Flink-提交job_flink job
赞
踩
目录
一、Flink 流处理扩展及说明
涉及:自定义线程优先级
=socket流中读取数据并行度只能是 1
1、特定的算子设定了并行度最优先
2、算子没有设定并行度就是用整体运行环境设置的并行度
3、环境的并行度没有设置就使用提交时候提交参数设置的并行度
4、都没有设置就遵循 flink的配置文件
增加:
1、自定义线程
2、从外部命令中提取参数
- package com.atguigu.wc
-
- import org.apache.flink.api.java.utils.ParameterTool
- import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
- import org.apache.flink.streaming.api.scala._
-
- object StreamWordCount_02 {
- def main(args: Array[String]): Unit = {
-
- //创建流处理的执行环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
-
- //env.setParallelism(8) //自定义线程,设置几就有几个线程
-
- //从外部命令中提取参数,作为socket主机名和端口号
- val paramTool:ParameterTool = ParameterTool.fromArgs(args)
- val host:String = paramTool.get("host")
- val port:Int = paramTool.getInt("port")
-
- //接收一个socket文本流
- val inputDataStream:DataStream[String] = env.socketTextStream(host,port)
-
- //进行转化处理统计
- val resultDataStream:DataStream[(String,Int)] = inputDataStream
- .flatMap(_.split(" "))
- .filter(_.nonEmpty)
- .map((_,1))
- .keyBy(0)
- .sum(1)
-
- resultDataStream.print().setParallelism(1) //自定义线程为1;所以线程是一致的,并行度
-
- //启动任务执行
- env.execute("stream word count")
-
-
-
-
-
-
- }
- }

二、Flink部署
三、Standalone模式
首先:安装
