_dev); \
- if (devPtrB_dev) cudaFree(devPtrB_dev); \
- if (devPtrC_dev) cudaFree(devPtrC_dev); \
- fflush (stdout); \
- } while (0)
-
- void fillupMatrixDebug(T_ELEM *A, int lda, int rows, int cols)
- {
- for (int j = 0; j < cols; j++)
- {
- for (int i = 0; i < rows; i++)
- {
- A[i + lda*j].x = (i + rand()%13);
- A[i + lda*j].y = (j + rand() % 17);
- }
- }
- }
- void PrintMatrixDebug(T_ELEM *A, int lda, int rows, int cols)
- {
- printf("========The matrix is \n");
- for (int j = 0; j < cols; j++)
- {
- for (int i = 0; i < rows; i++)
- {
- printf("%+.04f%+.04fi ", A[i + lda*j].x, A[i + lda*j].y);
- //A[i + lda*j] = (i + j);
- }
- printf(" \n");
- }
- }
-
- int main(int argc, char *argv[])
- {
- printf("%s Starting...\n\n", sSDKname);
-
- int dev = findCudaDevice(argc, (const char **)argv);
-
- if (dev == -1)
- {
- return CUBLASTEST_FAILED;
- }
- cublasHandle_t handle;
-
- if (cublasCreate(&handle) != CUBLAS_STATUS_SUCCESS)
- {
- fprintf(stdout, "CUBLAS initialization failed!\n");
- exit(EXIT_FAILURE);
- }
-
- cublasStatus_t status1, status2, status3;
- T_ELEM *A = NULL;
- T_ELEM *B = NULL;
- T_ELEM *C = NULL;
- T_ELEM **devPtrA = 0;
- T_ELEM **devPtrB = 0;
- T_ELEM **devPtrC = 0;
- T_ELEM **devPtrA_dev = NULL;
- T_ELEM **devPtrB_dev = NULL;
- T_ELEM **devPtrC_dev = NULL;
-
- int matrixM, matrixN, matrixK;
- int rowsA, rowsB, rowsC;
- int colsA, colsB, colsC;
- int m, n, k;
- int matrixSizeA, matrixSizeB, matrixSizeC;
- int errors;
- double start, stop;
- gemmOpts opts;
- opts.N = 20;
- gemmTestParams params;
-
-
-
-
- printf("Testing Batch INV Cublas\n");
-
- matrixM = MATDEM;
- matrixN = MATDEM;
- matrixK = MATDEM;
-
- int * info;//用于记录LU分解是否成功
- int * pivo;//用于记录LU分解的信息
- cudaMalloc((void **)& info, sizeof(int)* opts.N);
- cudaMalloc((void **)& pivo, sizeof(int)* matrixM * opts.N);
-
- rowsA = imax(1, matrixM);
- colsA = imax(1, matrixK);
- rowsB = imax(1, matrixK);
- colsB = imax(1, matrixN);
- rowsC = imax(1, matrixM);
- colsC = imax(1, matrixN);
-
- matrixSizeA = rowsA * colsA;
- matrixSizeB = rowsB * colsB;
- matrixSizeC = rowsC * colsC;
-
- params.transa = CUBLAS_OP_N;
- params.transb = CUBLAS_OP_N;
- m = matrixM;
- n = matrixN;
- k = matrixK;
- params.m = m;
- params.n = n;
- params.k = k;
- params.alpha.x = 1.0; params.alpha.y = 0.0;
- params.beta.x = 0.0; params.beta.y = 0.0;
-
- devPtrA = (T_ELEM **)malloc(opts.N * sizeof(T_ELEM *));
- devPtrB = (T_ELEM **)malloc(opts.N * sizeof(*devPtrB));
- devPtrC = (T_ELEM **)malloc(opts.N * sizeof(*devPtrC));
-
- for (int i = 0; i < opts.N; i++)
- {
- cudaError_t err1 = cudaMalloc((void **)&devPtrA[i], matrixSizeA * sizeof(T_ELEM ));
- cudaError_t err2 = cudaMalloc((void **)&devPtrB[i], matrixSizeB * sizeof(devPtrB[0][0]));
- cudaError_t err3 = cudaMalloc((void **)&devPtrC[i], matrixSizeC * sizeof(devPtrC[0][0]));
-
-
- }
- // For batched processing we need those arrays on the device