1、将文件flink-1.10.1-bin-scala_2.12.tgz上传到software目录下
2、解压缩flink-1.10.1-bin-scala_2.12.tgz到module
解压缩命令:tar -zxvf -C flink-1.10.1-bin-scala_2.12.tgz /opt/module/
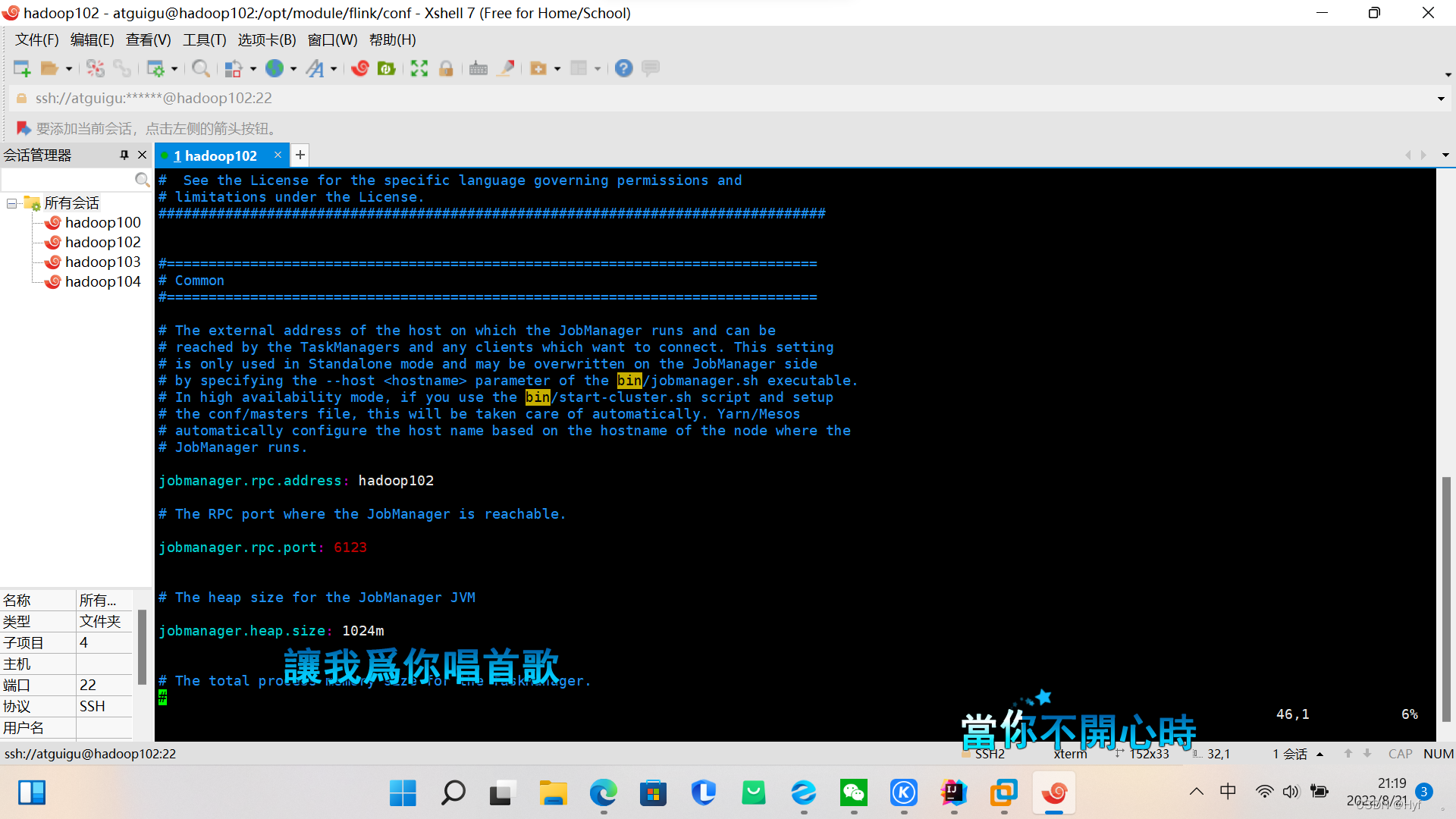
3、在conf目录下修改flink-conf.yaml文件
[atguigu@hadoop102 conf]$ vi flink-conf.yaml修改内容如下:
jobmanager.rpc.address:hadoop102
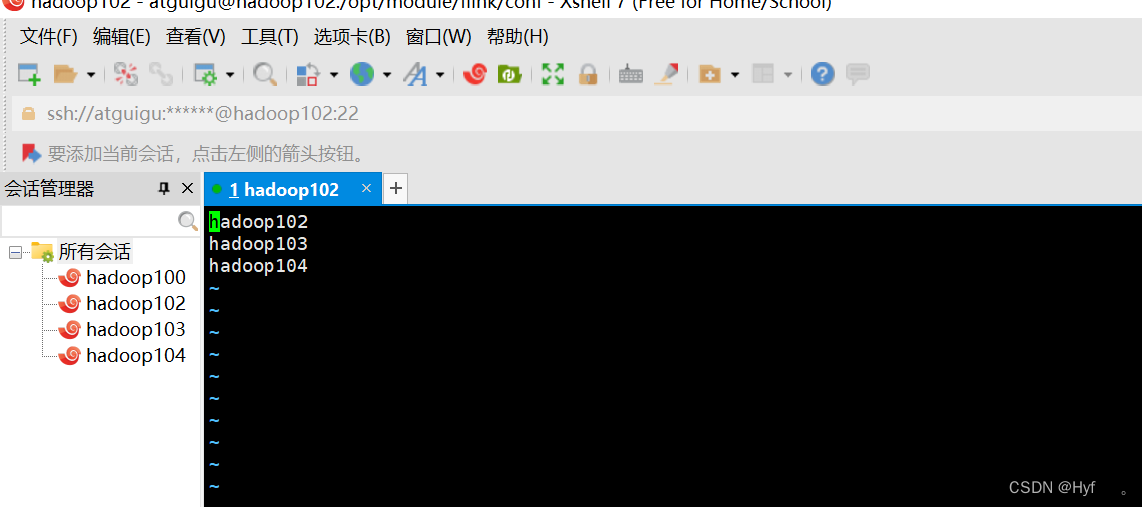
4、在conf目录下修改slaves文件
修改内容如下:
hadoop102
hadoop103
hadoop104
5、使用xsync命令分发flink文件
[atguigu@hadoop102 module]$ xsync flink-1.10.0 6、启动flink
在bin目录下启动flink
[atguigu@hadoop102 bin]$ ./start-cluster.sh关闭flink命令
[atguigu@hadoop102 bin]$ ./stop-cluster.sh
访问以下网址对flink集群和任务进行监控管理
新建标签页 http://hadoop102:8081/在命令行提交job
http://hadoop102:8081/在命令行提交job
如果没有安装netcat则需要安装
命令:yum install -y nc
1、首先需要打包jar
Maven》生命周期》package
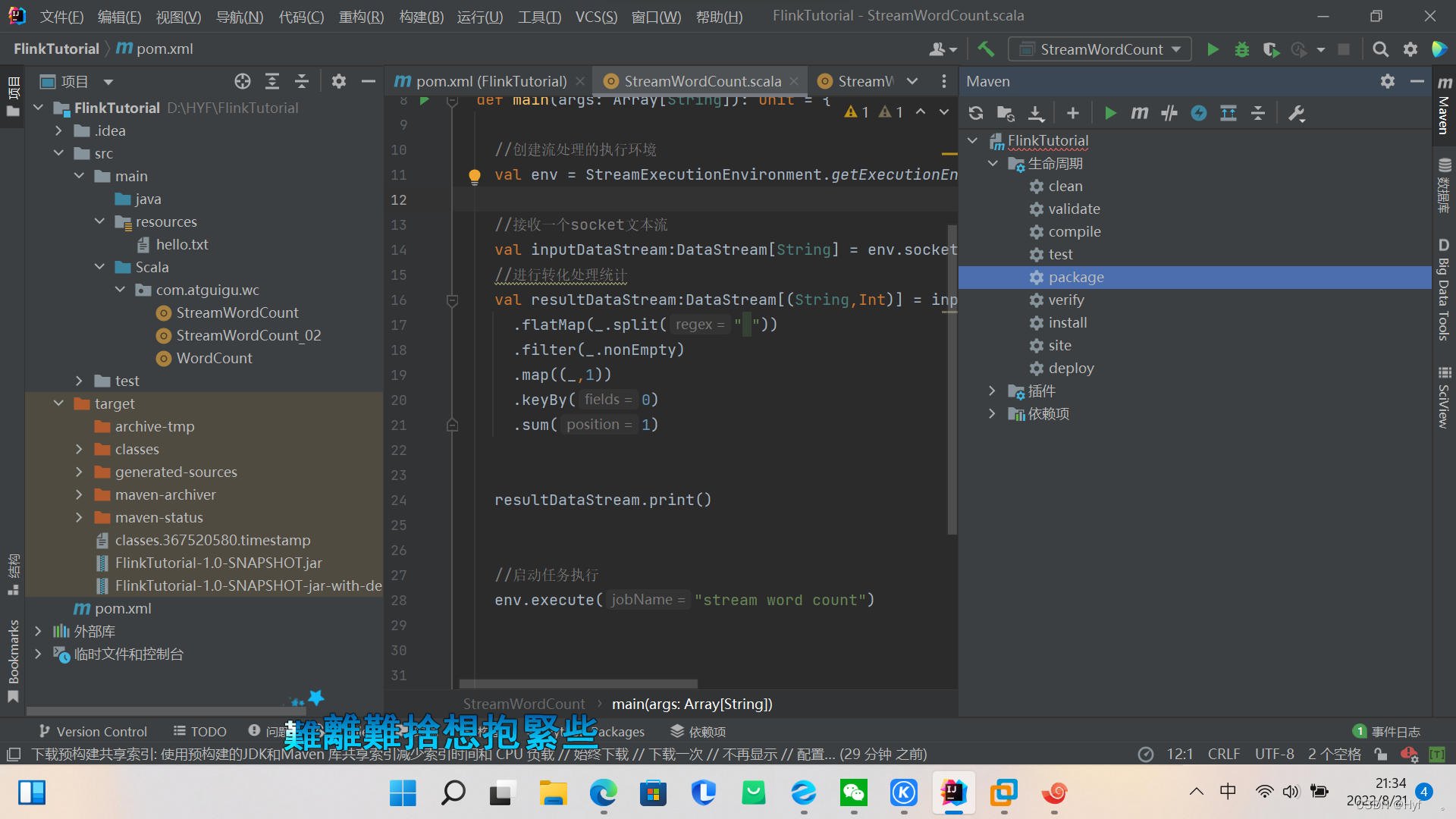
在target目录下可以查看到打包好的文件,或者在本机上也可以查看