-
- cudaError_t err1 = cudaMalloc((void **)&devPtrA_dev, opts.N * sizeof(*devPtrA));
- cudaError_t err2 = cudaMalloc((void **)&devPtrB_dev, opts.N * sizeof(*devPtrB));
- cudaError_t err3 = cudaMalloc((void **)&devPtrC_dev, opts.N * sizeof(*devPtrC));
-
-
-
- err1 = cudaMemcpy(devPtrA_dev, devPtrA, opts.N * sizeof(*devPtrA), cudaMemcpyHostToDevice);
- err2 = cudaMemcpy(devPtrB_dev, devPtrB, opts.N * sizeof(*devPtrB), cudaMemcpyHostToDevice);
- err3 = cudaMemcpy(devPtrC_dev, devPtrC, opts.N * sizeof(*devPtrC), cudaMemcpyHostToDevice);
-
- A = (T_ELEM *)malloc(matrixSizeA * sizeof(A[0]));
- B = (T_ELEM *)malloc(matrixSizeB * sizeof(B[0]));
- C = (T_ELEM *)malloc(matrixSizeC * sizeof(C[0]));
-
- printf("#### args: lda=%d ldb=%d ldc=%d\n", rowsA, rowsB, rowsC);
- m = cuRand() % matrixM;
- n = cuRand() % matrixN;
- k = cuRand() % matrixK;
- memset(A, 0xFF, matrixSizeA* sizeof(A[0]));
- fillupMatrixDebug(A, rowsA, rowsA, rowsA);
- memset(B, 0xFF, matrixSizeB* sizeof(B[0]));
- fillupMatrixDebug(B, rowsB, rowsA, rowsA);
-
- for (int i = 0; i < opts.N; i++)
- {
- status1 = cublasSetMatrix(rowsA, colsA, sizeof(A[0]), A, rowsA, devPtrA[i], rowsA);
- status2 = cublasSetMatrix(rowsB, colsB, sizeof(B[0]), B, rowsB, devPtrB[i], rowsB);
- status3 = cublasSetMatrix(rowsC, colsC, sizeof(C[0]), C, rowsC, devPtrC[i], rowsC);
-
- }
- start = second();
-
- status1 = cublasCgemmBatched(handle, params.transa, params.transb, params.m, params.n,
- params.k, ¶ms.alpha, (const T_ELEM **)devPtrA_dev, rowsA,
- (const T_ELEM **)devPtrB_dev, rowsB, ¶ms.beta, devPtrC_dev, rowsC, opts.N);
-
- cublasCgetrfBatched(handle, params.m, devPtrA_dev, params.m, pivo, info, opts.N);//第四个参数是矩阵的主导维,由于这里假设数据在内存中的存放是连续的,所以是size
-
- cublasCgetriBatched(handle, params.m, devPtrA_dev, params.m, pivo, devPtrC_dev, params.m, info, opts.N);
-
- //cublasCgetrfBatched(cublasHandle_t handle,
- // int n,
- // cuComplex *Aarray[],
- // int lda,
- // int *PivotArray,
- // int *infoArray,
- // int batchSize);
-
-
- //cudaMemcpy(devPtrC_dev, devPtrC, opts.N * sizeof(*devPtrC), cudaMemcpyHostToDevice);
-
- for (int i = 0; i < opts.N; i++)
- {
- //status1 = cublasSetMatrix(rowsA, colsA, sizeof(A[0]), A, rowsA, devPtrA[i], rowsA);
- //status2 = cublasSetMatrix(rowsB, colsB, sizeof(B[0]), B, rowsB, devPtrB[i], rowsB);
- status3 = cublasGetMatrix(rowsC, colsC, sizeof(C[0]), devPtrC[i], rowsC, C, rowsC);
-
- }
-
- PrintMatrixDebug(A, params.m, params.n, params.k);
- PrintMatrixDebug(B, params.m, params.n, params.k);
- PrintMatrixDebug(C, params.m, params.n, params.k);
-
- stop = second();
- fprintf(stdout, "^^^^ elapsed = %10.8f sec \n", (stop - start));
-
-
-
-
- CLEANUP();
- cublasDestroy(handle);
- printf("\nTest Summary\n");
- system("pause");
- return 0;
-
- }

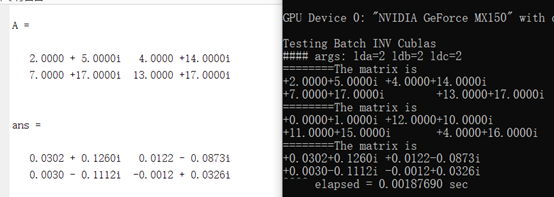
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/245562
推荐阅读
相关标签