在flink文件下创建一个目录data
将打包好的文件FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar上传到flink下的data文件
[atguigu@hadoop102 flink]$ mkdir data 
四、在命令行提交job:
前提要先启动flink
[atguigu@hadoop102 bin]$ ./flink sun -c com.atguigu.wc.StreamWordCount -p 2 ../data/FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host hadoop102 --port 7777参数解析:
-c :指定main方法的全类名
-p : 并行度
--host hadoop102 --port 7777 :外部设置的参数
3、打开一个新页面,打开netcat
命令:yum install -y nc
4、在网页中即可查看到正在运行的job
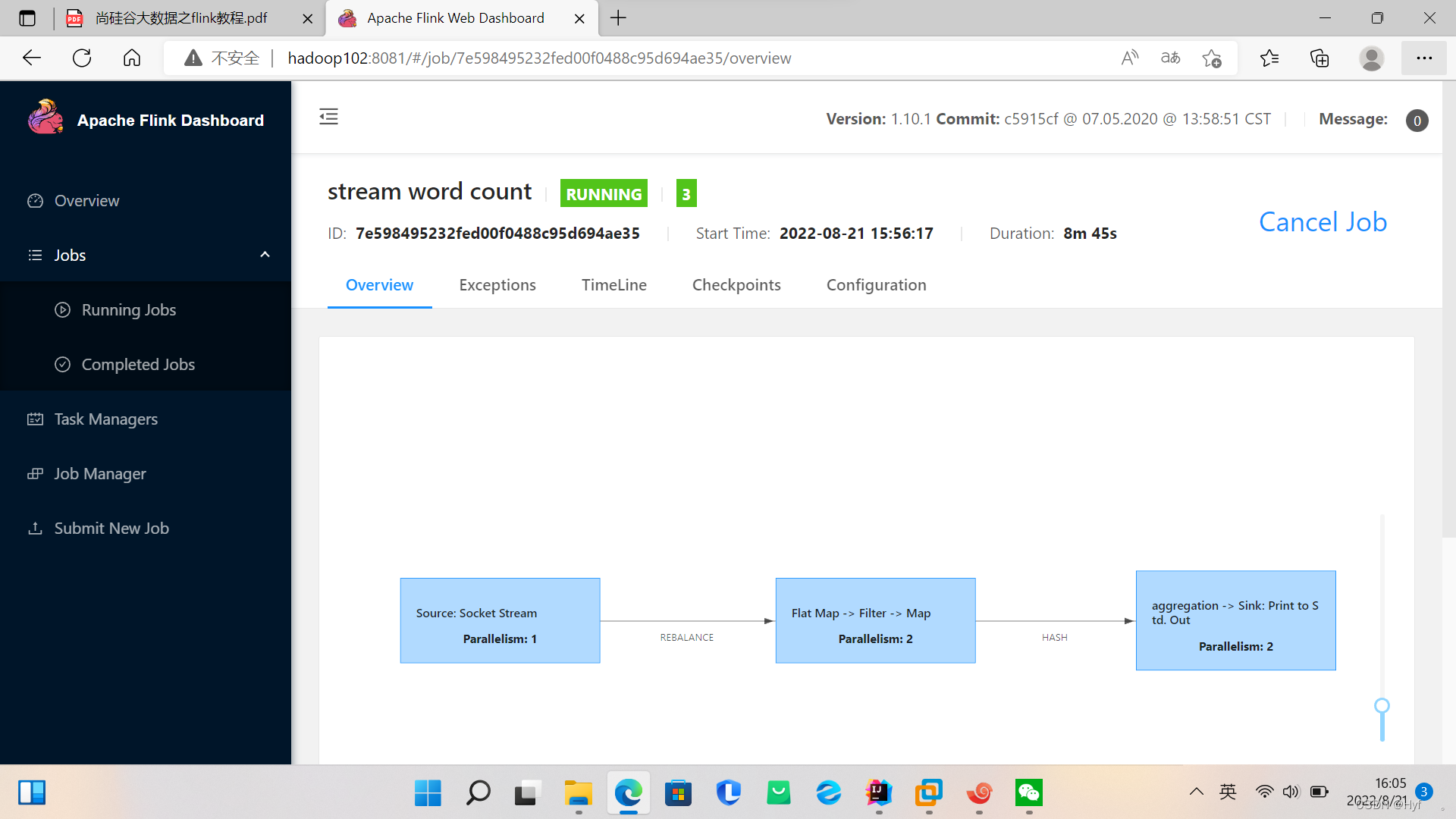
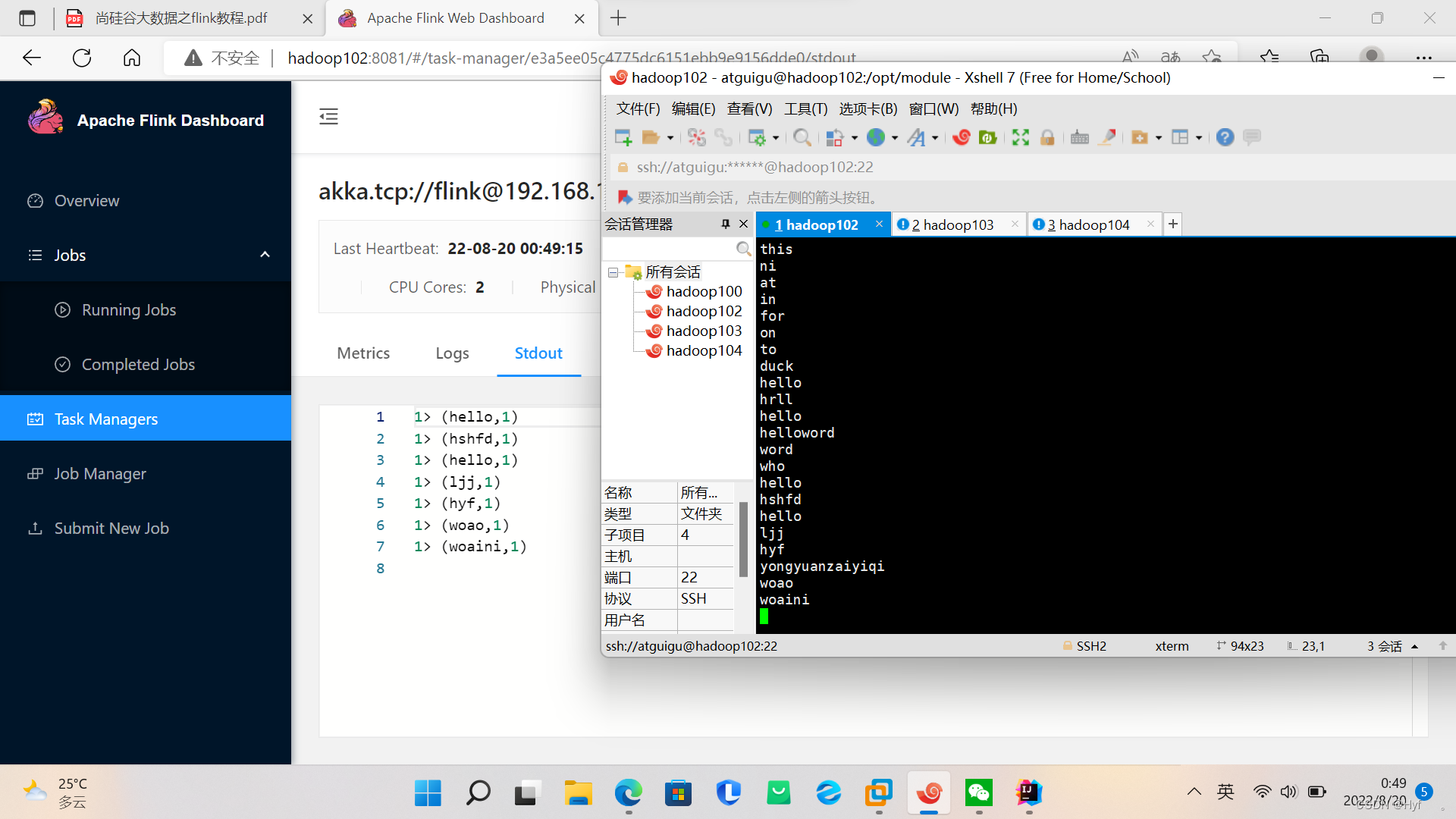
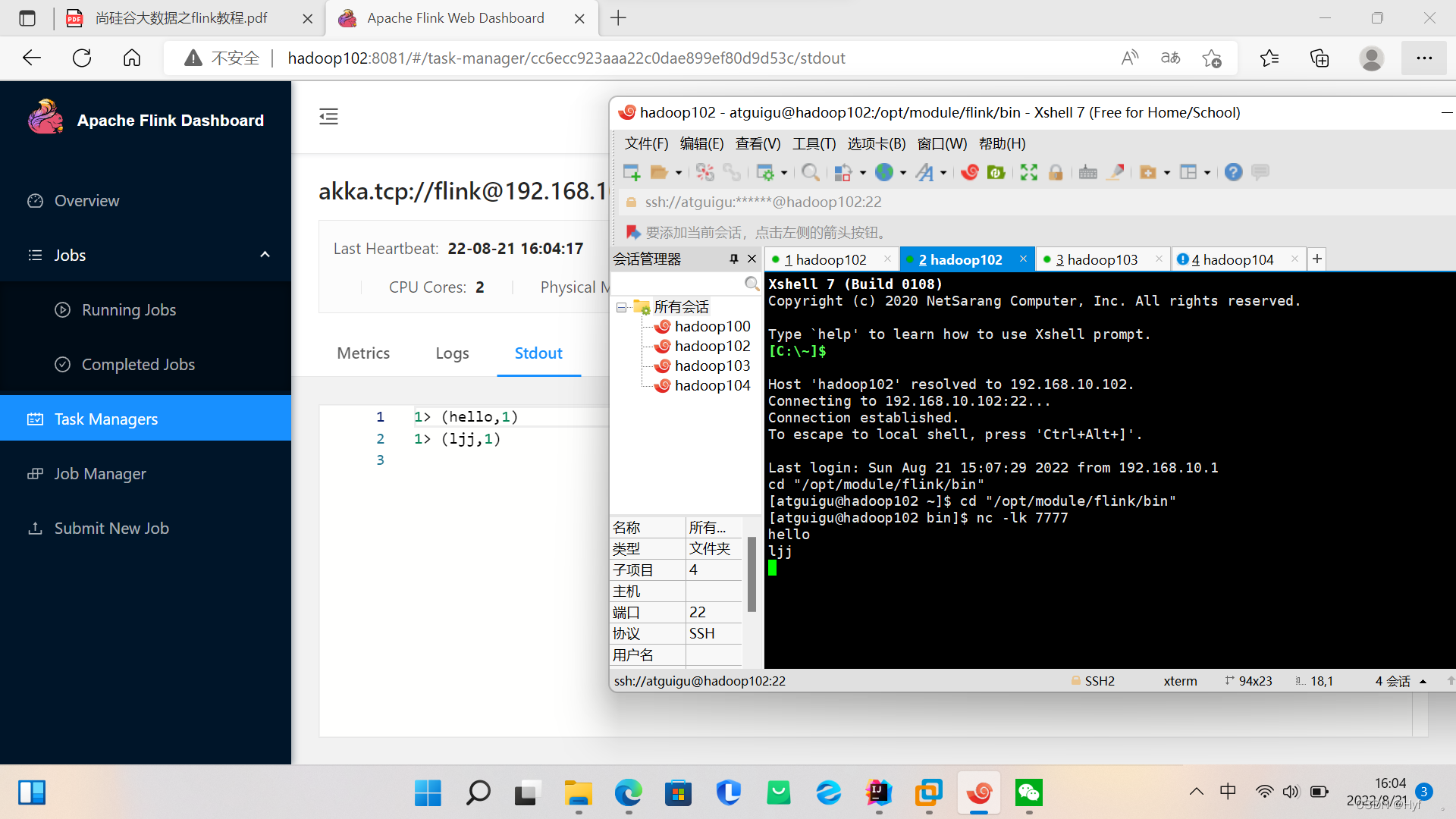
可以在命令行上上传数据,在Task Managers》点击运行的集群》Stdout上查看任务运行
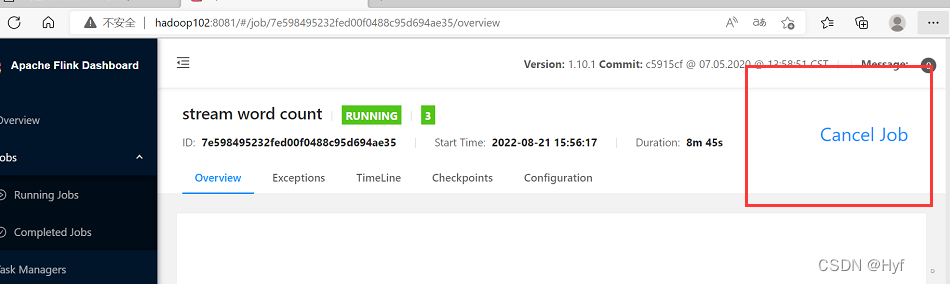
5、取消job(需要的话可以)
第一种方法:在网页中取消
第二种方法:在命令行取消
[atguigu@hadoop102 bin]$ ./flink cancel + 你的job idid获取方法:
第一种:在网页中获取
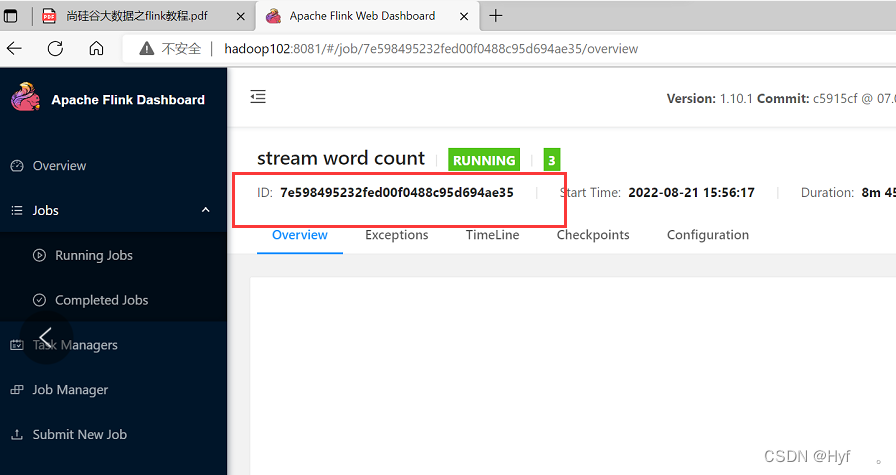
第二种:在命令行输入命令
在bin目录下 ./flink list -a 即可查看提交的job id
第三种:在提交的命令行中也可以获取
查看所有运行或者重启中的flink job
命令: . /flink list

五、在网页中提交flink job
首先需要打包好jar》进入网页》Submit New Job》Add New》选择上传的jar》单击选择的作业》配置对应参数
参数解读:
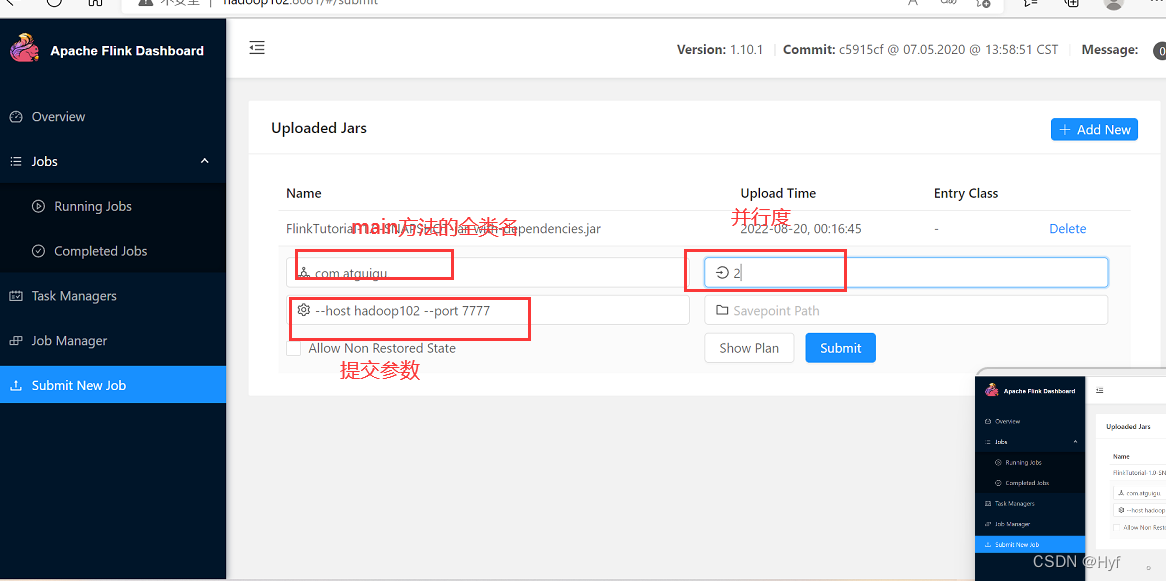
可show plan 查看
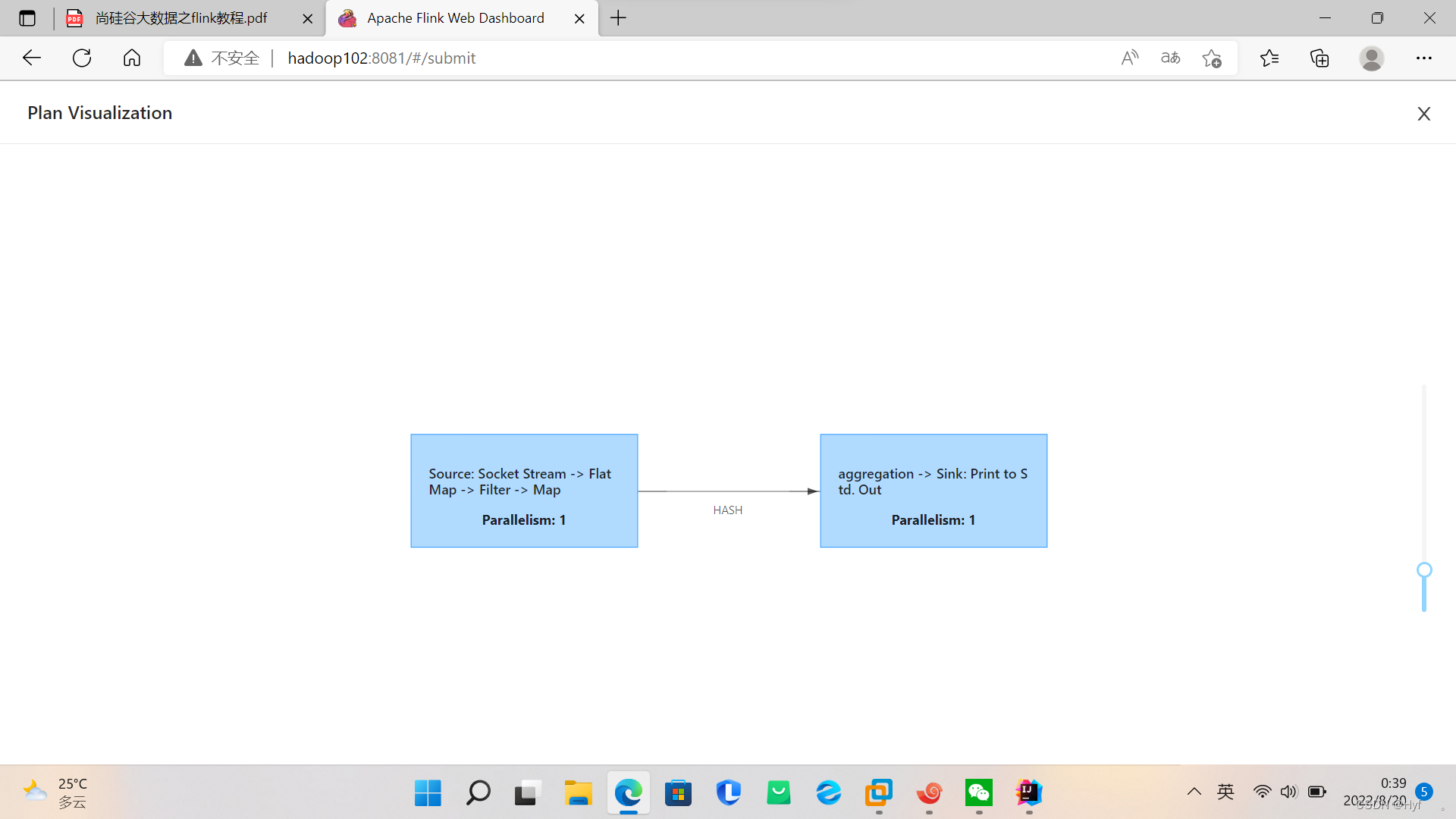
最后点击submit提交job即可
测试:
可以 在命令行输入数据。在网页上面查看 在Task Managers》点击运行的集群》Stdout上查看任务运行